Estatística descritiva: principais conceitos


1. Introdução
Este texto apresenta, de maneira simplificada, alguns conceitos básicos de descrição e interpretação de dados estatísticos. O objetivo dessa apresentação é proporcionar a você o domínio de instrumentos que viabiliza a organização, resumo e apresentação de dados coletados em uma pesquisa empírica. O domínio dessas categorias permite que você extraia informações relevantes dos dados analisados, interpretando tabelas, gráficos e medidas descritivas.
O foco deste texto é em estatística descritiva, ou seja, a estatística relativa a uma população global, sendo deixada para uma próxima oportunidade a análise de instrumentos de estatística inferencial, ou seja, de abordagens que permitem a avaliação de uma população por meio de coleta de dados sobre uma amostra dessa população.
1.1 Pesquisa observacional vs. pesquisa experimental
Estudos estatísticos observacionais são aqueles realizados em ambientes não controlados pelo pesquisador. Os dados analisados originam-se de fenômenos naturais ou de contextos da vida real. Não há intervenção direta do pesquisador na realidade observada. O pesquisador limita-se a observar a realidade, o que evidentemente envolve esforços ativos de busca, organização e interpretação de dados (que envolvem algum grau de subjetividade e arbitrariedade), mas não de intervenção ou manipulação da realidade. É o caso dos estudos na maioria das ciências sociais, inclusive quando há observação de instituições políticas e jurídicas.
Estudos estatísticos experimentais, ao contrário, desenvolvem-se em ambientes criados ou controlados pelo pesquisador. O pesquisador deve criar o ambiente laboratorial ou desenhar uma situação artificial para poder chegar a conclusões válidas. É o caso de estudos das ciências médicas, por exemplo, quando há atribuição aleatória de drogas para constatação de seus efeitos em grupos distintos. É geralmente o caso também de estudos laboratoriais ou experimentos físicos, e em parte de estudos de comportamento psicológico.
1.2. População e amostra: estatística descritiva vs. inferencial
Uma distinção fundamental da estatística é aquela entre população e amostra. A população é o objeto integral de uma análise. Um estudo observacional pode querer descrever as preferências eleitorais de todos os eleitores de um país. Um estudo experimental pode querer compreender se homens entre 35-50 anos são mais sujeitos aos efeitos colaterais de uma droga que mulheres nessa idade, ou vice-versa. Os eleitores e os homens e mulheres na referida faixa etária são a população de cada pesquisa.
Nesses exemplos, é evidente que não é possível, ou ao menos muito caro e ineficiente, perguntar a preferência de todos os milhões de eleitores de um país, ou realizar experimento com todos os homens e mulheres daquela idade no globo para chegar às conclusões desejadas. Porém, o pesquisador pode desejar avaliar uma amostra, ou seja, uma parcela significativa daquela população que pode ser diretamente observada.
A estatística descritiva é ramo da estatística que permite uma descrição sistemática e precisa dos dados relativos primordialmente a uma população. Os conceitos utilizados na estatística descritiva servem também de base para a estatística inferencial.
A estatística inferencial é o ramo da estatística que descreve os procedimentos de pesquisa e as regras matemáticas que permitirão a consideração de uma amostra como seguramente representativa da população, assim como uma medida da robustez dessa segurança, com análise de conceitos como margem de erro e confiabilidade.
2. Variáveis categóricas e quantitativas
Com relação a cada elemento analisado, podemos definir uma série de variáveis, que são as características que observamos e inserimos nas bases de dados acerca de cada um dos objetos que formam uma amostra ou população.
Nas palavras de Barbetta (2006), as variáveis são "as características que podem ser observadas (ou medidas) em cada elemento da população, sob as mesmas condições", como “sexo”, “número de processos” ou “tempo entre autuação e julgamento”.
Essas variáveis podem ser de dois tipos principais:
Variável categórica, também chamadas de atributos, qualidades, dimensões ou variáveis qualitativas. Essas variáveis normalmente decorrem de classificações acerca dos objetos analisados. Elas podem ser
- nominais: quando os atributos não possuem ordem entre si (como a classe de um processo, que pode assumir valores como "ADI", "ADPF"ou "MS") ou
- ordinais: (quando a classificação utiliza atributos organizados em uma ordem definida, como as instâncias jurisdicionais ("1º Grau", "2º Grau", "2º Grau") ou tipos de requerente (por exemplo "Grande Porte", "Médio Porte", "Pequeno Porte" ou "Unitários").
Variável quantitativa, também chamadas de medida, que apresente valores numéricos. Podem ser:
- contínuas: admitindo números fracionários dentro de um certo intervalo, como nas medidas de "tempo de tramitação" ou de "tempo de julgamento do recurso") ou
- discretas: quando há valores finitos (como o número de votos divergentes) ou apenas valores inteiros (como o número de incidentes processuais).
Um ponto a ser observado é que o número de um processo não é uma variável numérica, mas uma variável qualitativa, pois trata-se de um nome. A ADI 333 tem esse nome, pelo qual ela pode ser acessada. Trata-se de um nome ordinal, na medida em que indica que uma ação foi protocolada posteriormente a outra, mas não se trata de um número porque esses dígitos não designam uma quantidade que possa ser operada matematicamente. Medidas pode ser somadas, podem ser subtraídas, podem ser multiplicadas, e não faz sentido fazer essas operações com o número que faz parte do nome de uma ação determinada.
É importante ressaltar que uma mesma característica pode ser avaliada de forma qualitativa ou quantitativa, tendo em vista o objetivo da pesquisa. Quando analisamos o perfil dos demandantes em controle concentrado, podemos atribuir a cada um um número de ações ajuizadas, mas também podemos criar classificações que convertam esse número em dimensões qualitativas (como "Grande Porte" ou "Pequeno Porte").
2. Medidas de tendência central
Uma das principais formas de descrever dados quantitativos de uma maneira precisa e comparável é pelas medidas (ou parâmetros) de tendência central, ou seja, do centro da distribuição dos dados. Pensemos, por exemplo, nas medidas relativas ao tempo de duração de um processo, que se prestam à realização desses cálculos.
2.1 Média aritmética (mean) - M
A média aritimética xprime o resultado da soma de todos os valores (data) pelo número de elementos (data points). No conjunto de dados:
1, 2, 2, 4, 6, 9
a média M será a soma de todos os elementos (1 + 2 + 2 + 4 + 6 + 9 = 24) dividida pelo número de elementos na sequência de dados (6), ou seja, 24 / 6 = 4.
Trata-se de uma medida intuitiva do centro de distribuição dos dados, como um centro de massa dos valores. Porém, essa medida não é robusta (estável) porque ela é sujeita a variações drásticas decorrentes da existência de pontos muito fora da curva (chamados de outliers).
Alguns poucos valores muito altos ou muito baixos podem distorcer a média, que em vez de apresentar um valor típico do conjunto analisado, termina retornando um valor muit odistante deles. Por exemplo, analisando o tempo de julgamento dos processos em um certo mês, podemos chegar aos números (em anos):
1, 2, 2, 4, 6, 19
Seria verdadeiro afirmar que a média desses valores seria de 5,7 anos, mas essa média decorreria basicamente da presença de um outlier, sendo falso afirmar que normalmente são julgados processos com cerca de 6 anos de tramitação. A média é uma medida, mas o fato de ela ser suscetível a outliers não permite que possamos extrair sempre informações úteis a partir do cálculo da média de uma sequência de números.
2.2 Mediana (median) - Md
Em casos como o descrito acima, utilizar a média seria uma estratégia problemática, sendo mais razoável usar estratégias mais robustas quanto a outliers, como é o caso da mediana.
Mediana é o número que se encontra no meio de uma sequência de dados numéricos, de forma que metade dos valores (aproximadamente) se encontrará abaixo da mediana, e a outra metade acima da mediana. Em:
1, 1, 3, 4, 7, 8, 10
o número 4 corresponde à mediana, pois há três valores acima e três valores abaixo de 4. Quando o número de elementos é par, a mediana corresponde à média aritmética dos dois números do meio. Em:
1, 1, 3, 5, 7, 8, 8, 10
o número 6 corresponde à mediana, pois é a média aritmética de 5 e 7.
Note embaralhando os números dessa mesma sequência, como em:
10, 1, 1, 3, 5, 8, 8, 7
a mediana continua sendo 6. Isso porque os valores numéricos devem ser colocados em sequência ordenada, e apenas então será calculada a mediana.
A mediana é uma medida robusta (estável) do centro, pois ela não é sensível a pontos fora da curva. O valor mediano não muda se as extremidades se alteram (imagine o número 5433 no lugar do número 10 - a mediana seria a mesma, já a média se alteraria radicalmente).
É possível visualizar essa diferença entre a média e a mediana pela representação a seguir:
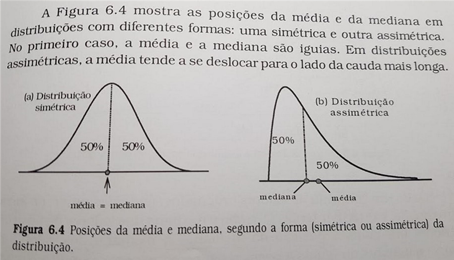
2.3 Moda (mode)
A moda corresponde ao valor mais frequente do conjunto de dados. Em:
23, 23, 24, 27, 27, 27, 27, 31
a moda corresponde a 27.
Uma sequência numérica pode ter mais de uma moda quando há mais de um valor igualmente frequente (sequência bimodais, ou multimodais). Uma sequência pode igualmente não possuir moda, caso nenhum valor se repita mais frequentemente que os demais.
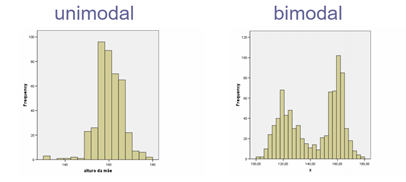
3. Medidas de localização relativa
As principais medidas de localização relativa de valores numa sequência de dados são: valor mínimo (ou extremo inferior), valor máximo (ou extremo superior), quartil e percentil.
3.1 Quartis e distância entre quartis (IQR)
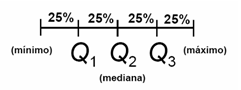
Cada quartil (Q1, Q2, Q3) representa uma divisão da amostra ordenada em quatro partes iguais. Assim, 25% dos valores se posicionam abaixo do valor Q1 (primeiro quartil), 50% abaixo de Q2, e assim por diante. Segue uma representação dos quartis em relação a um gráfico de distribuição dos dados:

Note que um quartil é um valor, um ponto na sequência de dados, e não uma área. Assim, a proporção entre quartis pode não ser (e frequentemente não será) exatamente de 25% por quartil, a depender da distribuição dos valores na sequência de dados.
Note também que Q2 corresponde à mediana da sequência de dados. Já Q1 e Q3 são as medianas da primeira metade e da segunda metade dos dados, respectivamente.
Veja que, estando em posse simplesmente de informações sobre a mediana, os extremos e os quartis, é possível se ter uma ideia razoável de como os valores se distribuem em uma sequência de dados. Veja:
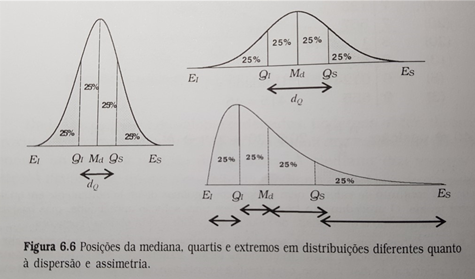
Um parâmetro essencial da estatística descritiva é a distância entre quartis (ou IQR, interquartile range). O IQR é a diferença entre Q3 e Q1 (ou seja, a soma do número de elementos contidos no Q2 e no Q3). No intervalo entre Q1 e Q3, encontram-se 50% dos valores da sequência de dados.
3.2 Percentil (percentile)
É um parâmetro que descreve a proporção de valores que estão abaixo do percentual referido. Assim, o trigésimo percentil é o valor abaixo do qual encontram-se 30% dos dados coletados, e acima do qual encontram-se 70% dos dados coletados.
4. Medidas de dispersão
As medidas (ou parâmetros) de dispersão funcionam como indicadores das tendências de distribuição dos dados quantitativos, ou seja, se os dados se concentram em torno de um ou mais centros, se os dados se espalham, se a distância média entre os dados é maior ou menor, etc. Além da distância entre quartis (IQR), que já estudamos, vejamos outras medidas comuns: a amplitude e o desvio padrão.
4.3 Amplitude (range)
A amplitude é a diferença entre o maior e o menor valor de um conjunto de valores. A amplitude da sequência
10, 1, 1, 3, 5, 8, 8, 7
é a diferença entre o valor mínimo (10) e o valor máximo (1), ou seja, 9.
4.4 Desvio padrão (STD) e variância (variance)
O desvio padrão (standard deviation, ou STD) é uma medida importante para avaliar quão espalhados estão os valores de uma sequência de dados, com relação à média. Assim, quanto maior o desvio padrão, mais distantes os valores tendem a estar uns dos outros.
O desvio padrão é calculado de forma a conferir especial peso à existência de valores muito distantes da média e, por isso, ele não corresponde simplesmente à média das distâncias entre os valores individuais e o valor médio, mas é calculado a partir de uma elevação de cada uma dessas distâncias ao quadrado, cálculo esse que tem uma dupla função:
- gerar sempre valores positivos (porque não interessa se a distância é para cima ou para baixo da média) e
- ao multiplicar a distância por ela mesma, as distâncias maiores adquirem especial peso no cálculo do desvio padrão.
A média das distâncias elevadas ao quadrado gera a medida que chamamos de variância. Trata-se de uma medida menos usada na estatística descritiva porque a variância oferece resultados maiores do que o da escala dos valores (justamente por estar elevado ao quadrado). Mas esse é uma medida usada nos modelos de estatística inferencial, como parte do cálculo dos intervalos de confiança, por exemplo.
Para retornar a variância a um range comparável com o dos valores individuais, o mais típico é calcular a raiz quadrada (operação inversa à elevação ao quadrado) da variância, que nos oferece justamente o desvio padrão.
Em resumo, o desvio padrão corresponde à raiz quadradada variância, e ele nos oferece um valor que é comparável aos valores originais e à sua média.
Para ter uma ideia do tipo de valores que são gerados por essa análise, observemos a seguinte sequência:
1, 3, 5, 7, 14
Número de elementos = 5
Média aritmética entre os elementos = 6
Se calcularmos a média das diferenças entre o valor individual e o valor médio, teremos a média das distâncias, que é chamada de Desvio Absoluto da Média:
Média das distâncias = [ (1-6) + (6-3)+ (6-5) + (7-6) + (14-6)] / 5
Média das distâncias = Desvio Absoluto da Média = 3,6
Esse cálculo nos sugeriria uma faixa típica de distribuição entre 2,4 (6-3,6) e 9,6 (6+9,6). O desvio padrão nos oferece uma faixa mais ampla, na medida em que, ao somar os quadrados, os intervalos maiores têm mais impacto no valor resultante da média.
Variância = [ (1-6)2 + (3-6)2 + (5-6)2 + (7-6)2 + (14-6)2 ] / 5
Variância = 20
Desvio padrão = √20 = 4,47
Como ler essa informação? Sabendo que a média dos valores da sequência é 6 e o desvio padrão é 4,47, podemos intuir que os elementos típicos dessa sequência estarão na faixa de valores que vai de 1,53 (6 - 4,47) a 10,47 (6 + 4,47 ). Também sabemos que tipicamente (mas não necessariamente) existem valores fora dessa faixa.
Quando o desvio padrão corresponde a um valor várias vezes superior à média, podemos saber que existe uma dispersão muito grande dos valores. Observem, por exemplo, o seguinte gráfico, baseado nesta base de dados sobre as partes das ADIs e ADPFs, que indica o número de ADIs e ADPFs ajuizadas por cada um dos requerentes, que tem como Média 5,5 e como Mediana 1 e desvio padrão de 35.
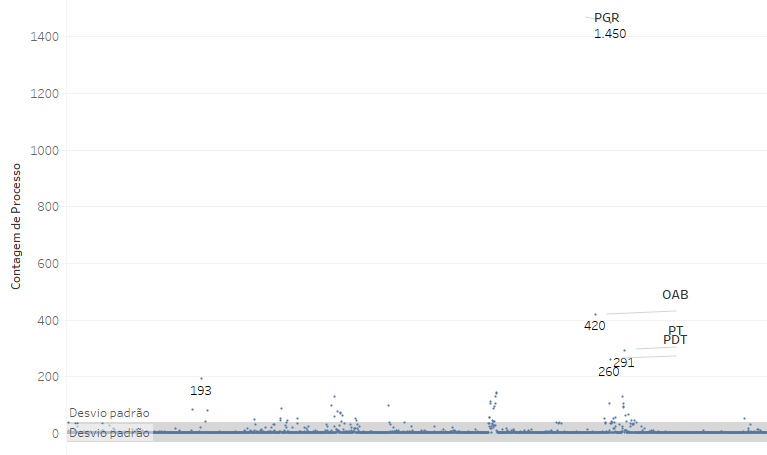
O gráfico mostra que a grande maioria dos valores e muito baixa, mas que existem alguns valores especialmente altos, como os da PGR, da OAB, do PT e do PDT. Embora a mediana dos valores seja 1 (o que indica que a maioria das partes ajuizaram apenas uma ADI), a Média é 5,5.
Somente 2,3% das partes (53 partes das 2266 que ocorrem nesse universo) estão fora do desvio padrão, mas a existência de alguns valores aberrantes (como o caso da PGR, que corresponde a 284 vezes a média) eleva substancialmente a média e gera um desvio padrão que é mais de seis vezes superior ao valor da média.
Essa distribuição gera um gráfico em que os valores ficam tão concentrados que ele é melhor observado em uma escala logaritmica, e não linear. Nesse tipo de escala, veja que a passagem de cada marca no eixo não indica uma variação linear (que soma mais uma unidade), mas uma progressão geométrica, que no presente caso multiplica os valores por 2 a cada marca.
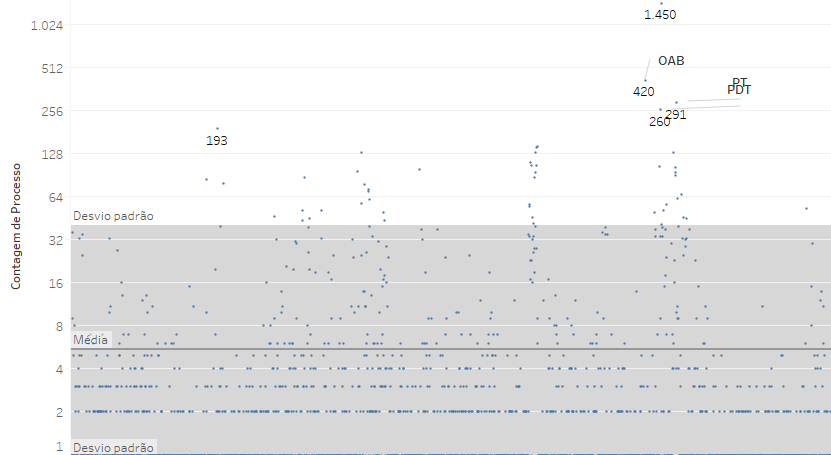
Essa visualização deixa mais clara a dispersão dos valores dentro da faixa definida pelo desvio padrão. 75% dos atores ajuizou apenas uma ou duas ações e cerca de 16% ajuizou entre 3 e 10 ações. Somente 11 litigantes (algo em torno de 0,5%) ajuizaram mais do que 100 processos, e a sua exclusão do universo faria com que a média caísse para 3,8 e o desvio padrão para 10,3, sem que a mediana fosse alterada.
A simples exclusão da PGR já faria com que a média caísse em quase 6%, indo de 5,1 para 4,8, e que o desvio padrão fosse reduzido praticamente à metade, baixando de 35 para 17,5.
Essas variações fazem com que o desvio padrão, como a média, seja uma medida muito sensível a valores aberrantes. Chamamos de robusta uma medida que não é muito afetada por valores atípicos, e de não robusta medidas como a média e o desvio padrão, que são muito alteradas pela existência de certos valores extremos.
Essa falta de robustez não é um defeito da medida, mas uma característica sua, visto que ela é modelada justamente para dar peso especial para valores mais distantes da média. Por isso, caso exista valores muito maiores ou menores que os valores típicos da sequência (como em um desvio padrão de 35, quando a média é 5), o desvio padrão indicará esse fenômeno, sugerindo a necessidade de analisar os valores atípicos e seus significados para a compreensão dos dados.
5. Pontos fora da curva ou valores atípicos/aberrantes (outliers)
Observe a seguinte sequência:
1, 1, 2, 5, 6, 7, 11, 11, 12, 14, 2394
Note que o último valor é ordens de grandeza maior do que os demais valores. Supondo que um pesquisador quer descrever de maneira simples essa sequência de observações, caberá mostrar que o valor típico dessa observação não está próximo de 2394. A descrição da média desses valores terá pouca utilidade nesse caso, mas pode ser ainda útil se o valor atípico for deixado de lado. É o que se chama de ponto fora da curva ou valor aberrante (outlier). Porém, é possível que não seja tão evidente a avaliação de qual valor é aberrante. Veja:
1, 3, 5, 9, 12, 16, 17, 19, 28, 29, 39, 66, 159
É menos óbvio saber se 159, ou mesmo 66 (e porque não 1) são valores não representativos, que distorcem a compreensão da distribuição da sequência de observações do exemplo. Para resolver esse problema, estatísticos definiram uma regra padrão (arbitrária, mas amplamente utilizada) para consideração de um valor aberrante:
Outlier = 1,5 x IQR
Outlier < Q1 - 1,5 X IQR
Outlier > Q3 + 1,5 X IQR
No último exemplo dado, em que há um número ímpar de elementos, a mediana é o número do meio (17), Q1 é a mediana da primeira metade (7,5) e Q3 é a mediana da segunda metade (34):
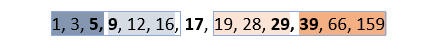
Nesse caso, considerando que IQR é 26,5 (34 - 7,5) e que 1,5 x IQR é 39,75, serão outliers os valores menores que -32,25 (Q1 - 39,75) e maiores que 73,75 (Q3 + 39,75). Portanto, 159 é o único vaor considerado efetivamente como outlier da sequência.
Voltando ao gráfico do número de processos ajuizados por cada requerente, temos que o primeiro quartil é igual à mediana, pois mais de metade dos atores ajuizaram apenas um processo, e o valor do quartil superior (terceiro quartil) é 2, pois 75% dos requerentes ingressaram com até dois processos.
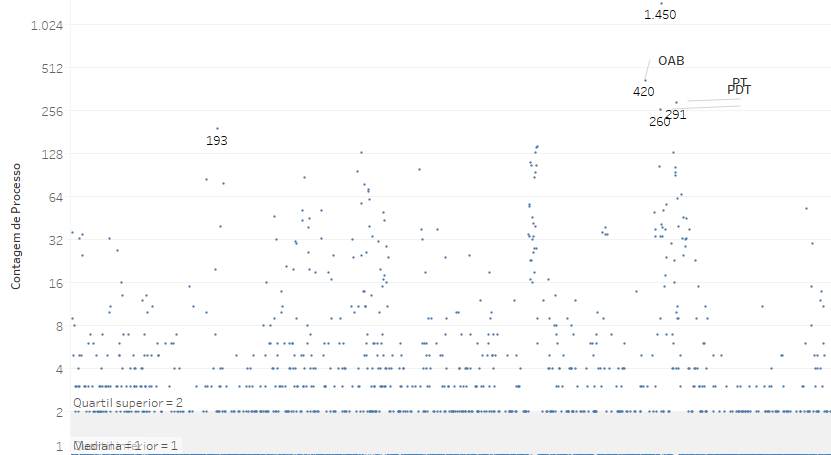
Nesse caso, o IQR é de apenas 1 (2-1), o que faz com que sejam considerados aberrantes todos os valores superiores a 3,5 (1,5x1 + 1), que seriam justamente os 406 atores mais relevantes, pois foram eles que ingressaram com ADIs de modo recorrente.
Na estatística inferencial, é comum que todo valor considerado aberrante seja retirado da descrição dos dados ou, ao menos, representado de forma distinta dos demais. Incorporar tais valores ao modelo pode inviabilizar a possibilidade de inferir, a partir de uma amostra, os atributos de uma população, visto que haverá uma probabilidade grande de que a presença de valores atípicos em uma amostra faça com que ela não seja representativa da população. Como o intervalo de confiança de uma inferência estatística é afetado pela existência de um desvio padrão muito alto, a exclusão de outliers pode ser condição para que os modelos de inferência operem adequadamente.
Esse tipo de exclusão tende a não gerar problemas quando existe um conjunto com centenas (ou milhares) de dados típicos e alguns poucos dados atípicos que podem ser excluídos do sistema, sem inviabilizá-lo. Porém, no caso do universo das ADIs, excluir os casos atípicos seria justamente excluir os dados mais importantes. Nesse caso, é preciso ter um cuidado muito grande com a utilização de estratégias amostrais, mas não faz sentido aplicar estratégias amostrais a um universo do qual fossem excluídos os principais atores.
Tal situação indica que, na estatística descritiva, a exclusão dos outliers deve ser pensada com cuidado, para que eventos relevantes não sejam excluídos do modelo descritivo a ser construído. Nos modelos descritivos das ações judiciais, por exemplo, trabalhamos muitas vezes com um número muito restrito de objetos, que podem ser demasiadamente impactados pela exclusão dos outliers.
Uma situação recorrente, por exemplo, é o fato de Marco Aurélio ser um outlier em toda mensuração sobre graus de divergências entre ministros, o que faz com que esse magistrado seja muitas vezes retirado do modelo, por mais que isso represente a exclusão de uma parcela significativa dos objetos descritos (atores ou votos).
Nesse caso, em vez de simplesmente excluir os outliers, é preciso pensar se não seria o caso de inserir novas classificações, que promovessem uma exclusão desses objetos com base na própria metodologia (e não apenas como uma exigência prática da viabilidade de aplicar modelos inferenciais).
Quando analisamos o número de ações julgadas por mês, por exemplo, chegamos a algumas datas que são outliers e, analisando o que ocorreu, vimos que muitas vezes o que ocorre é o julgamento conjunto de ações idênticas, que são diferentes processos, mas que representam a mesma questão. Com isso, a análise dos outliers pode sugerir alterações na própria classificação, como a mudança da unidade de análise (nesse caso, de ação para questão), para construir um modelo descritivo mais adequado.
Referências
BARBETTA, Pedro Alberto. Estatística aplicada às ciências sociais. 6ª ed. Florianópolis: Editora da UFSC. 2006.