Estatística instrumental: teste de hipóteses


1. Inferências acerca de amostras
De acordo com o teorema do limite central, as médias amostrais de uma população determinada se distribuem de forma simétrica, em torno da média populacional. Essa conformação deve ser percebida como um resultado do fato de que, em amostras suficientemente grandes, espera-se que a média amostral (de qualquer medida) seja sempre um pouco acima ou abaixo da média populacional, em decorrência do caráter aleatório da amostra.
Essa constatação de que as médias amostrais seguem uma curva normal de distribuição nos permite inferir, a partir da regra empírica e considerando que chamamos de erro padrão o desvio padrão da população de amostras, que:
- 68% das médias amostrais estarão a 1 erro padrão da média populacional,
- 95% das médias amostrais estarão a 2 erros padrão da média populacional e
- 99,7% das médias amostrais estarão a 3 erros padrão da média populacional.
Para aprofundar o conhecimento acerca de erro padrão, leia o texto complementar Erro Padrão, Margem de Erro e Z-score.
No texto Estatística instrumental: entre amostras e populações, analisamos o modo como essas constatações nos permitem fazer inferências acerca de uma população, a partir do conhecimento de estatísticas de uma amostra determinada.
Exploramos também a ideia de que os pesquisadores precisam saber, de antemão, qual é o grau de segurança que pretendem atingir com suas pesquisas, pois a definição da margem de erro e do nível de segurança implicam diretamente sobre o tamanho das amostras consideradas suficientes para fazer esse tipo de inferência acerca da população.
Neste momento, exploraremos a estratégia inversa: uma vez que temos conhecimento dos parâmetros populacionais (seja por uma abordagem censitária ou amostral), o que é possível inferir acerca de determinadas amostras?
Em especial, devemos ser capazes de responder à pergunta: será que a diferença entre as estatísticas de uma amostra e os parâmetros populacionais permite afirmar, com segurança, que deve haver fatores específicos que expliquem essa diferença?
Esse tipo de raciocínio é importante porque permite sustentar conclusões que determinadas características de uma amostra (por exemplo, o número de decisões de procedência na amostra de processos ajuizados pelo Ministério público) pode ser considerada como estatisticamente significativa (por exemplo, um índice de procedência acima da média) ou se a divergência de valores mapeada pela pesquisa é insuficiente para projetar conclusões sólidas.
Quando observamos dados quantitativos, vemos várias diferenças, mas é preciso desenvolver ferramentas que possam nos dizer se uma determinada diferença é significativa (e, portanto, sugere a ocorrência de situações que demandam explicação) ou se ela é não significativa (no sentido de ser compatível com o caráter aleatório que toda amostra tem).
É claro que temos de levar em conta que todo subgrupo populacional poderia, potencialmente, ser uma amostra sorteada aleatoriamente. Portanto, qualquer média amostral é possível, mesmo as mais improváveis.
Todavia, quando a média amostral se distancia muito de certa média populacional (aferida por uma pesquisa censitária ou projetada por meio de uma análise amostral), é mais razoável interpretar que essa distância não decorre da aleatoriedade, mas de alguma característica específica do subgrupo analisado.
É possível que você jogue um dado 10.000 vezes e que ele caia 90% das vezes com a face 6 voltada para cima. Porém, a chance de isso acontecer é tão baixa que é mais razoável interpretarmos que se trata de um dado viciado, ou seja, que a nossa amostra de 10.000 lances não deve ser considerada como parte de uma população típica de lançamento de dados, e sim como uma amostra cuja peculiar distribuição não deve ser explicada somente pela aleatoriedade.
A lógica subjacente às estratégias que avaliaremos é a seguinte: sabendo que 95,5% das médias amostrais estão a 2 erros padrão da média populacional, se um determinado subgrupo da população estiver a uma distância maior do que essa (4 erros padrão, por exemplo), poderemos afirmar:
que a chance de que o subgrupo estudado ser uma amostra aleatória da população é de menos de 5% (0,05) e que, portanto, a conclusão é significativa, no nível de segurança de 95%.
1.1 Isolamento de variáveis
Uma vez que você demonstre que determinada amostra se comporta de forma muito diferente do que se esperaria de uma amostra aleatória, você tem um ponto de partida interessante para explorar as causas que levariam a essa média amostral peculiar.
Em fenômenos complexos, descobrir essas causas pode ser um desafio muito grande, mas trata-se de um desafio que pode levar o pesquisador a compreender padrões que não estavam claros anteriormente, fato que pode conferir uma relevância especial para a sua pesquisa.
Por exemplo, você pode escolher uma amostra não-aleatória com os maiores números de uma certa distribuição (por exemplo, os jogadores com maior média de gols ou os juízes com maior número de julgamentos) e depois tentar entender os motivos pelos quais esses pontos estão tão distantes da média. Embora essa abordagem possa ser instigante (quem não quer explicar resultados excepcionais?), ela também pode ser muito ingênua, já que ela parte de um pressuposto que é pouco provável: a existência de um padrão claro que explique os casos excepcionais.
Ocorre que não temos motivos para acreditar que existe um padrão claro, menos ainda um padrão simples, que explique esses desvios da média: muitas causas diversas e independentes podem operar, ao mesmo tempo, para que determinadas pessoas atinjam resultados mais expressivos que a média.
Agrupar resultados excepcionais pode até nos oferecer um fenômeno que pede uma explicação acerca das causas da excepcionalidade. Mas a verdade é que não temos como saber se existe ali um fenômeno que segue um padrão definido, ou se são apenas múltiplos fenômenos que seguem padrões diversos e que, por acaso, geraram aquele resultado peculiar. Pode ser que a excepcionalidade de um jogador ou de um magistrado pode decorrer de uma multiplicidade de fatores independentes, uma rede de interferências tão complexa que elas não se deixam reduzir a um modelo composto por um grupo discreto de variáveis que possamos mensurar.
Pode haver tantas influências genéticas diversas, tantas habilidades diferentes, tantos tipos de treinamento, de conjuntos em que as pessoas estão inseridas, tantos traços psicológicos diversos, tempos de experiência e níveis de motivação, que cada um desses fatores somente seja capaz de explicar uma parte pequena dos objetos que compõem a amostra. Essa multiplicação de fatores, em complexa relação, tende a inviabilizar as tentativas de construir modelos compostos por um grupo pequeno de variáveis relevantes.
Essa dificuldade de explicar a interação complexa de múltiplas causas faz com que a pesquisa científica adote normalmente uma estratégia diferente: isolar amostras nas quais opere um determinado fator, para tentar avaliar em que medida essa variável específica (tempo de experiência, sexo, traços genéticos, etc.) é capaz de explicar a distância entre a média amostral de uma amostra enviesada (que partilha da mesma característica) e o parâmetro populacional (projetado a partir de uma amostra que não é enviesada).
Se você conseguir comprovar que determinada amostra intencionalmente enviesada (por conter somente os elementos que você quer, como uma amostra que contém todas as pessoas que tomaram certo medicamento) apresenta uma média de tempo de recuperação de uma doença bem menor do que uma amostra com pessoas que não tomaram o medicamento, você terá um indício bastante forte de que o remédio funciona.
A amostra das pessoas que não tomaram o medicamento (chamada de grupo de controle) nos permite inferir uma média populacional não enviesada. Mais especificamente, ela nos permite inferir que a média populacional deve estar, com certo nível de segurança, em uma determinada faixa: a margem de erro em torno da média amostral, que estudamos no texto sobre amostras.
Se a média da nossa amostra não-aleatória, que contém os elementos que partilham determinada característica, estiver a mais de 2 erros padrão da faixa de valores em que deve estar a média populacional, nós poderemos concluir (com o nível de segurança permitido pelo tamanho da nossa amostra), que as características peculiares do conjunto que resolvemos estudar provavelmente não decorrem de fatores aleatórios, o que sugere que deve haver fatores específicos que causam a divergência mensurada.
Se você tiver tido o cuidado de isolar amostras que têm uma característica peculiar, você terá segurança bastante grande em afirmar que existe uma correlação entre a característica isolada (ser mulher, ter tomado uma vacina ou ser religioso) e uma determinada medida (número de interrupções em julgamentos, índice de mortalidade por uma doença ou incidência de depressão).
1.2 Pesquisas conclusivas e inconclusivas
Quando você é capaz de isolar uma variável, a regra empírica somente nos permite fazer afirmações seguras sobre ela quando a média amostral do grupo em que ela ocorre se distancia muito da média populacional (medida por uma pesquisa censitária ou projetada por uma amostra aleatória). Se as características da sua amostra estiverem perto da média, você não poderá afirmar nada de muito relevante sobre ela: apenas que os seus dados são compatíveis com uma distribuição aleatória.
Imagine que você gostaria de avaliar se as mulheres juízas são mais interrompidas do que os homens em sessões de julgamento e que sua análise de uma amostra de julgamentos mostra que as interrupções de homens e de mulheres não desviam suficientemente uma da outra para que essa divergência seja considerada significativa, ou seja, para que você possa propor com segurança conclusões decorrentes da regra empírica. A maneira correta de interpretar esse resultado não é concluir que homens e mulheres são interrompidos igualmente:
O seu resultado é meramente inconclusivo!
Essa não é uma estratégia capaz de mostrar que as mulheres têm um nível de interrupção igual ao dos homens, pois a única coisa evidenciada pelo seu trabalho seria que as estatísticas da sua amostra eram compatíveis com um desvio decorrente da simples aleatoriedade.
A regra empírica permite fazer afirmações, com segurança razoável, sobre grandes amostras com médias distantes da média populacional. Ela também nos permite fazer, também com segurança, afirmações sobre eventos complexos cujas médias amostrais são muito distantes das médias populacionais. Aqui é preciso ressaltar novamente: como a estatística lida com fenômenos aleatórios, e não determinísticos, nunca falaremos em certeza. Ela não permite fazer previsões seguras com relação a um fenômeno específico, pois cada um deles é aleatório. O que se pode fazer são afirmações, com diversos níveis de segurança, sobre médias populacionais ou amostrais.
No caso que descrevemos, a regra empírica não nos permite concluir nada acerca dos níveis de interrupção dos homens e das mulheres, porque o fato de ambas as médias amostrais estarem próximas da média populacional faz com que esses resultados sejam compatíveis com o erro amostral (ou seja, com a combinação do caráter aleatório dos fenômenos e do caráter aleatório das amostras).
Por exemplo: se você trabalha com uma margem de erro de 5%, a identificação de 1200 interrupções de mulheres e de 1300 interrupções de homens não seria significativa, pois 1200 deve ser interpretado como uma faixa entre 1140 e 1260, e 1300 deve ser interpretado com uma faixa de 1235 a 1365. Portanto, seus resultados são compatíveis com a possibilidade de que homens e mulheres sejam igualmente interrompidos, 1240 interrupções para cada grupo, na população analisada.
Se a distância entre as médias fosse maior, a sua pesquisa poderia ter sido conclusiva. Se o seu intervalo de erro tivesse sido menor, a pesquisa poderia ter sido conclusiva. Se o nível de confiança exigido fosse de apenas 90%, a sua pesquisa poderia ter sido conclusiva.
Mas devemos convir que, se 95% das amostras possíveis estão dentro da margem de aleatoriedade, é muito provável que a sua pesquisa seja inconclusiva. Essa perspectiva de que a maioria das nossas hipóteses vai gerar trabalhos inconclusivos pode não ser muito animadora, mas é justamente essa tendência a oferecer respostas nulas que confere peso aos seus achados conclusivos.
O teste baseado na regra empírica é rigoroso e tende a gerar respostas inconclusivas, já que a maior parte das amostras possíveis está nessa zona que pode ser explicada pela simples aleatoriedade.
É somente porque é bastante difícil que você consiga mostrar que uma relação é estatisticamente significativa que você pode ter segurança para tomar decisões baseadas em níveis de segurança de 99%, de 95%, ou mesmo de 90%, a depender do quanto você precisa de certeza para justificar suas escolhas.
Bom, isso é difícil em teoria (porque a proporção de amostras fora de dois desvios padrão é pequena), mas a nossa experiência é a de que boa parte dos fenômenos que decidimos explorar é estatisticamente relevante. Uma análise de estatística descritiva pode nos mostrar que a média de procedências, entre os julgamentos realizados em ADIs, é de cerca de 20% para as partes em geral, mas que é de 9,84% para os Partidos políticos e de quase 30% para governadores de estado.
Usando testes estatísticos para mensurar essas divergências, chegamos à conclusão de que elas são estatisticamente relevantes. Porém, a mera observação de uma diferença tão grande (de 50% para mais ou para menos), já nos sugere que essa distância é significativa. Quando lidamos com diferenças tão grandes, a estatística inferencial nos ajudará a ter certeza de que podemos fazer inferências seguras, especialmente quando se tratar de amostras muito pequenas. Esse não é o caso das amostras acima descritas, mas que pode ser o caso de vários subgrupos dessas amostras, como as decisões de um determinado ano ou de um determinado assunto.
Porém, se você chegar a um resultado inconclusivo, não se deixe abater, especialmente quando você tem motivos para crer que existe um padrão nos dados. Pode ser que sua pesquisa tenha sido inconclusiva porque você isolou a característica "ser mulher", quando a interrupção de mulheres talvez seja mais alta apenas em condições específicas:
- colegiados com poucas mulheres;
- diferença grande de idade entre quem interrompe e quem é interrompida;
- interrupção causada por homens com certas características específicas;
Nesse caso, o seu marco teórico pode justificar a utilização dessas amostras mais restritas, que envolvem classificações restritivas. Mas também pode ocorrer de você eventualmente mostrar que os homens são interrompidos quantitativamente tanto quanto as mulheres, mas que o tipo de interrupção dirigida contra pessoas de gênero feminino siga um padrão diferente, o que pode exigir uma classificação de tipos de interrupção (para fazer mansplaining, para convergir, para fazer elogios, para divergir, etc.), no sentido de esclarecer que as mulheres podem ser menos interrompidas, mas que essas interrupções podem ser indício de um preconceito.
Certos recortes podem resultar em resultados nulos por incorporarem vários elementos que alteram a média, mas que podem ser classificados de outras formas. Por esse motivo, a base teórica é tão importante: ela oferece a possibilidade de fazer recortes mais precisos, que evidenciem padrões em alguns tipos de comportamento que não seriam visíveis, se as classificações utilizadas fossem diversas.
Resultados inconclusivos nos remetem a novas pesquisas, que explorem outras redes de categorias, outras descrições, outras formas de segmentar os dados em busca de padrões. Além disso, resultados inconclusivos podem ser suficientes para justificar a narrativa que você pretende construir, especialmente por meio da desmitificação de preconceitos: se você mostrar que não há divergência estatística relevante entre a proficiência de estudantes cotistas e não cotistas, você pode contribuir para desconstruir os discursos que afirmam que as cotas reduzem a qualidade dos profissionais formados pela universidade, por exemplo.
2. Teste de hipóteses
Você deve ter notado que, pelas estratégias baseadas na teoria do limite central (ou seja, do pressuposto de que as médias amostrais seguem uma distribuição normal): nossa única chance de ter respostas conclusivas é negativa:
Nosso único resultado conclusivo resulta do reconhecimento de que a média de determinada amostra é tão desviante que podemos afirmar, com segurança razoável, que ela não deve decorrer de simples aleatoriedade.
Isso faz com que os testes estatísticos sejam voltados a avaliar se é (ou não) razoável explicar certa média amostral a partir do simples erro amostral. Como a maior parte das amostras possíveis está dentro do intervalo de dois desvios padrão, é de se esperar que, na maior parte dos casos, o resultado seja efetivamente inconclusivo.
Na linguagem dos estatísticos, é chamada de Hipótese Nula a hipótese de que o resultado é inconclusivo e que, portanto, os desvios entre a média amostral e a média populacional são compatíveis com o erro amostral previsto.
Como esta é sempre a possibilidade mais provável, os testes estatísticos tendem a partir desta hipótese nula e avaliar se ela é compatível ou não com os dados levantados. Por se tratar da primeira hipótese analisada em todo trabalho, ela é chamada normalmente de H0.
A hipótese nula do seu trabalho é a afirmação de que os seus dados são inconclusivos. Na prática, para boa parte dos trabalhos, ela significa afirmar que as estatísticas da sua amostra estão dentro do intervalo de dois erros padrão, contados a partir da média populacional medida uma pesquisa censitária ou projetada por uma pesquisa amostral.
Compreender bem essa ideia de hipótese nula é fundamental para analisar todo trabalho de estatística inferencial, pois essas são pesquisas que sempre envolvem a avaliação de uma hipótese nula, que é explicitamente identificada no trabalho, porque:
o desafio dos testes estatísticos é justamente o de refutar H0.
Refutar a hipótese nula significa afirmar ser pouco provável que as estatísticas amostrais sejam explicáveis apenas pela aleatoriedade da amostra. Essa refutação abre espaço para que sejam formuladas hipóteses alternativas, começando por H1, que é negação direta de H0:
H1: podemos afirmar, com o nível de segurança permitido por nossas amostras, que existem características particulares dos elementos que formam a amostra analisada, que geram o desvio da média que foi medido no teste.
Uma vez que você tenha isolado adequadamente uma variável na amostra que você analisa, e que você pode afirmar que é pouco provável que a configuração específica dessa amostra seria fruto da aleatoriedade, você pode tirar algumas conclusões e pode gerar novas hipóteses a serem testadas.
Por exemplo, você pode chegar ao resultado de que a rejeição de H0 permite que você indique a existência entre uma correlação entre as variáveis analisadas. Por exemplo, você poderá indicar que existe uma correlação significativa entre uma característica da amostra (ser composta por juízas mulheres, ser composta por ações ajuizadas pela PGR, ser composta por pessoas que receberam uma vacina) e a variação mensurada em uma determinada estatística (número de interrupções em sessões de julgamento, índice de procedência das ações, taxa de mortalidade de uma doença).
3. Correlação não é causalidade!
Uma importante advertência: correlação entre variáveis, sejam elas quais forem e quão forte for a correlação, não implica em reconhecer que uma é causa da outra. Os testes de que falamos até aqui podem mostrar apenas que existe uma correlação entre medidas de amostras formadas por elementos com certas características quantitativas e qualitativas.
Quando você rejeita H0, você não demonstra que a variável isolada causa a divergência mensurada pela diferença entre a média amostral e a média populacional!
Quando você rejeita H0, com alto grau de segurança, você indica uma afirmação mais leve: a de que existe uma correlação entre a presença da variável e o valor da média. Por exemplo, você pode identificar que a diferença entre a média de interrupções de homens e mulheres é significante, em termos estatísticos, pois existe uma correlação entre esses dois elementos.
Porém, identificar que existem mais interrupções de mulheres que de homens não significa necessariamente que as mulheres são interrompidas por serem mulheres. A correlação entre esses fatores é um indício de causalidade (que pode ser explorada), mas ela não é uma comprovação de causalidade.
O seu teste já deu um passo importante: indicar que o número mais alto de interrupções de mulheres não decorre de simples aleatoriedade. Porém, você não tem (ainda) elementos suficientes para afirmar que as mulheres são mais interrompidas pelo fato de serem mulheres.
Existem hipóteses alternativas que precisam ser afastadas para você poder afirmar essa causalidade, como, por exemplo:
- talvez haja uma interrupção maior do gênero que é minoritário em uma corte e que os seus dados indiquem apenas que as pessoas de gênero minoritário são mais interrompidas (sejam homens ou mulheres);
- talvez haja uma interrupção maior das pessoas que defendem certos tipos de posição que são majoritárias entre as mulheres, mas que podem ser presentes também em alguns juízes homens;
- talvez haja uma interrupção maior dos magistrados mais jovens, e as mulheres podem ser, na média, mais jovens que os homens em órgãos colegiados.
Existem outras hipóteses capazes de explicar a correlação que você identificou e, portanto, a rejeição de H0 não pode ser entendida, imediatamente, como uma evidência estatística de que as mulheres são mais interrompidas por serem mulheres.
Como esses fatores podem não ter sido levantados nos bancos de dados, pode ser que a sua avaliação demande pesquisas específicas. Retirar conclusões causais precipitadas é um dos erros que você pode evitar.
Por exemplo, você pode fazer uma pesquisa relevante mostrando que o PGR obtém decisões de procedência em proporção maior do que outros atores. Porém, isso não significa que esse índice mais alto decorra do fato de as ações terem sido propostas pelo PGR!
Pode ocorrer, por exemplo, que as ações da PGR tenham maior índice de procedência porque elas tratem quase todas de certas questões que são jurisprudencialmente assentadas. Assim, a causa do alto índice de procedência pode não ser o fato de a ação ter sido movida pelo MP, mas o fato de o MP mover ações que são tipicamente julgadas procedentes, independente de quem as propõe.
Também pode ter ocorrido de o PGR ter movido centenas de ações similares, que foram todas julgadas procedentes em bloco, e que isso gere uma distorção na média geral de procedências.
O fato de precisar levar em conta hipóteses alternativas, muitas delas pouco evidentes, faz com que a definição da causalidade por métodos estatísticos seja sempre um desafio complexo, cujo exercício ultrapassa os limites deste panorama introdutório.
Mas tampouco devemos subestimar o valor da correlação: correlações fortes permitem identificar padrões estatisticamente relevantes, o que permite fazer boas descrições dos padrões envolvidos em uma população complexa e também permite fazer avaliações qualitativas de potenciais relações de causalidade, quando a correlação é estatisticamente relevante.
4. Significância estatística: o valor p (p-value)
Para compreender a mecânica envolvida no teste de hipóteses, convém que você compreenda alguns conceitos fundamentais, que são discutidos no texto de aprofundamento: Erro Padrão, Margem de Erro e Z-score (Costa e Amorim, 2021).
Porém, o conceito incontornável para entender as publicações que usam estatística inferencial é o de valor p, que é o mais usado nos trabalhos que envolvem metodologias quantitativas.
Testes estatísticos de hipótese envolvem a avaliação da compatibilidade entre os seus dados e a hipótese nula (H0).
O valor-p é crucial porque ele indica a probabilidade de que H0 (hipótese nula) seja verdadeira.
Já vimos que é você que estabelece o grau de confiança da sua pesquisa (tipicamente de 95%), e o valor p nos oferece uma medida para saber se, a partir da amostra colhida, é possível fazer afirmações estatisticamente significantes acerca da população.
O valor-p (p-value) é justamente a chance de que a hipótese nula seja compatível com a distribuição normal dos dados. Esse valor poderia até vir escrito em termos percentuais (1%, por exemplo), mas o modo típico de expressá-lo é com valores decimais (como 0,01, que é 1/100).
Quando o valor da média amostral está mais de dois erros padrão (ou seja, mais de dois desvios padrão da população de amostras) distante da média populacional, o valor-p será de menos de o,05 (ou seja, de menos de 5%), porque somente cerca de 5% das amostras aleatoriamente geradas a partir de uma população estão fora desse intervalo.
Como o nível de segurança tipicamente estabelecido pelas pesquisas é justamente de 95%, esse valor-p de 0,05 significa que existe apenas 5% de chance de a sua média amostral estar a mais de dois erros padrão da média populacional. Isso significa que, normalmente, um valor-p de 0,05 significa que foi alcançado o patamar normalmente exigido para que seja seguro rejeitar H0.
Para sermos mais precisos, o valor p será de 0,05 quando a média distar mais de 1,96 erros padrão, pois 2 erros padrão é o patamar para 95,5% (e não 95,0%).
O valor p não é calculado para você definir o tamanho da sua amostra, mas é calculado a partir das medidas que você obtém em suas amostras, estando diretamente ligado à medida (em erros padrão) da distância entre a média amostral e a média projetada para a população.
Existem várias estratégias para calcular o valor p, que terão pontos de partida diversos. Nossa sugestão é a de que vocês utilizem a Omni Calculator, que tem as calculadoras que usamos até aqui e que também tem uma Calculadora específica para gerar o valor p por meio de um cálculo da pontuação z (pontuação essa que corresponde à distância entre a média amostral e a média populacional, medida em erros padrão).
Se você observar o cálculo contido nesta calculadora para o Z-score, ele é exatamente uma divisão em que o numerador é a diferença entre a média populacional e a média populacional projetada e o denominador é o erro padrão amostral, tal como explicitado no texto Erro Padrão, Margem de Erro e Z-score.
Para explorar os usos dessa calculadora, vamos usar um exemplo de pesquisa com dados reais. Suponhamos que você decida avaliar quantos andamentos têm, em média, as ADIs e ADPFs ajuizadas no STF. Essa é uma informação que pode servir como medida indireta da complexidade do trabalho de julgamento ou do tempo dedicado pelo Tribunal ao julgamento de uma questão.
O tempo de tramitação é um indicador interessante, mas que tende a dar demasiado peso ao tempo em que uma ação fica parada, sem qualquer atividade jurisdicional efetivamente em curso. Certas ações que ficam "congeladas" por longos períodos e terminam sendo julgadas de forma simples, pelo reconhecimento da prejudicialidade. Nessa situação, o número de andamentos pode servir como base para algumas conclusões interessantes acerca dos processos.
Combinando uma base de dados adaptada do artigo Evolução do perfil dos demandantes no controle concentrado de constitucionalidade realizado pelo STF por meio de ADIs e ADPFs (Costa e Costa, 2018), com uma base que contém o número de andamentos dos processos em 2021, chegamos ao seguinte gráfico do número de andamentos dos processos ajuizados até o fim de 2016 e que, portanto, tiveram tempo suficiente para se desenvolver. Para observar os gráficos, convém que você baixe diretamente o arquivo do tableau TesteDeHipótese.twbx.
Note que o Tableau permite que você grave dois tipos de arquivo. Os .twb, que são menores, mas que precisam extrair os dados dos arquivos que você indicou na fonte. Já os .twbx são maiores, pois contém os dados necessários para plotar os gráficos. Se você precisar enviar para alguém apenas as imagens, pode usar o .tbw, mas se você quer enviar os dados juntamente com os gráficos, é preciso usar o formato .twbx.

Esse gráfico tem alguns outliers acima de 500 andamentos, que ocultamos desta exibição para facilitar a observação dos dados (mas que não excluímos dos cálculos). Os parâmetros dessa população de processos são contidas no seguinte quadro resumo, extraído do Tableau:
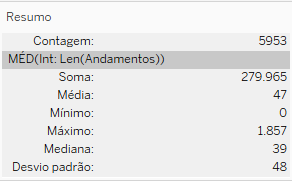
Essa é uma população que contém dados de ações que impugnam atos federais e outros que impugnam atos estaduais ou municipais. Uma das teses sustentadas no artigo de Costa e Costa é que seria importante segmentar atos federais e estaduais/municipais, por eles seguirem padrões diversos de ajuizamento e de tramitação.
Quando segmentamos a população total de processos em dois grupos (os que impugnam atos federais e os outros), os gráficos de caixa dessas duas amostras (não aleatórias) da população mostram estatísticas diversas:
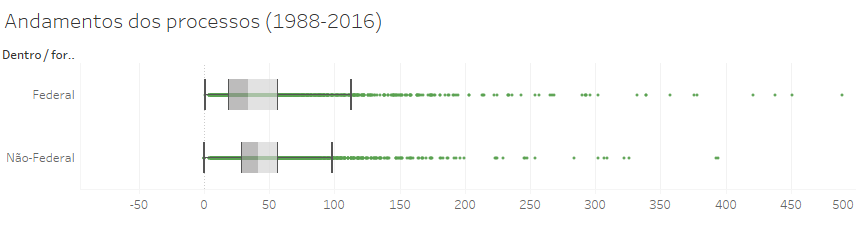
Para avaliar se essa diferença gera resultados estatisticamente relevantes quanto à média de andamentos desses dois grupos (e apenas quanto a essa medida específica), podemos usar a calculadora z-test da omni, que pergunta inicialmente se você conhece o Z-score. Nesse caso, basta indicar que não, e serão abertos os campos para você incluir os elementos que precisa para fazer esse cálculo.

Se você observar no Tableau o cartão de resumo dos dados somente dos processos conta atos federais (o que você pode obter mediante um filtro criado a partir da Origem do Processo), terá o seguinte resultado:
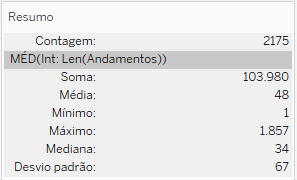
Para fazer o teste basta preencher todos os campos da calculadora, abaixo discriminados:
- Sample mean, que é a média amostral: 48
- Tested mean, que é a média testada, ou seja: a sua H0 será a de que a média amostral corresponde a esta média, que você estabelecerá. A utilidade do teste virá do fato de você definir uma média adequada. De preferência, ela deve ser a média populacional, medida por outras pesquisas (no nosso caso, sabemos que é 47). Se você não tiver a média populacional, precisará fazer uma estimativa a partir de outros parâmetros, como uma amostra aleatória suficientemente grande, de um grupo de controle. Você também poderá utilizar a média amostral, se ela for suficientemente grande para oferecer uma estimativa segura.
- Population standard deviation, que é o desvio padrão populacional. Se você não tiver esse parâmetro, que definirá uma estimativa mais precisa do erro padrão, você poderá usar a estimativa baseada no desvio padrão da amostra. Nesse caso, o mínimo aceitável para o tamanho da amostra é de 30, mas tamanhos amostrais maiores são capazes de tornar o teste mais preciso.
- Sample size, que é o tamanho da amostra.
O resultado será o seguinte:
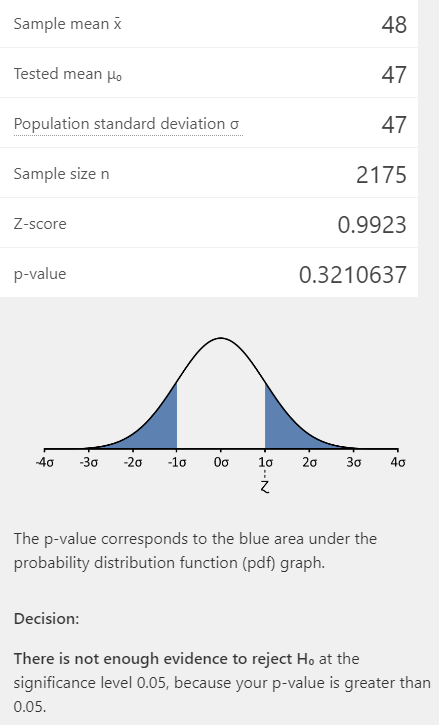
A esta altura, você deve ter sido capaz de ver que o p-value foi de 0,32, o que corresponde a uma chance de 30% de que essa configuração dos dados decorra da aleatoriedade da amostra. Portanto, como indica a última frase da figura acima:
não há evidência para rejeitar H0, no nível de segurança de 95%, a partir dessa metodologia.
Os gráficos anteriores mostram uma diferença perceptível entre algumas das estatísticas das amostras em que se impugnam atos federais, frente à amostra dos atos estaduais, especialmente na mediana e nos quartis. Porém, os testes paramétricos de hipóteses (ou seja, testes baseados na curva normal) se concentram nas médias, que são relativamente próximas nos dois grupos.
O resultado desses testes indica que a diferença nas médias é compatível com o erro amostral, mesmo em se tratando de uma amostra bastante grande, o que aponta para uma pesquisa inconclusiva. Inconclusiva mesmo, pois esse tipo de teste não é capaz de afirmar H1, mas apenas de indicar que não há base suficiente para concluir sobre H0.
Esse resultado não faz com que você se dê por vencida(o) e você resolve buscar padrões em outros tipos de segmentação dos dados, como o número de andamentos dos processos, segmentados por tipos de requerentes (e não por origem do ato impugnado). Esse resultado pode ser visto no seguinte gráfico.
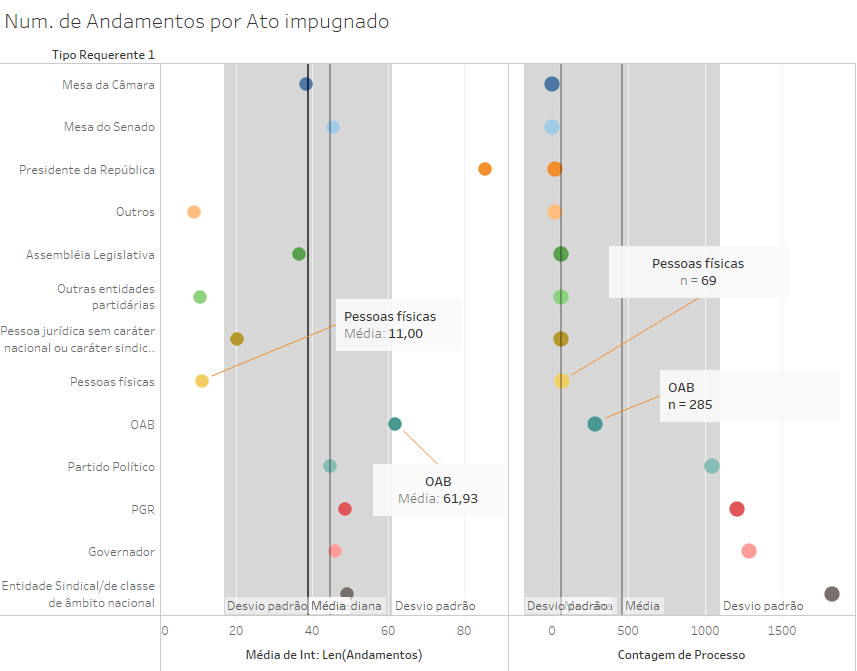
No primeiro painel, podemos ver que alguns tipos de requerentes têm uma média fora da faixa de 1 desvio padrão, com destaque para as pessoas físicas (menor que a faixa), para o presidente da república (com a maior média de andamentos) e a OAB (ligeiramente fora da faixa).
Comecemos analisando a situação da OAB. Uma análise preliminar nos mostra que a OAB é o segundo tipo de requerente com maior média de andamentos, perdendo apenas para a Presidência da República. Ao mesmo tempo, o valor está muito próximo do limite de um desvio padrão, para poder permitir uma conclusão muito clara sobre a significância desse distanciamento. Ao isolar os dados da amostra composta apenas pelos processos ajuizados pela OAB, o Tableau nos oferece esse resultado:
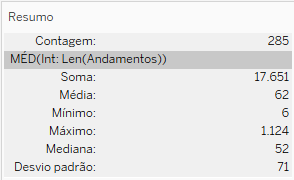
Ao inserir esses dados na calculadora, ela nos retorna que esse resultado é estatisticamente significativo, pois apesar de uma distância baixa com relação.
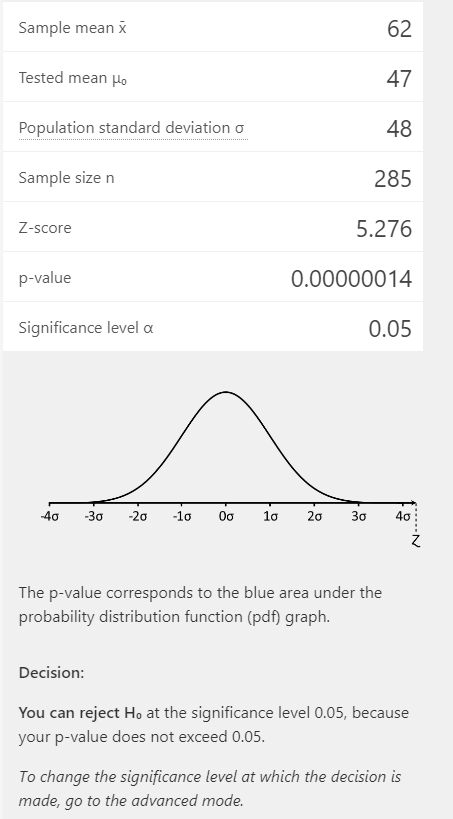
No caso do Presidente da República, a média de andamentos é bem maior (85,6), mas o tamanho da amostra é muito reduzido (apenas 22). Nesse caso, o resultado alcançado também foi estatisticamente relevante (por causa da grande diferença de médias), mas o valor p é cerca de mil vezes maior do que o referente à média de andamentos dos processos ajuizados pela OAB.
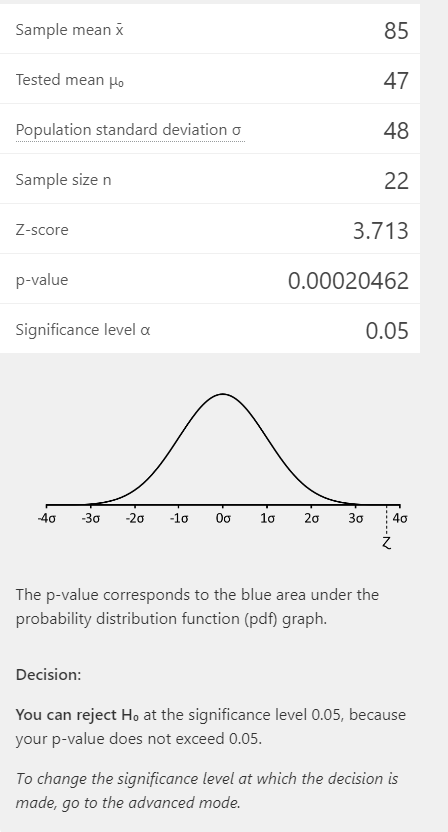
Todavia, devemos ressaltar que os resultados para amostras tão pequenas devem ser lidos com cuidado. Somente foi viável fazer o teste z porque você já conhecia o desvio padrão populacional, o que dava alguma segurança para avaliar a significância estatística da média de uma amostra tão pequena. Normalmente, você não sabe o parâmetro populacional e precisa estimá-lo por meio da do desvio padrão amostral.
Quando você não souber o desvio padrão populacional e a sua amostra for de menos de 30 elementos, você não deve usar o z-test, mas o t-test, modelado para trabalhar com amostras menores e que usa o desvio padrão amostral combinado com uma calibragem adequada para as curvas de distribuição de pequenas amostras. Para usar o t-test, você pode usar a calculadora de teste t, que é bem semelhante à do Z-test, e que retornará um resultado inconclusivo para os dados acima, uma vez que você use o desvio padrão amostral, que é de 106,4.
No caso das pessoas físicas, o tamanho amostral de 69 já permite o z-test (embora com cuidados), mas a média extremamente baixa de 11 conduz a um resultado significativo, com um valor p é tão pequeno que é equiparado a 0.

O caso da Presidência indica que, mesmo com valores médios significativamente altos, o n pequeno torna possível chegar a um resultado inconclusivo, ainda mais quando você tem um desvio padrão alto.
Já no caso das pessoas físicas, a análise estatística corrobora uma análise que decorreria de uma leitura hermenêutica dos dados, pois as médias de andamentos desse tipo de requerentes (manifestamente ilegítimos para ADIs e ADPFs) são previsivelmente menores que a média, o que sugere imediatamente que se trata de um fenômeno atípico.
Já no caso da OAB, a significância estatística é importante porque a distância da média não é tão grande, e o resultado a análise reforça o caráter atípico do número de andamentos da OAB, que é um achado que demanda novas investigações para ser compreendido, mas que pode ser apontado como estatisticamente significante.
Este pode ser um bom começo para uma pesquisa que tente compreender melhor os padrões de ajuizamento da OAB e o modo como isso pode contribuir para um elevado número de andamentos:
- será que essas divergências são explicáveis a partir do número de amici curiae?
- ou será que há muitas idas e vindas dos processos, multiplicando os andamentos sem que isso indique um trabalho jurisdicional mais intenso?
- ou será que esses andamentos decorrem de um alto número de recursos ajuizados?
Neste ponto, você deve ter entendido que a pesquisa segue esse ritmo de observar padrões, avaliar se eles são significativos e formular hipóteses explicativas que possam ser testadas com base nos dados.
5. Teste de hipótese com variáveis binárias
A calculadora do parâmetro Z permite uma avaliação de hipótese quando se trata de avaliar se uma amostra determinada (tipicamente, que tem uma característica isolada) tem uma certa medida diferente da média populacional, que não pode ser devidamente explicada pelo erro amostral.
Um outro teste pode ser feito quando não se trata de avaliar uma média, mas a quantidade de certas ocorrências em uma determinada população. Suponhamos que você decida avaliar a hipótese de que o fato de um processo ser distribuído a um certo Ministro aumenta a chance de esse processo ser julgado procedente.
Nesse caso, a variável dependente não é uma variável quantitativa (medida), mas categórica (dimensão): trata-se de uma classificação acerca do relator. Nesse caso, podemos fazer uma curiosa operação que permite introduzir variáveis categóricas em cálculos de medidas, que é gerar uma variável binária, que converte os valores categoriais em valores numéricos:
1 para a aplicabilidade de uma classificação,
0 para a sua inaplicabilidade.
Essas variáveis binárias, que reduzem categorias a números, são chamadas tipicamente de variáveis dummy. Vejam que elas são muito simples e precisam ser verdadeiramente binárias. Por exemplo, podemos tentar avaliar o índice de procedência e podemos caracterizar a ocorrência de procedência como 1, e a inocorrência de procedência como 0 (o que engloba qualquer resultado que não seja o de procedência).
Não podemos fazer uma divisão em três níveis (procedente como 2, prejudicado como 1, improcedente como 0) porque o resultado prático seria desastroso: uma população de 50% de procedências e 50% de improcedências teria média 1, o que sugeriria 100% de prejudicados. Por esse mesmo motivo, não podemos usar uma classificação em valores 1 e 2, pois a média nos traria informações sem sentido.
Usar 0 e 1 nos oferece um resultado matematicamente correto: a soma dos resultados nos mostraria o número de procedências e a média das variáveis seria a média de procedências em uma amostra ou população. Isso faz com que possamos utilizar os valores da variável dummy em nossos cálculos de médias e desvios, o que permite usarmos a calculadora de z-test para resolver problemas que envolvam uma variável binária.
Por exemplo, podemos nos perguntar se o índice de procedência as ações movidas pelo MP é maior do que índice de procedência das ADIs em geral. Também podemos usar o mesmo cálculo para perguntar se diferenças desse índice de procedência em grupos diversos (por exemplo, comparando as ações de dois Procuradores-Gerais ou ajuizadas em períodos temporais diferentes) é estatisticamente relevante.
5.1 Gerando uma variável dummy no Tableau
Para gerar uma variável dummy, você pode inserir um novo campo no Excel e preencher com 1 as células em que ocorre a categoria mapeada (por exemplo, Resultado Final = Procedência). Porém, para fazer análises no Tableau, é mais fácil gerar essas variáveis binárias por meio da funcionalidade Criar Campo Calculado, como no video abaixo, sendo que o cálculo utilizado foi:
if [Resultado Final]="PROCEDENTE" then 1 else 0 end
Essa expressão condicional é semelhante à do Python, com a diferença que ela vem toda na mesma linha, não precisa de parênteses, e precisa ser encerrada pela função end.
Ela determina que, se o campo resultado final tiver a string "PROCEDENTE", então o resultado será 1. No caso contrário, será 0, o que garante o caráter binário da variável.
Embora variáveis binárias não sigam a curva normal de distribuição, se você tiver amostras suficientemente grandes, os resultados do teste z podem ser significativos, em função do teorema do limite central.
Com isso, você pode criar um gráfico que mede a média geral de procedência e que permite filtrar, facilmente, os processos de apenas um tipo de requerente.
Usando o filtro de tipos de requerentes, você pode selecionar todos (o que vai oferecer os parâmetros da população) e pode também selecionando cada um dos tipos de atores, para obter as estatísticas de cada amostra, para inserir na calculadora de teste z, para verificar se a hipótese nula (de que a média amostral corresponde à média populacional) deve ser mantida ou rejeitada.