1. Calculando o erro padrão
Para compreender adequadamente a mecânica do teste de hipóteses, você precisa aprender a fazer uma estimativa do erro padrão.
Uma forma de entender esse erro padrão é pensar que o resultado de uma amostra determinada não nos possibilita saber qual é média populacional. Por exemplo: ao definir 160 amostras aleatórias 400 elementos (n=400) da população de ADIs e ADPFs ajuizadas até março de 2021, chegamos ao seguinte quadro:
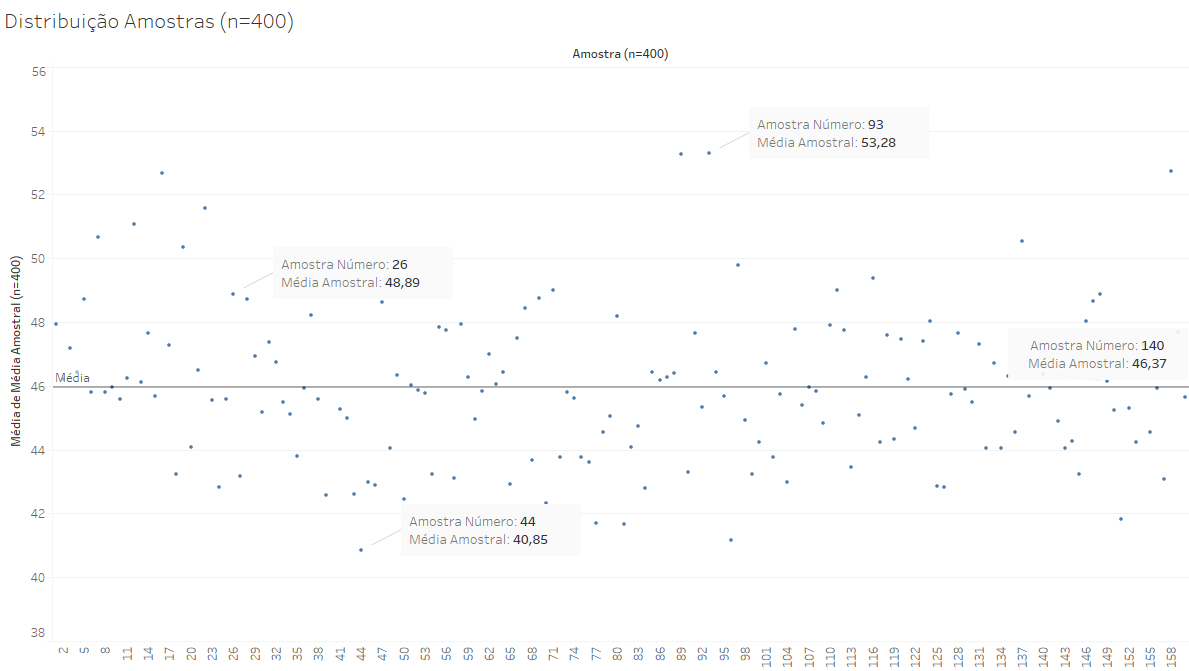
Se você tiver apenas uma amostra, é impossível saber se ela é mais próxima da amostra 93 (que fica no grupo das médias mais altas, com 53,28 andamentos) ou mais próxima da amostra 44, que tem média 40,85. Porém, você sabe que 95,5% das amostras estará a dois desvios padrão da média das amostras.
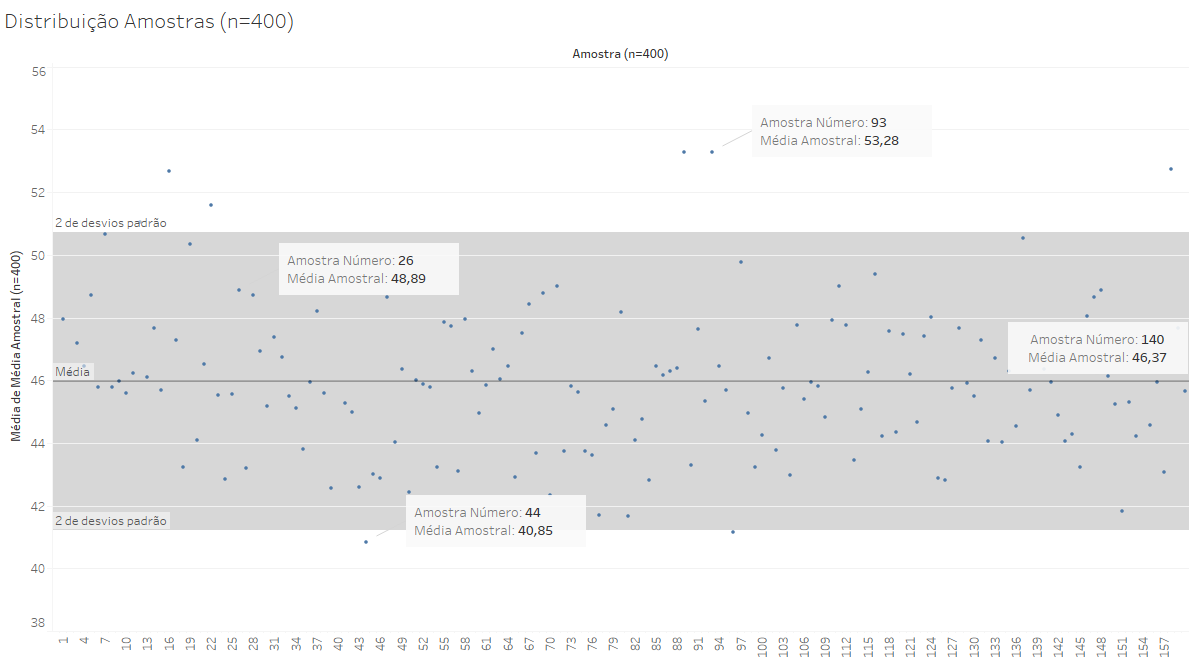
O desvio padrão da população de amostras é justamente o erro padrão, que nesse caso é de 2,38, o que permite esperar, com 95,5% de segurança, que a média amostral estará a menos de 4,76 andamentos da média populacional de 46 andamentos.
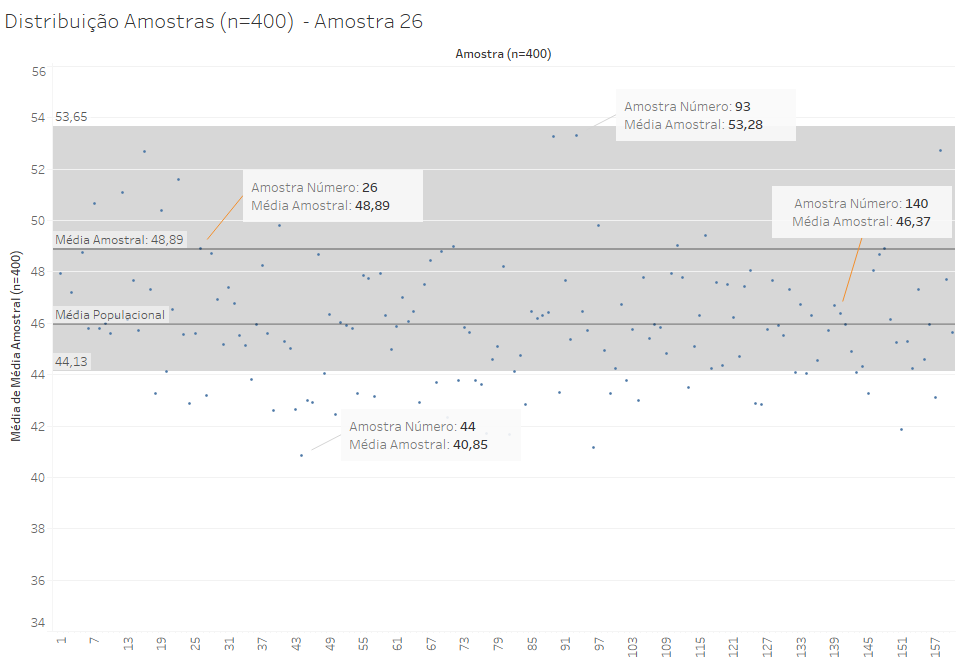
Vamos mudar um pouco o gráfico para medir essa distância a partir da amostra, e não da média populacional, que normalmente é desconhecida para o pesquisador. 95,5% das amostras serão como a 26: projetando uma faixa com a largura de dois desvios padrão, essa faixa abrangerá a média populacional.
Porém, 4,5% das amostras serão como a amostra 44: a média populacional está um pouco mais afastada da média amostral que a medida de dois erros padrão.
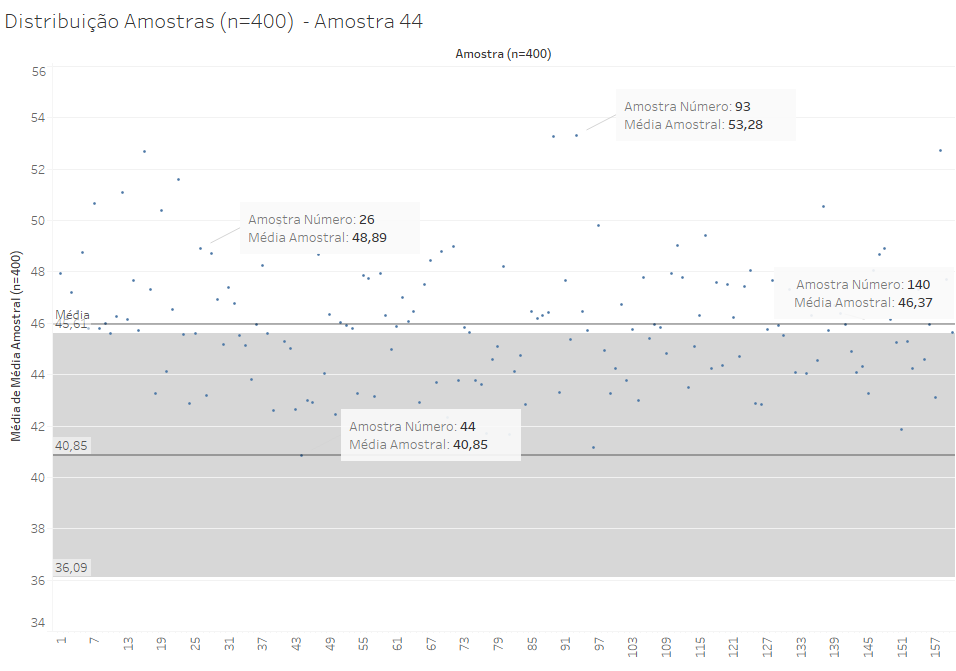
Nesse caso específico de 160 amostras, nenhuma delas está a mais de 3 erros padrão, o que deve ocorrer apenas 3 vezes a cada 1000. Porém, se você projetar um número suficientemente grande de amostras (2.000 amostras, por exemplo), é provável que você encontre alguns casos assim.
De toda forma, com n=400, é difícil que você tenha amostras muito distantes da média. Mesmo a amostra 44, que está fora do erro padrão, oferece um resultado com um erro que alcança quase a média (afinal, 45,61 é um valor muito próximo de 46). Por esse motivo, usar a média de amostras grandes nos possibilita prever, com certa segurança, que a média populacional está em uma certa faixa de valores.
No exemplo dado, estimamos o erro amostral com base na média de mais de uma centena de amostras. Essa é uma estimativa, pois um conjunto diferente de amostras teria um desvio padrão diverso. Mas também é possível fazer uma estimativa a partir de uma amostra isolada, a partir de um cálculo tão simples que dispensa uma calculadora específica.
O erro padrão de uma amostra corresponde à média amostral dividida pela raiz quadrada do número de amostras.
Erro Padrão = MédiaAmostral ÷ √TamanhoDaAmostra
Isso significa que o erro padrão, para qualquer amostra de 400 elementos, é alcançado dividindo o desvio padrão por 20 (que é a raiz quadrada de 400). Em outras palavras, se você quer um erro padrão de menos de 5% (que é o mesmo que dividir por 20), você precisa ter uma amostra de 400 elementos.
Imagine que três pesquisas diferentes usassem as amostras 26, 44 e 93.
- Usando a média da amostra 26, o erro padrão estimado seria de 2,44.
- Usando a média da amostra 44, o erro padrão estimado por esse cálculo seria menor, pois a média é mais baixa: 40,85 ÷ 20 = 2,04.
- Já se você usasse a Amostra 93, o erro padrão estimado seria de 2,66.
Veja que essas estimativas são próximas daquelas aquelas que conseguimos estimar a partir do desvio padrão de 160 amostras, que geraram um erro padrão de 2,38, que é um valor confiável porque a média das amostras converge com o resultado da média populacional, obtido por uma análise censitária (que apontou 47 andamentos como média). Portanto, nossos valores corroboram a prática comum de estimar o erro padrão a partir do mencionado cálculo.
Vimos que, para um erro padrão correspondente a 5% do valor da média populacional, devemos ter uma amostra de 400 elementos. Já se você almeja um erro padrão de 2% da média, você precisará de uma quantidade de amostras que permita dividir o valor da média por 50 (visto que 1/50 é 2%), o que eleva o n da sua amostra para 2500! Assim você deve ter notado porque os números mágicos de amostras giram em torno de:
- 100, para erros de 10%
- 400, para erros de 5%
- 1.000, para erros de 3.2%
- 2.500, para erros de 2%
- 10.000, para erros de 1%
Como muitas das populações que desejamos analisar são menores que as amostras necessárias para ter erros padrão pequenos, os juristas repetidas vezes precisam se contentar com erros padrão relativamente altos.
Tais erros padrão muito altos tornam bastante comum que as pesquisas conduzam a resultados inconclusivos no plano da estatística inferencial, embora nos ofereçam elementos relevantes de estatística descritiva, que auxiliam a interpretar os dados a partir de estratégias qualitativas.
Neste ponto, deve ficar mais clara a distinção entre:
- metodologias de pesquisa propriamente quantitativas, baseadas em estratégias de estatística inferencial, que medem os resultados em termos de significância estatística, e
- metodologias qualitativas que interpretam dados quantitativos por meio do estabelecimento de conexões com elementos históricos, sociológicos e jurídicos que não podem ser inferidos dos dados medidos, mas que fazem parte do repertório de conhecimentos do pesquisador acerca do contexto em que os fenômenos mensurados se inserem. Essa combinação de levantamento quantitativo de dados e interpretação qualitativa é uma das formas de pesquisa quali-quantitativa (quali-quanti).
2. Do erro padrão à margem de erro
A margem de erro é calculada com base no erro padrão, mas não se confunde com ele. O erro padrão é uma decorrência do erro amostral: a aleatoriedade faz com que não possamos inferir que o parâmetro populacional será um ponto determinado, mas apenas que ele deve estar em uma faixa de valores possíveis.
O erro padrão precisa sempre ser lido em conjunto com a regra empírica, pois o que ele nos indica é que o parâmetro populacional tem chances de estar a certo erro padrão da média, na seguinte proporção:
- 68% de chance de estar a 1 erro padrão,
- 95,5% de chance estar a 2 erros padrão,
- 97,3% de chance de estar a 3 erros padrão.
Quanto maior o nível de segurança que você pretende atingir com a sua afirmação, maior será a sua margem de erro, proporcionalmente ao erro padrão. Para um mesmo tamanho de amostra:
- Se você quiser fazer inferências com apenas 68% de nível de segurança a sua margem de erro será de um erro padrão. Esse é um nível de segurança baixo, pois a sua afirmação deve estar errada em 1/3 das amostras!
- Se você quiser 95,5% de nível de segurança, a sua margem de erro será de 2 erros padrão. O mais típico é que o nível exigido seja ligeiramente diverso: 95%, que exige um pouco menos de 2 erros padrão (mais especificamente, exige 1,96 erros padrão).
- Se você quiser 99,7% de nível de segurança, a sua margem de erro será de 3 erros padrão. Esse é um nível muito alto, sendo mais comum que se utilize uma margem de 99% de segurança, que exigirá um pouco menos de 3 erros padrão (mais especificamente, 2,57 erros padrão).
3. A Pontuação Z (z score)
Neste momento, vale a pena introduzir a ideia de pontuação z (z score), que utilizamos logo acima sem introduzir o conceito, e que será usada logo abaixo, para o cálculo da significância estatística da sua análise.
O valor Z indica, em número de desvios padrão (e o erro padrão é um desvio padrão da população de amostras), o quanto um determinado ponto está distante da média populacional. No caso de nossos testes de hipótese, normalmente trataremos da distância de uma média amostral, em erros padrão, da média populacional.
O z score de um ponto que está a um desvio padrão da média é 1. Portanto, definir como significantes pontos a mais de 95,5% de distância da média significa atribuir significância a pontuações z maiores que 2 (se a diferença for para mais) ou menores que -2 (se a diferença for para menos).
Como usamos tipicamente o nível de confiança 95%, o valor Z correspondente é de 1,96. Já o valor Z para 99% de confiança é 2,57.
4. Calculando a margem de erro
Agora que você deve ter compreendido a lógica, podemos passar para o uso da calculadora de margens de erro, que opera de forma bem semelhante à calculadora de tamanho de amostra.
Um nível de confiança de 95% parece um nível equilibrado com 2% de erro padrão, pois fica próximo de 5% tanto a margem de erro (que será de 3,92% da média) quanto a própria chance de que amostra esteja fora dos limites da margem de erro. Porém, amostras de 2500 elementos costumam exigir tanto tempo e dinheiro que podem tornar a sua pesquisa inviável em algum desses aspectos. Isso faz com que seja uma alternativa razoável optar por margens de erro maiores, em volta de 5%, para que você possa trabalhar com amostras
Tendo como base o mesmo tamanho de amostra, 99% de confiança parece mais desequilibrado, pois você terá uma chance muito grande de que a média populacional esteja dentro de uma margem de erro que pode ser muito ampla. Ocorre, porém, que quando você quer uma confiança muito grande, o normal é que você deseje ao simultaneamente uma margem de erro pequena, combinação que somente pode ser alcançada por meio de uma redução substancial do erro padrão.
Por isso, é preciso não cair no erro de elevar muito o nível de segurança sem reduzir substancialmente o erro padrão, visto que esse movimento não vai ser capaz de alterar substancialmente a sua margem de erro e não tende a contribuir para que suas conclusões sejam significativas.




