
1. Coletando informações na internet
O desenvolvimento da habilidade de construir um extrator autônomo de dados é realizada no curso Data Mining Judicial. Porém, você já é capaz de buscar informações se você baixar o arquivo dsd.py e salvá-lo no seu diretório de trabalho, o que permitirá que você utilize as funções contidas neste módulo.
No texto Funções e Módulos, você já aprendeu a instalar o módulo dsd.py e a utilizar a função dsd.extrair(). Agora precisamos buscar informações para que você exercite essa habilidade com dados reais. Você aprenderá a criar programas que coletam dados no Data Mining Judicial e para isso precisará aprender melhor sobre requisições de dados. Por enquanto, vamos usar uma função simples, que operacionaliza a busca de dados no site do STF: a dsd.get().
Para usar essa função, é preciso importar o módulo dsd.py e usar a dsd.get() tendo como parâmetro o endereço relativo a um processo. Experimente rodar no seu console o seguinte código:
import dsd # importação do módulo dsd
dados = dsd.get('http://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADPF&documento=&s1=666&numProcesso=666')
print (dados)Esse é um código que funciona e imprime na sua tela o conteúdo que o servidor do STF envia ao seu computador quando você consulta a ADPF 666 na página do controle concentrado (ADI, ADC, ADO e ADPF).
Note que a linha 3 fica muito grande, forçando você a utilizar a barra inferior para ver todo o conteúdo. Para resolver o primeiro ponto, vamos reescrever o código, usando uma concatenação, que você já conhece. Com isso, todo o programa poderá aparecer na tela. Chamamos isso tipicamente de "wrap", uma quebra usada para tornar visível o texto em uma tela estreita.
import dsd # importação do módulo dsd
# busca os dados do endereço definido
dados = dsd.get('http://portal.stf.jus.br/' +
'peticaoInicial/verPeticaoInicial.asp' +
'?base=ADPF&documento=&s1=666&numProcesso=666')
print (dados)2. Leitura preliminar do código-fonte
2.1 O código-fonte
A impressão do conteúdo da variável dados gera uma string muito grande, de modo que o console somente mostrará o final dessa cadeia. Se você for subindo, verá que uma parte significativa da string é formada por caracteres que não formam textos muito compreensíveis.
Isso acontece porque, nessas informações enviadas pelo servidor do STF, estão contidos os dados referentes à ADI 666, mas também estão as informações de formatação que permitem exibir os vários elementos contidos no cabeçalho e no rodapé da página que você pode consultar abrindo no seu navegador o link utilizado no programa, que te levará a uma página muito mais limpa, no qual todos os códigos de formatação terão sido processados e você visualizará apenas os conteúdos da página.
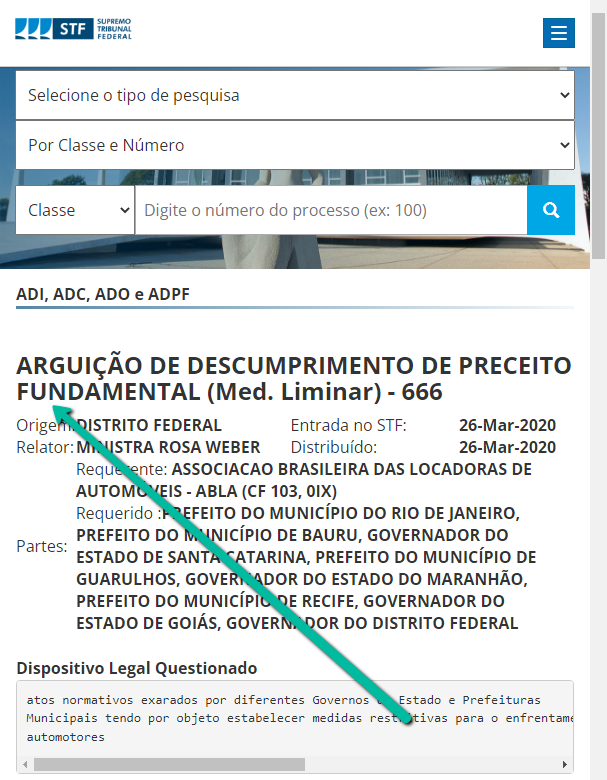
Essa visualização dos textos contidos na tela do seu navegador é uma interpretação feita dos dados enviados pelo STF, que constituem o que chamamos de código-fonte, que é a string que você obteve por meio da função dsd.get().
Na sequência do curso de Data Mining Judicial, você aprenderá melhor sobre códigos e endereços, para poder construir um extrator de dados eficiente. Todavia, você já tem instrumentos para fazer uma leitura básica do código fonte e para utilizar a função dsd.extrair(), com o objetivo de localizar e extrair algumas informações relevantes do texto.
A observação do código-fonte interpretado pelo navegador é mais fácil e nos permite identificar que a primeira informação relevante para nossas pesquisas é justamente o nome da ação, indicado na imagem acima pela seta verde.
Identificar esse ponto é relevante porque nos permite localizá-lo dentro do código-fonte, por meio de um comando Ctrl-F, realizado dentro do console. Se você buscar, no console, o texto "ARGUIÇÃO", você será levado a uma parte do código-fonte que tem as seguintes informações:
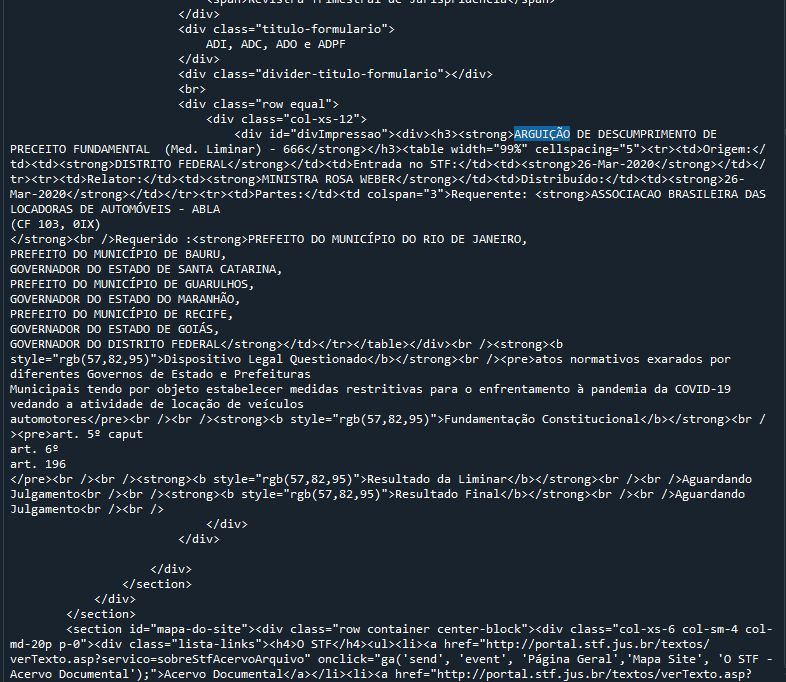
Observando com cuidado, você verá que todo o conteúdo relevante sobre a ADPF 666 está nesse trecho do código-fonte.
2.2 Concentrando a análise nos dados relevantes
Para excluir da variável dados todos os elementos que são apenas de formatação, e não interessam para nossos trabalhos de análise, você pode utilizar a função dsd.extrair(), precisando apenas identificar adequados marcadores de início e de fim.
É sempre útil usar como marcador um trecho que está entre <>, pois esses elementos tendem a ocorrer em todas as páginas que seguem o modelo da que você está analisando (neste caso, as páginas das outras ADPFs). O que te interessa é identificar trechos que ocorrem somente uma vez dentro do código-fonte, ou ao menos que tenham a primeira ocorrência exatamente no local que você pretende fazer o corte.
Observando o trecho acima, há dois candidatos óbvios, especialmente porque as páginas tendem a ter apenas um título:
- <div class="titulo-formulario">
- <div class="divider-titulo-formulario">
Se você usar um Ctrl-F, verificará que ambos os trechos têm apenas uma ocorrência e que, por isso, qualquer deles serve como um bom marcador de início.
Para marcador de fim, você notará que logo depois do último conteúdo, aparecem alguns elementos que são repetitivos (</div> e </section>), que são marcadores do fim de certos blocos de formatação. Logo depois, aparece um trecho que inicia uma nova sessão, com um id bastante particular, e que por isso se torna um marcador potencialmente único:
- <section id="mapa-do-site">
Mapa do site é uma região específica da página, que fica normalmente no rodapé e tem links para outras páginas contidas no domínio. No caso do STF, as páginas costumam ter o seguinte mapa:
Por esse motivo, o trecho que indica o início da seção mapa do site é potencialmente útil como marcador, o que se confirma em uma busca por esse texto, que ocorre apenas nesse ponto exato do código-fonte.
Assim, podemos refinar um pouco nosso programa básico de extração:
import dsd # importação do módulo dsd
# busca os dados do endereço definido
dados = dsd.get('http://portal.stf.jus.br/' +
'peticaoInicial/verPeticaoInicial.asp' +
'?base=ADPF&documento=&s1=666&numProcesso=666')
# retorna apenas o trecho relevante do código-fonte
dados = dsd.extrair(dados,'<div class="divider-titulo-formulario">','<section id="mapa-do-site">')
print (dados)Esse uso do dsd.extrair() permite que você tenha um trecho de código mais manejável e possa buscar nele as informações úteis, bem como os marcadores de início e de fim que permitam extraí-las.
Antes de seguir, vamos dar mais um passo, que é diferenciar a string contida na variável dados do código-fonte, que é uma exibição legível do HTML, em que não há apenas uma sequência de caracteres, mas também quebras de linha e tabulações, que facilitam a leitura do texto. Para visualizar o conteúdo exato dessa variável, não digite print (dados) no console, mas digite apenas dados.
O resultado será um texto não converte símbolos de linha (\r ou \n) e de tabulação (\r), mas que mostra todos os elementos que compõem efetivamente a string com a qual você trabalha:
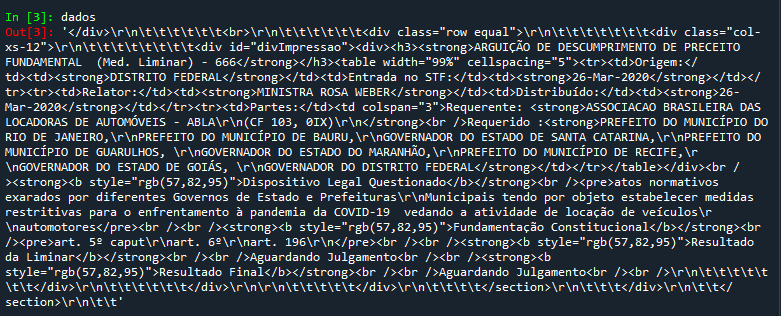
Agora sim você terminou o caminho que vai da exibição contida no navegador, passando pela exibição do código-fonte, até os valores mais brutos (e menos legíveis), contidos na string que o Python efetivamente manipula. É justamente nesse nível mais básico de análise que você deve definir os marcadores de início e de fim, pois esses são os dados que serão efetivamente processados por seu programa.
Por esse motivo, na definição de marcadores, devemos evitar a utilização de trechos que contêm tabulações e quebras de linha, pois os respectivos símbolos não são mostrados quando você visualiza o código-fonte.
3. Coleta das informações
3.1 Extraindo os dados
Comecemos pela extração do nome da ação e do relator.
Importante: não é necessário que os marcadores sejam trechos únicos na string, pois o dsd.extrair() localiza apenas a primeira ocorrência de um texto. Assim, o crucial é que os marcadores de início sejam a primeira ocorrência do trecho na cadeia analisada, e que os marcadores de fim sejam a primeira ocorrência do trecho logo após os marcadores de início.
Busque na string dados (ou no código-fonte, tomados os devidos cuidados) marcadores adequados para esses elementos e teste-os para avaliar se eles chegam aos mesmos resultados oferecidos pelo programa abaixo, ainda que os marcadores não sejam exatamente iguais (pois há sempre várias formas fazer uma mesma extração).
import dsd # importação do módulo dsd
# busca os dados do endereço definido
dados = dsd.get('http://portal.stf.jus.br/' +
'peticaoInicial/verPeticaoInicial.asp' +
'?base=ADPF&documento=&s1=666&numProcesso=666')
# retorna apenas o trecho relevante do código-fonte
dados = dsd.extrair(dados,
'<div class="divider-titulo-formulario">',
'<section id="mapa-do-site">')
# extrai nome da acao
acao = dsd.extrair(dados,
'<div id="divImpressao"><div><h3><strong>',
'</strong>')
# extrai relator
relator = dsd.extrair(dados,
'Relator:</td><td><strong>',
'</strong>')
# extrai relator
requerente = dsd.extrair(dados,
'Requerente: <strong>',
'\r\n')
print ([acao, relator, requerente])Note que o que imprimimos não foi uma sequência de informações, mas uma lista composta pelas 3 informações extraídas. Essa consolidação dos dados extraídos em listas é importante porque é a base para podermos construir tabelas com os dados de um conjunto de processos.
Agora que você tem um programa de extração de um determinado processo, podemos utilizar o que você aprendeu sobre iteração para construir um algoritmo capaz de extrair os dados das ADPFs 600 a 610. Você já aprendeu a gerar uma sequência de endereços, usando o for. Agora é combinar o algoritmo de extração com o algoritmo de iteração, realizando uma extração iterada.
import dsd # importação do módulo dsd
inicio = 600
fim = 610
for n in range(fim-inicio+1):
numProcesso = str(inicio+n)
# busca os dados do endereço definido
dados = dsd.get('http://portal.stf.jus.br/' +
'peticaoInicial/verPeticaoInicial.asp' +
'?base=ADPF&documento=&s1=666&numProcesso=' + numProcesso)
# retorna apenas o trecho relevante do código-fonte
dados = dsd.extrair(dados,
'<div class="divider-titulo-formulario">',
'<section id="mapa-do-site">')
# extrai nome da acao
acao = dsd.extrair(dados,
'<div id="divImpressao"><div><h3><strong>',
'</strong>')
# extrai relator
relator = dsd.extrair(dados,
'Relator:</td><td><strong>',
'</strong>')
print ([acao, relator])3.2 Processando as informações
Agora que você consegue extrair informações, vamos nos concentrar em trabalhar esses dados para que a sua análise seja mais fácil.
Um primeiro passo é usar a função replace(), que você já conhece, para tornar os dados mais legíveis.
- Na variável acao (lembre-se que o nome das variáveis precisam conter apenas os caracteres mais básicos, o que exclui cedilha e acentos), você pode trocar o nome completo "ARGUIÇÃO DE DESCUMPRIMENTO DE PRECEITO FUNDAMENTAL" por "ADPF" e excluir o '(Med. Liminar) ';
- Na variável relator, você pode excluir o implícito "MINISTRO";
Além disso, você pode usar a função split() para segmentar a variável acao em duas novas variáveis, classe e numero, que estão separados pelo trecho " - ". Por fim, vamos ampliar um pouco a busca, para que sejam colhidos dados das ações 600 a 630.
import dsd # importação do módulo dsd
inicio = 600
fim = 630
for n in range(fim-inicio+1):
numProcesso = str(inicio+n)
# busca os dados do endereço definido
dados = dsd.get('http://portal.stf.jus.br/' +
'peticaoInicial/verPeticaoInicial.asp' +
'?base=ADPF&documento=&s1=666&numProcesso=' + numProcesso)
# retorna apenas o trecho relevante do código-fonte
dados = dsd.extrair(dados,
'<div class="divider-titulo-formulario">',
'<section id="mapa-do-site">')
# extrai nome da acao
acao = dsd.extrair(dados,
'<div id="divImpressao"><div><h3><strong>',
'</strong>')
# extrai relator
relator = dsd.extrair(dados,
'Relator:</td><td><strong>',
'</strong>')
# processa as variáveis
acao = acao.replace('ARGUIÇÃO DE DESCUMPRIMENTO DE PRECEITO FUNDAMENTAL',
'ADPF')
acao = acao.replace('(Med. Liminar) ',
'')
relator = relator.replace('MINISTRO ',
'')
acao_split = acao.split(' - ')
classe = acao_split[0]
numero = acao_split[1]
print ([classe, numero, relator])Esse processo de começar com uma extração pequena e ir ampliando vai mostrando os limites do nosso algoritmo, que precisa ir sendo polido. Retirar o '(Med. Liminar)' não funcionou para a ADPF 612 porque, nela, liminar veio escrita com minúscula. No caso das ministras Rosa Weber e Cármen Lúcia, é preciso retirar o trecho 'MINISTRA' e não 'MINISTRO'. São ajustes pequenos, mas que garantem uma base de dados limpa e passível de uma análise mais simples.
Além desses pequenos ajustes, vamos introduzir uma inovação na gravação, para garantir que os seus dados sejam legíveis por outros programas.
3.3 Gravar com o dsd.write_csv_row()
Para gravar os dados, utilizaremos um modelo simples de gravação, que é o formato CSV (Comma Separated Values). Essa é uma forma simplificada de gerar tabelas, compostas por um "empilhamento" de várias linhas com a mesma estrutura. Você aprenderá melhor sobre a estrutura do CSV no curso de Data Mining Judicial, sendo que, neste momento, basta entender que o CSV é um arquivo de texto, com apenas dois elementos de formatação:
- vírgulas separam os conteúdos correspondentes a cada célula;
- marcas de parágrafo separam uma linha da outra.
No seu console, você pôde ver o empilhamento de várias listas, cada uma com os dados que indicamos que deveriam ser impressos. O CSV opera como a justaposição desses dados no mesmo arquivo, o que possibilita a sua leitura como se fosse uma tabela. Para viabilizar a construção desta tabela de um modo simples, o módulo dsd.py conta com a função dsd.write_csv_row(), que grava uma linha de dados dentro de um arquivo CSV e tem dois parâmetros:
- O primeiro é o nome do arquivo em que a linha será gravada
- O segundo é o conteúdo da linha, que precisa ser uma lista.
Introduzindo esse formato de gravação, tremos o seguinte código, capaz de extrair os dados e gravá-los dessa forma estruturada.
import dsd # importação do módulo dsd
inicio = 600
fim = 630
for n in range(fim-inicio+1):
numProcesso = str(inicio+n)
# busca os dados do endereço definido
dados = dsd.get('http://portal.stf.jus.br/' +
'peticaoInicial/verPeticaoInicial.asp' +
'?base=ADPF&documento=&s1=666&numProcesso=' + numProcesso)
# retorna apenas o trecho relevante do código-fonte
dados = dsd.extrair(dados,
'<div class="divider-titulo-formulario">',
'<section id="mapa-do-site">')
# extrai nome da acao
acao = dsd.extrair(dados,
'<div id="divImpressao"><div><h3><strong>',
'</strong>')
# extrai relator
relator = dsd.extrair(dados,
'Relator:</td><td><strong>',
'</strong>')
# extrai relator
requerente = dsd.extrair(dados,
'Requerente: <strong>',
'\r\n')
# processa as variáveis
acao = acao.replace('ARGUIÇÃO DE DESCUMPRIMENTO DE PRECEITO FUNDAMENTAL',
'ADPF')
acao = acao.replace('(Med. Liminar) ','')
acao = acao.replace('(Med. liminar) ','')
relator = relator.replace('MINISTRO ', '')
relator = relator.replace('MINISTRA ', '')
acao_split = acao.split(' - ')
classe = acao_split[0]
numero = acao_split[1]
# define os dados a serem gravados como uma linha
row = [classe, numero, relator]
# comando que determina a gravação dos dados (em forma de lista) no arquivo
dsd.write_csv_row('ADPF.txt',row)
# mensagem que indica a conclusão com êxito do programa
print ('Arquivo ADPF.txt gravado')3.4 Abrindo o csv com o Excel
Agora que você tem um arquivo gravado no formato csv, você pode abri-lo com o Bloco de Notas, que mostra o texto efetivamente gravado, mas também pode abri-lo com o Excel, que você pode utilizar para fazer uma análise preliminar dos dados.
Para abrir o arquivo no Excel, você deve iniciar o software e escolher o comando Arquivo Abrir. Você, então, deverá navegar pelos endereços até o seu working directory do Spyder e escolher o arquivo ADPF.txt. Ele não deve aparecer imediatamente porque o Excel costuma mostrar somente os arquivos com extensão .xls e .xlsx (enquanto o seu tem extensão .txt). Para ver o arquivo que gravamos, é só trocar a opção "Exibir todos os arquivos do Excel" por "Exibir todos os arquivos *.*", o que vai tornar visível o ADPF.txt.
Quando você abrir esse arquivo, aparecerá uma janela em que você deve manter o tipo de campo como delimitado (porque o CSV é delimitado por vírgulas) e definir a origem do arquivo (de fato, é o encoding do arquivo) como UTF-8 (um encoding que é capaz de ler os caracteres especiais do português, como cedilha e acentos).
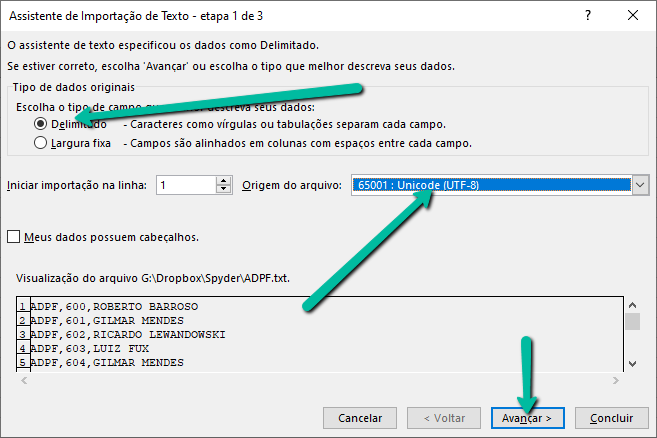
Feito isso, basta clicar em avançar e, na janela seguinte, escolher que o delimitador é vírgulas e concluir.
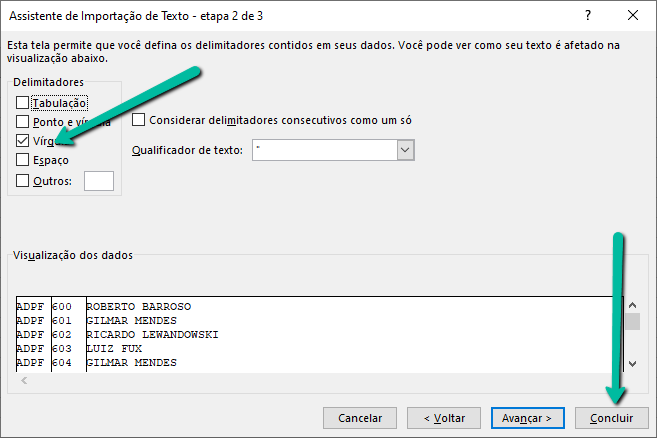
Lendo o conteúdo do arquivo, você provavelmente verá uma repetição das linhas porque você pode ter rodado várias vezes o programa, que acrescenta novas linhas cada vez que é executado. No futuro, você aprenderá a contornar essas questões, e também a inserir cabeçalhos, usando as funções de gravação do módulo dsd.
Porém, apesar de haver vários aprimoramentos que você pode fazer em cada um dos elementos do programa (especialmente na gravação), você já tem um algoritmo capaz buscar dados, organizá-los de forma básica e gravar de um modo acessível, que eram os objetivos deste módulo.




