
1. Comandos
No começo estão os verbos: os verbos nos dão as expressões que utilizamos para definir as ações que o nosso programa deve executar:
- imprima
- grave
- busque
Cada uma dessas expressões é chamada de função (function), e todo algoritmo tem como elemento básico essas determinações de fazer alguma coisa.
Fazer o quê?
- imprima algo
- grave algo
- busque algo
Esse "algo" é um objeto que complementa a função, sendo que a combinação função + objeto nos oferece os exemplos mais simples de comandos (em inglês, statements, palavra que costuma ser traduzidas por instruções).
Quem tem formação em direito tipicamente conhece a diferença entre uma ordem concreta e uma norma abstrata, e a diferença entre funções e comandos é similar:
- comandos são instruções concretas, na medida em que eles se constituem em expressões executáveis;
- funções são instruções abstratas, na medida em que elas somente podem ser executadas na medida em que você complemente a função com alguns valores, sem os quais não é possível saber exatamente o que deve ser executado.
Abra x.
Esta é uma função, pois você entende que se trata de uma instrução para abrir algo, mas não é possível executar essa função porque o x não foi determinado.
Abra o Spyder.
Este é um comando para você abrir o Spyder. Executar esse comando é simples, desde que você tenha instalado a plataforma Anaconda. No Windows, basta você digitar Spyder no menu de busca que fica no canto inferior direito:
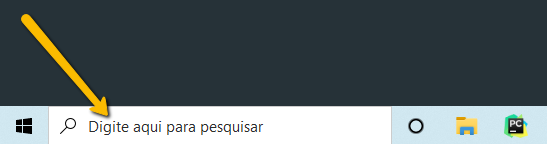
Quando você fizer isso, basta clicar sobre o Spyder e ele executará o programa, abrindo uma tela que a primeira vista parece desafiadora:
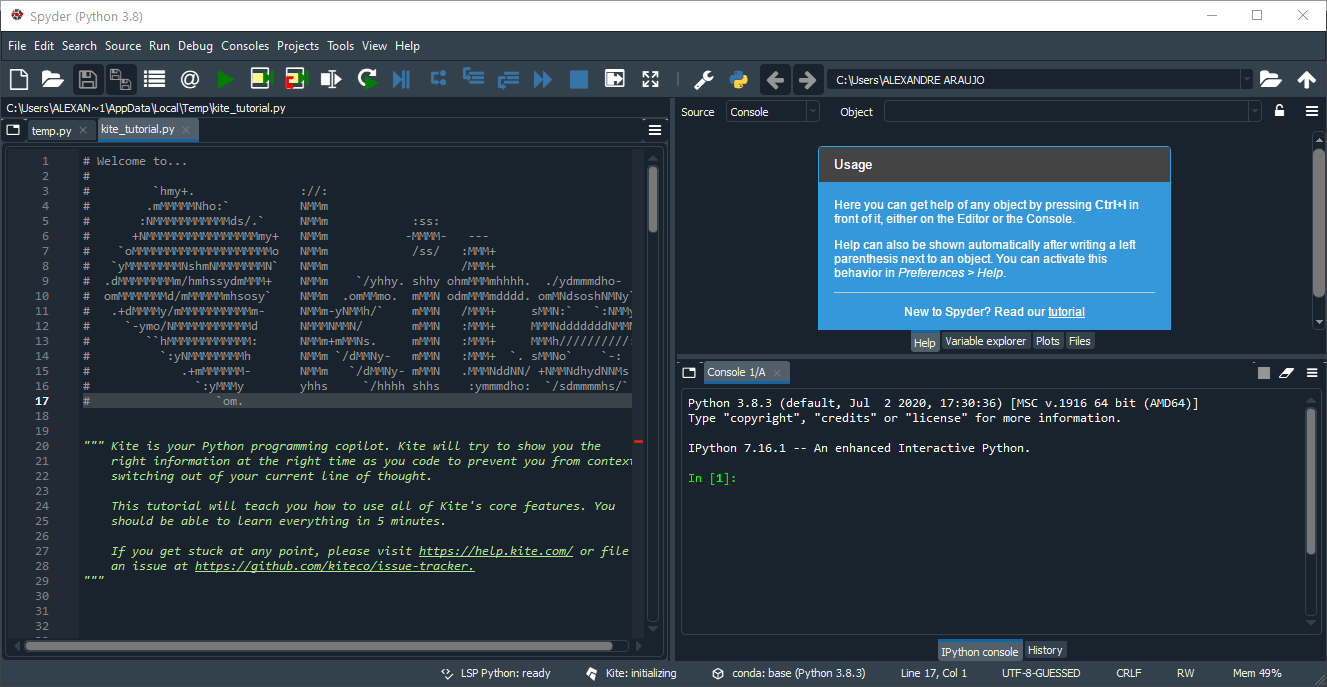
São muitas janelas ao mesmo tempo, e elas podem parecer um pouco confusas a quem está começando a usar esse ambiente de desenvolvimento. Como esse é provavelmente o seu caso, vamos por partes, e a primeira parte a ser explorada é a janela chamada console, no canto inferior direito.
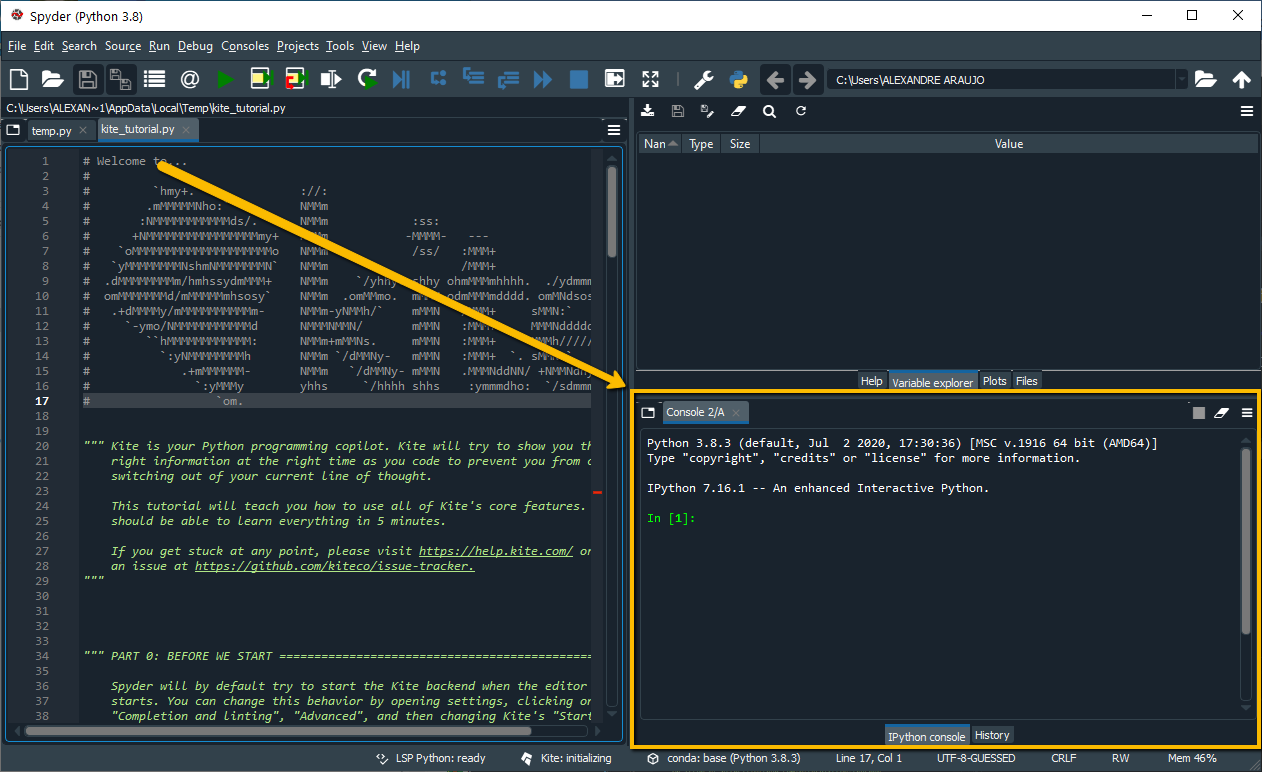
Essa é uma janela em que você pode inserir comandos simples como input [In] e você receberá o resultado desses comandos como output [Out]. Para começarmos, insira no console o comando: print('STF').
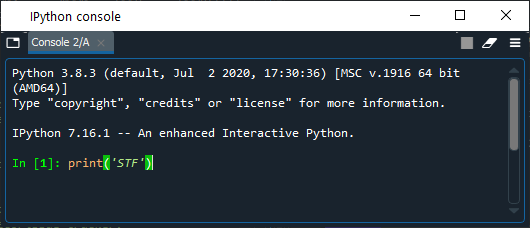
Tome o cuidado de repetir todos os caracteres, pois as linguagens de computação têm uma sintaxe muito estrita e pequenas mudanças podem modificar bastante o resultado. Se você copiou corretamente, o resultado será o seguinte:
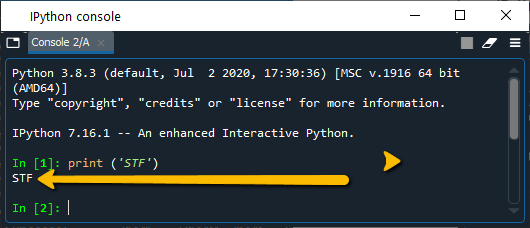
Seguindo a sua determinação, o Spyder imprimiu na tela a sequência de caracteres STF. Porém, se você não tomar cuidado, pode gerar resultados muito diversos. Tente os comandos:
- print STF
Nesse caso, você deve ter a seguinte mensagem de erro no console:

Quando não há parênteses, o Spyder acusa um "erro de sintaxe", ou seja, a falta de um elemento necessário para que o comando seja compreensível. Trata-se de um esquecimento tão comum que a mensagem de erro já traz a sugestão de correção.
Em sua teoria linguística, Saussurre diferenciou os aspectos sintáticos da linguagem (ligados à observância das regras de construção das expressões linguísticas) dos seus aspectos semânticos (ligados à compreensibilidade dos significados). O Python utiliza essa distinção para diferenciar os erros que cometemos ao codificar os comandos, e você receberá o aviso de SyntaxError dezenas de vezes ao longo do curso, pois ele ocorre cada vez que esquecemos de inserir algum elemento necessário para que os comandos estejam completos.
Todo comando print exige um complemento entre parênteses, tanto que você encontrará esse comando (function) descrito como print(), para indicar que a sua sintática exige esse complemento entre parênteses.
Tente agora uma nova expressão:
- print (STF)

Repare que este é um erro diferente. Não é um SyntaxError, mas um erro semântico, referente ao significado da expressão (name) STF.
Quando você manda imprimir 'STF', o que o computador entende é que você mandou imprimir uma sequência (string) de caracteres formada por S, T e F. Ele não tem elementos para entender que STF é um tribunal, nem mesmo que é uma sigla.
A string 'STF' não aponta para um objeto externo a ela (um tribunal, uma quantidade, um endereço): ela é simplesmente uma sequência de letras, como seria também 'TSF' ou "FST".
O marcador de string são as aspas (para o Python, tanto faz usar aspas duplas ou simples, desde que você abra e feche a string com aspas do mesmo tipo), que possibilitam que você use comandos como:
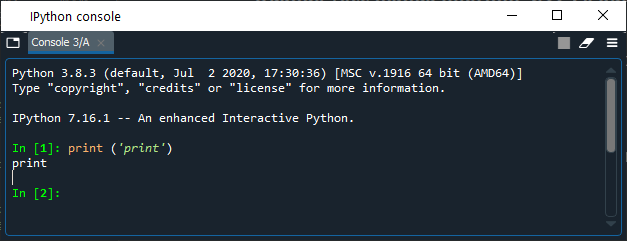
O print é entendido como um comando, mas o 'print', por estar entre aspas, é processado como uma string. Porém, se você insere o print (STF), sem aspas, o Python entende que STF seria um nome (name), ou seja, uma expressão que aponta para um objeto (que pode ser um número, uma string ou uma função).
Todo nome tem um significado, mas STF não é o nome de uma função do Python e você não atribuiu significado algum à expressão STF. O NameError indica que STF é um nome que não teve seu significado definido. E o mesmo ocorre com o Print em maiúscula, que não é um comando do Python e, por isso, também é entendido como um nome que não tem significado definido, o que gera a mensagem de erro 'name STF is not defined'.
A falta de um significado não é um problema sintático (que é uma expressão mal construída pela falta de um elemento), e sim um problema semântico (uma incapacidade de dar sentido a um nome cujo sentido não havia sido determinado previamente), o que gera o NameError, em vez do SyntaxError.
Agora tente um novo comando:
- Print ('STF')
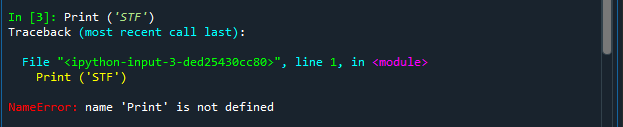
Observe que você teve a mesma mensagem de erro porque Print não é uma função do Python, que é sensível à diferença entre maiúsculas e minúsculas. Print é diferente de print, que é diferente de PRINT. Portanto, o Python não tem como processar o comando Print ('STF'), que não tem significado algum na linguagem Python.
Não usamos o termo linguagem de programação à toa. Python é efetivamente uma linguagem, que é processada por um programa específico: o interpretador. Diferentemente do seu cérebro, que busca dar sentidos adequados para expressões com problema (como "Python é uma langagem"), o interpretador do Python só sabe processar expressões construídas de forma muito precisa.
Essa incapacidade de lidar com imprecisões pode parecer um defeito, mas não é. Uma linguagem extremamente precisa exige que você explique exatamente o que ela precisa fazer (o que pode ser um peso), mas ela realiza exatamente aquilo que você determinar. A exigência de que a função print tenha um complemento entre parênteses permite que você saiba exatamente o que você está mandando imprimir. A diferenciação entre STF e 'STF' permite que você mande imprimir strings (como 'STF' ou 'Marco Aurélio' ou 'Procedente') ou que você imprima o conteúdo de nomes cujo significado você defina previamente.
2. Variáveis
2.1 Nomes
Como posso definir significados para um nome?
Depende, é claro, do tipo de significado que você atribua a ele. Neste ponto, vamos começar pelo significado que mais usaremos: nomes podem significar uma string.
Para atribuir (assign) um significado ao nome, usamos a função '=':

Importante: Processo = 'ADI333' não é uma afirmação sobre o nome processo, mas é uma atribuição de significado. Em Python, o símbolo de igual não é '=', mas é '=='.
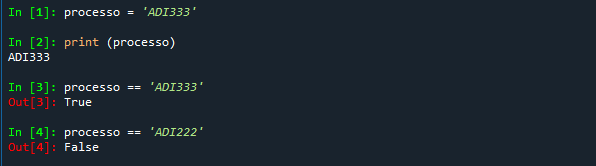
Uma vez definido que o nome processo terá por conteúdo a string 'ADI333', a expressão processo == 'ADI333' será uma afirmação verdadeira, enquanto processo == 'ADI222' será uma afirmação falsa.
2.2 Variáveis e atributos
Imagine que queremos construir um banco de dados sobre processos. Você já sabe o que é uma unidade de análise e sabe que, quando construímos uma base de dados, nós ligamos cada unidade (cada linha de nossa tabela) a uma série de 'atributos'. Se construirmos uma tabela que têm como unidade de análise processos, podemos ter esses 3 atributos básicos:
- Número do Processo
- Data de Julgamento
- Relator
Como esses atributos variam para cada uma dos processos, eles são chamados de variáveis. Para o analista de dados, que observa as informações a partir de seu significado, as variáveis são os atributos das suas unidades de análise, que entram como parte dos seus bancos de dados.
Já um programador, concentrados no modo pelo qual o computador processa as informações, as variáveis são nomes dados para dados que é preciso gravar e manipular dentro dos programas. Quando você define que processo = 'ADI333', seu programa aloca uma certa área da memória do seu computador para guardar esse dado. Por isso, toda vez que você cria uma variável, você precisa atribuir um valor a ela.
Um analista de dados pode criar uma variável em abstrato, definindo conceitualmente quais serão os atributos que serão mapeados por essa categoria. Porém, dentro da programação, não podem ser criadas variáveis dessa forma, pois variáveis não são categorias, mas são uma determinada ligação entre um nome e um valor. Não existe uma função criar variável processo. O que existe é a atribuição de um valor (como 'ADI333') a um nome, de tal forma que esse nome funcionará como uma variável:
- toda vez que você inserir o nome processo, o programa utilizará o valor ligado a esse nome;
- toda vez que você atribuir um novo valor ao nome processo, o programa substituirá o valor anterior pelo novo valor.
Em Python, as variáveis são nomes que admitem dois tipos básicos de valores: strings e números (sendo que há vários tipos de números). Você logo se acostumará a chamar de variáveis cada um dos nomes aos quais você designará um valor (que, em termos do modelo de dados, são os atributos que serão mapeados).
Cada programa que você escrever lidará com uma série de variáveis porque nunca fazemos algoritmos para lidar com um processo judicial apenas. O trabalho de fazer um programa para analisar processos judiciais só vale a pena quando podemos repetir a mesma operação para um grande número de objetos, de tal forma que o trabalho de fazer o código seja mais rápido do que o trabalho de analisar individualmente cada processo em busca das informações que desejamos.
2.3 O nome das variáveis em Python
Em Python, temos de adaptar a denominação dos dois primeiros atributos porque os nomes não admitem espaços (pois data de julgamento seria entendido como 3 nomes e não como um) e não admite acentos (porque os nomes em Python só podem ser escritos no limitado repertório da tabela ASCII). Os nomes das variáveis precisam começar com uma letra, mas admitem também números e underscores, nada mais.
Assim, podemos adaptar os nomes pensados antes para:
- NumeroDoProcesso
- data_de_julgamento
- Relator
Outra saída típica seria usar underline no lugar dos espaços, ou simplificar ainda mais os nomes, que é o que eu normalmente faço, ficando com uma palavra apenas, em letras minúsculas:
- processo
- julgamento
- relator
A definição dos nomes é uma questão de estilo, mas usarei essa última combinação porque vocês vão ter de escrever várias vezes esses nomes, e nomes mais simples geram menos erros (embora digam menos sobre o que os nomes significam de fato, algo que é mais claro no modelo anterior).
Agora escolha no site do STF uma ação e insira um conteúdo para cada uma dessas variáveis, tal como:

Cronometre o tempo que você leva para entrar na página, procurar os dados do processo e escrever isso no Spyder. Imagino que você levará entre 40 e 50 segundos para realizar essa atividade, com relação a 3 informações simples e pequenas.
Você logo aprenderá a criar um programa que realize isso de forma automatizada, entrando no site do STF, colhendo todos os atributos que você definir em cerca de 1 processo por segundo. Como o programa será centenas de vezes mais rápido (e bem mais preciso) do que você, valerá o esforço de elaborar o algoritmo que diga exatamente o que o computador deve fazer. Para isso, é preciso aprender a lidar com as variáveis.
2.4 Variable explorer
Por falar nas variáveis, é hora de observar uma outra parte do Spyder, que estava um pouco escondida: o explorador de variáveis (variable explorer).
Na exibição padrão do Spyder (Spyder Default Layout), existe uma janela grande na esquerda (que ainda não usamos), e na direita existe o console (que estávamos usando até agora) e também uma janela de Help. Se você olhar com cuidado, verá a aba Variable Explorer ao lado da aba de Help, na janela superior direita.
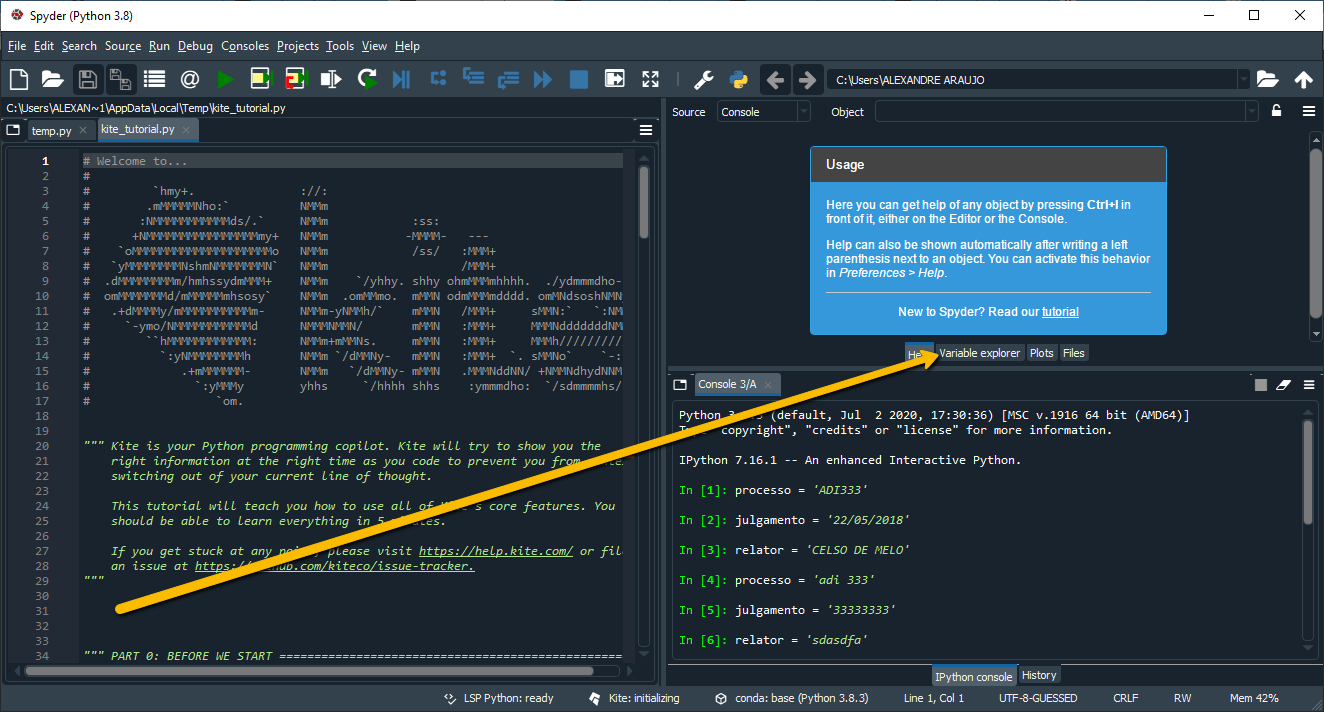
Para dar mais visibilidade a essa ferramenta que nos é muito útil vamos adotar o formato de tela que será o layout padrão das gravações de tela deste curso: a exibição RStudio, alterada na barra View, como indica o vídeo abaixo, que deve ser visto em tela cheia porque as letras ficam muito pequenas na exibição reduzida:
Essa modificação deixa o explorador de variáveis na sua janela superior direita, e veja que ali estão as 3 variáveis definidas, bem como o conteúdo que atribuímos a elas.
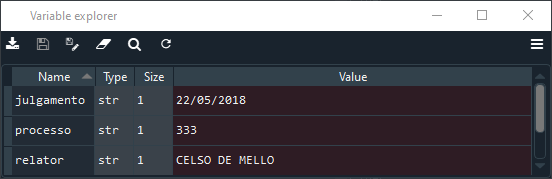
Estão ali as 3 variáveis definidas, com o conteúdo que foi dado. Como atribuímos 3 conteúdos string, o tipo da variável aparece como 'str'.
3. Strings e números
Não confunda '333' com 333.
Os números, em Python, aparecem sem aspas e a sua utilidade é justamente que eles podem ser tratados por meio de operações matemáticas. Se você voltar para o console (que mudou de lado e está agora na parte inferior esquerda) e escrever 333 + 333 , o que aparecerá na sua tela?
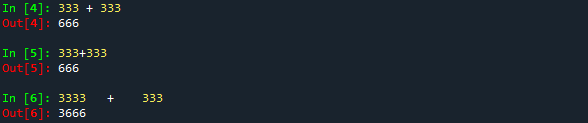
Isso ocorre porque um número pode ter vários nomes. 333, 332+1 e 666/2 são três nomes diferentes do mesmo número. O número é a quantidade designada, não importa se o designemos de uma forma direta (333) ou por meio de combinações de símbolos que (como 111x3). Também podemos designar um número quando o definimos como o valor de uma variável:

Note que, nos inputs, o Spyder deixa os números em amarelo, para ajudar a diferenciar das strings, que são brancas.
Quando definimos que processo = 333, processo passa a ser um nome para a quantidade 333, o que permite que usemos o nome processo dentro de operações matemáticas, tal como se usássemos o numeral 333.
Não confundir o número 333 com o numeral 333, pois numeral é um nome do número, usando algarismos (que, por sua vez, são símbolos usados para construir numerais: 0, 1, 2, III, IV, V, etc.).
Olhe novamente o explorador de variáveis e você verá que algo mudou:
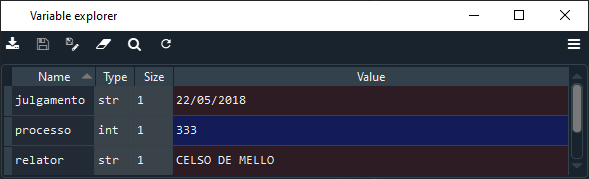
A variável de nome processo continua tendo 333 como valor, mas esse valor agora é um int, ou seja, um número integral (integer). Antes, tratava-se da string '333', que é um valor totalmente diverso. Nesse caso específico, por mais que falemos em 'Número do Processo', o 333 de ADI333 não é um número (uma quantidade), mas é uma indicação de que ela ingressou no Tribunal depois da ADI332 e antes da ADI333.
Não devemos usar esse 333 em nenhuma operação matemática e, por isso, devemos tratar o número do processo como str, e não como int.
Uma vez que retornemos o 333 para string, experimente qual é o resultado das expressões:
- processo + processo
- processo - processo
- processo * 5
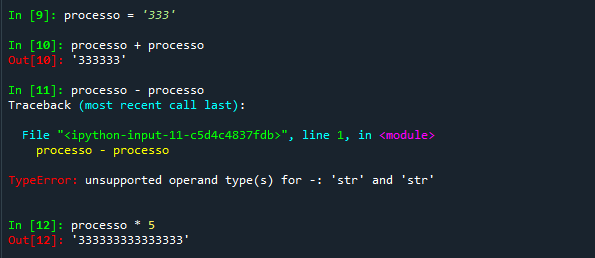
Observe que a primeira expressão concatena as duas strings poderemos usá-lo em uma operação '+', que não é de soma, mas de concatenação. O símbolo '+', que é usado para somar números, é também usado para concatenar strings. Já o símbolo '*' concatena várias vezes uma string consigo mesma.
Porém, não há operações de strings ligadas aos símbolos '-' ou '/', o que gera mensagens de erro: esses dois operadores somente são aplicados a números.
Um problema comum ocorre quando temos uma variável numérica e pretendemos concatená-la com uma string. Isso acontece, por exemplo, se você tem uma lista de 50 andamentos de um processo e deseja chamar cada andamentos desses de andamento1, andamento2, andamento3 e assim por diante. Para usar esse caso no console, você pode definir:
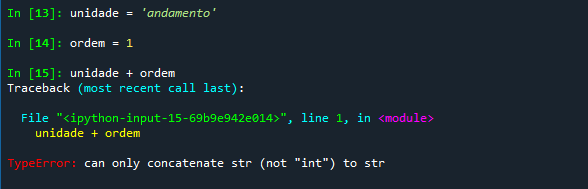
Nesse caso, retorna um TypeError, pois strings somente podem ser concatenadas a outras strings. Pare resolver esse problema, você precisa usar a função str(), que converte uma variável qualquer em uma string, que poderá então ser concatenada.

Outra situação comum é a de você buscar informações em uma base de dados e acabar tendo números no formato string. Você pode ter uma tabela com a duração do processo ou o valor da causa, que são quantidades, mas que vão ser interpretados como strings porque foram extraídos apenas como textos contidos em uma tabela. Nesse caso, você precisa usar a função int(), para converter a string em um número inteiro, quando ela é formada por algarismos arábicos.
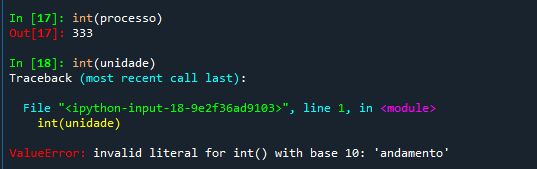
Se você observar o Variable Explorer, verá que a expressão int(processo) retorna um número, mas não alterou o valor da variável. Ocorre que, muitas vezes, você deseja justamente alterar esse valor de forma definitiva, por tratar-se efetivamente de um número e não de um nome. Nesse caso, você pode redefinir o valor de processo:

4. Trabalhando com strings
Agora que você já sabe o que é uma string e sabe converter integers em strings (e vice-versa), você precisa aprender o último tópico dessa parte inicial sobre variáveis: manipular as strings.
4.1 Replace
Esse é um ponto importante porque é preciso utilizar esse tipo de alteração o tempo todo nos processos de extração de dados. Por exemplo, muitas vezes extraímos o campo ministro e temos dados como 'Min. Marco Aurélio', mas desejamos retirar o título, ficando apenas com o nome. Essa é uma função para a qual utilizamos a função replace, que segue o seguinte modelo:

Usamos, então, o string.replace('texto a ser substituído', 'texto a inserir'), sendo que nesse caso específico inserimos uma string vazia '', que apaga o texto substituído.
O replace pode ser usado das formas mais variadas, tais como:
- substituir letras acentuadas por não acentuadas (pois elas são entendidas como letras diferentes e é preciso padronizar as bases de dados);
- simplificar as bases (por exemplo, substituindo todas as Ação Direita de Constitucionalidade por ADI);
- limpar os dados (por exemplo, substituindo dois espaços por um espaço).
4.2 Concatenar
Outra foram de manipular as strings é concatená-las de forma adequada, para gerar expressões maiores. Uma expressão que você precisará de usar muitas vezes é o endereço na internet (url) em que estão os dados de cada processo. Um dos endereços que contém dados sobre a ADI 6000 é o:
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&numProcesso=6000
Estudaremos ainda a estrutura desses endereços, mas você já deve ter notado que o numProcesso=6000 está relacionado com o número do processo o que nos permite criar uma variável endereço que possa nos oferecer o endereço das várias ADIs:
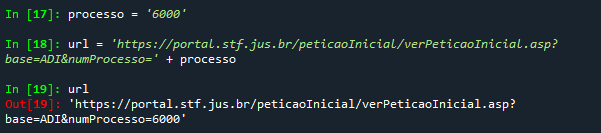
Com essa construção de que a variável url é formada pela concatenação de duas strings (o início do endereço mais o número do processo). Com isso, se você mudar o número do processo, e redefinir a variável url, será gerado um novo endereço.
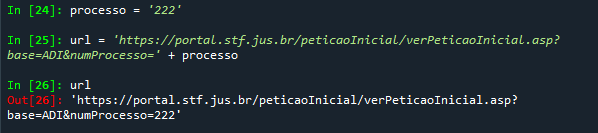
Observe que alterar a variável processo, sem redefinir a variável url, não vai alterar o conteúdo desta segunda variável.

Por que isso ocorre? Pelo próprio sentido de uma variável string, que é constituída literalmente por uma cadeia de caracteres. Quando você define o conteúdo de uma string, o Python atribui a essa variável um valor que, no caso acima, é a sequência 'https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&numProcesso=222'. No input [25], usamos o valor da variável processo para definir o valor da variável url, mas isso não significa que isso fique gravado na memória do Python, que simplesmente liga determinadas variáveis a certos valores.
Por esse motivo, uma alteração na variável processo não tem impacto direto na cadeia de caracteres que constitui o valor de url. Essa interferência somente ocorrerá se você redefinir o valor de url, atribuindo a ela um novo conteúdo, que seja baseado no novo valor de processo.
4.3 Posição dos caracteres na string
Por fim, você pode manipular as strings a partir da alteração direta de elementos que fazem parte dela, usando referências aos elementos que a constituem.
A string é literalmente uma sequência de caracteres, e é assim que ela é armazenada e pode ser acessada: uma sequência linear, que começa do caractere de número 0 e segue sendo numerada até o último objeto. Para identificar um caractere, basta dar o nome da string seguido de sua posição, entre colchetes.
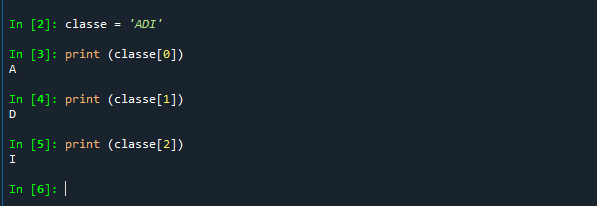
Nesse início, nunca é demais ressaltar que:
A primeira posição de toda string é 0. Não é 1. É 0!
Isso precisa ser ressaltado porque trata-se de uma característica do Python que é diferente de outras linguagens, como R. Como essa posição inicial no 0 não é intuitiva (nossa tendência é contar a partir do 1), trata-se de uma das causas mais comuns de erros de programação.
Essa é uma convenção contraintuitiva, mas que parece ter motivo porque facilita o cálculo de intervalos. Imagine que você deseja baixar do STF as ADIs 100 a 300. Uma forma usual é identificar o padrão do endereço da ADI100 e depois automatizar que o programa buscará a ação 100, depois a 100+1, depois a 100+2, depois a 100+3 e assim por diante. A forma mais usual de fazer isso é indicar que o programa deve buscar a ação 100+n (porque 1 é o número da primeira ação), repetindo isso 201 vezes (seriam 200 se você quisesse de 101 a 300). Nesse caso, há duas opções:
- se n variar de 0 a 200 (como ocorre em Python), basta você dizer que o programa deve buscar no portal do STF a ação 100 +n (pois a primeira ação a ser buscada será justamente a ADI001, que é 100 + 0);
- já se n variar de 1 a 201, você teria de dizer que a ação buscada seria correspondente a 100 +(n -1), porque você precisaria somar 0 à sua posição inicial, para que o intervalo fosse correto. Sem esse cuidado, você teria grande chance de começar o intervalo do lugar errado, o que te daria as ações de 101 a 201.
Embora você tenha que se lembrar que a posição inicial é sempre 0 (o que pode ser difícil no começo), você terá menos chance de cometer erros quando calcular intervalos, já que nesse momento o que você quer de verdade é que o intervalo seja de 100 + 0, 100 + 1, 100 + 2 e assim por diante. Logo, o fato de a posição inicial ser 0 facilita o cálculo dos intervalos (evitando der de somar +1 em todo intervalo) e torna os códigos mais elegantes.
4.4 Intervalos de caracteres
Agora que você sabe identificar um caractere dentro da string, é fácil você conseguir extrair um intervalo, que é dado por meio de um ":", segundo o modelo:
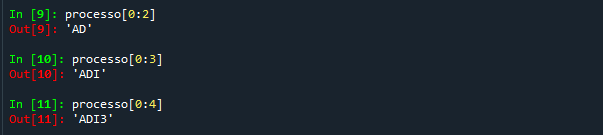
Aqui, os desenvolvedores da linguagem também tiveram de fazer uma escolha difícil. Se você define um intervalo [0:3], você pode querer dizer 4 coisas diferentes:
- Você deseja somente o que está no meio, excluindo os pontos de marcação, o que deveria retornar as posições 1 e 2.
- Você deseja incluir as posições indicadas no intervalo, o que retornaria 0, 1, 2 e 3.
- Você deseja incluir a posição inicial e excluir a posição final, o que retornaria 0, 1 e 2.
- Você deseja excluir a posição inicial e incluir a posição final, o que retornaria 1, 2 e 3.
Os desenvolvedores de Python resolveram utilizar a saída 3. É muito comum desejarmos incluir desde a primeira posição, e seria muito ruim que a extração do termo 'ADI' fosse escrito como [-1:3]. Como o intervalo deveria incluir a primeira posição, seria razoável que ele incluísse também a segunda, de tal forma que 'ADI' corresponderia a [0:2]. Porém, como você deve ter notado pela figura anterior, a saída do Python foi a terceira: incluir o início e excluir o final.
Por que essa escolha que também parece estranha. Acho que ela se explica também pelo modo usual de calcularmos intervalos. Imagine que você deseja buscar o relator de uma ADI no texto da página. Uma saída típica seria usar a função find(), que é usada da seguinte forma.
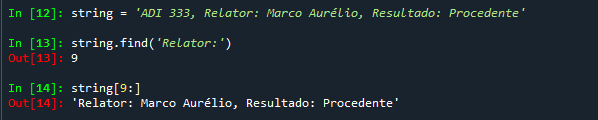
O comando string.find('Relator: ') busca a primeira ocorrência de 'Relator:' dentro da variável string e retorna a posição do primeiro caractere dessa sequência. Com isso, o comando string[9:] nos retorna a sequência da posição 9 até o final.
Mas a verdade é que não queremos extrair o termo 'Relator: ', somente o nome do relator, e por isso devemos deslocar o início da extração da posição 9 para a posição 9 + o número de caracteres de 'Relator: ', que nos é dado pelo utilíssimo comando len(), que vem de lenght:
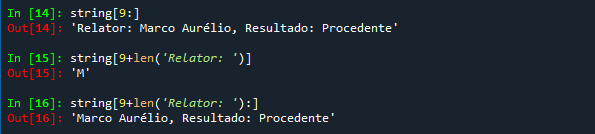
Para facilitar a nossa vida, podemos otimizar esse resultado inserindo uma variável inicio, que é a posição onde está o termo 'Relator: ', que serve como marcador de início do nome do relator, somado do número de caracteres desse marcador.
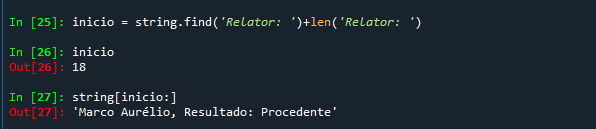
Com isso, chegamos ao mesmo resultado, mas de uma forma mais elegante e legível. E agora que conseguimos encontrar o ponto inicial de extração, podemos encontrar também uma marcação adequada para o final desse nome, que acaba logo antes de uma ','. Com isso, podemos encontrar o final se descobrirmos a posição dessa ','.
Ocorre que nós não queremos que esse marcador do final entre no nosso intervalo! E é por isso que os desenvolvedores de Python devem ter escolhido a opção 3:
normalmente queremos que a posição inicial seja incluída, e queremos que o marcador de fim seja excluído do texto extraído.
Se você usar um string.find(','), o resultado será a posição da primeira vírgula, que vem depois de 'ADI 333', o que não nos interessa. Porém, isso é facilmente resolvido pela utilização da forma completa da função find, que admite a inclusão de uma posição inicial para a busca, que será justamente a variável. Com isso, teremos:
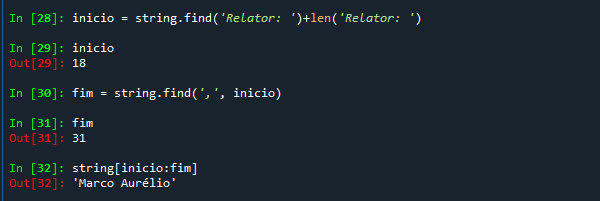
Essa lógica de encontrar um marcador de início e um marcador de fim, para extrair o que está no meio, será utilizada exaustivamente nos nossos programas de extração.
A extração desses segmentos é importantíssima porque, quando buscamos informações dentro de uma página da internet, o que temos é uma imensa string, com milhares de caracteres, e precisamos extrair pontos específicos. Uma posição errada transforma "Marco Aurélio" em "arco Aurélio". Duas posições de erro podem transformar um 'Improcedente' em 'procedente '. Mas, com uma escolha adequada de marcadores de início e de fim, você é capaz de extrair qualquer texto que desejar.
5. Resumo
O que você aprendeu até aqui:
- Definir variáveis string e numéricas,
- Alterar o valor das variáveis,
- Manipular strings usando a função replace,
- Extrair textos a partir de sua posição na string,
- Encontrar posições na string usando a função find,
- Extrair trechos usando a lógica de marcador de início + marcador de fim.




