Data Mining Judicial 4 - Organizador Básico


1. Introdução
Nos tutoriais anteriores (Extrator Básico e Extrator Intermediário), você deve ter aprendido a desenvolver um programa capaz de coletar dados disponíveis nas informações processuais do STF. Exploraremos agora as formas pelas quais esse conjunto de dados pode ser convertido em um banco relacional, ou seja, em uma tabela na qual todas as informações possam ser identificadas claramente a partir de sua pertinência a uma linha e a uma coluna.
Para iniciar o desenvolvimento dos algoritmos tratados no presente texto, partiremos do Extrator_STF.py, que gravou dados das ADIs 5400 a 5500. A análise desse pequeno grupo de processos permitirá a formulação inicial dos algoritmos de extração, mas depois será necessário fazer testes com amostras ampliadas (primeiro 1000, depois 2500), para testar a consistência dos algoritmos.
A realização do presente tutorial tornará você capaz de realizar 5 atividades:
- Definir um Modelo de Dados;
- Leitura dos arquivos que contém os dados extraídos;
- Extrair os dados definidos no modelo;
- Limpeza dos dados;
- Gravar os dados em uma tabela.
O núcleo do nosso trabalho é articular um modelo de dados (ou seja, uma definição de todos os campos e de seus atributos) com ferramentas de extração precisas, capazes de gerar uma tabela com as informações definidas. Mas não se deve perder de vista que a sequência dessa atividade não é linear, mas circular. Parte-se de um modelo preliminar de dados, que nos faz buscar alguns elementos, mas o tratamento das informações também nos abre espaço para perceber:
- a existência de informações que não esperávamos encontrar, ou
- a inviabilidade de obter alguns dados que pretendíamos extrair, ou
- a necessidade de tratar os dados de formas mais complexas do que o esperado, ou
- a necessidade de estabelecer sistemas classificatórios robustos, capazes de gerar dados mais confiáveis e relevantes.
Por mais que você se dedique a fazer um modelo de dados completo, a execução da extração dos dados sempre envolve algum redimensionamento da estrutura definida, até que fique estabilizado o conjunto das variáveis que serão efetivamente buscadas e os sistemas de classificação que serão utilizados. Assim, é preciso começar traçando um modelo preliminar de dados, que será aperfeiçoado ao longo do processo.
2. Analisando os dados com o Spyder
Para poder definir os campos a serem extraídos, você precisa analisar as informações processuais para identificar que informações estão contidas no código-fonte.
Como a construção dos programas será feita dentro do Spyder, o mais simples é usar as funcionalidades deste IDE para analisar os dados, o que tornará mais fluido o processo de construção do algoritmo.
Teoricamente, você poderia abrir os dados em um editor de tabelas, como o Excel, para fazer essa exploração. Porém, essa abordagem não é indicada por dois motivos:
- A primeira é que, pelas limitações do CSV, gravamos os dados substituindo as quebras de linha pelo símbolo '|', o que gera uma visualização dos dados pouco legível.
- A segunda, e mais importante, é a de que o Excel tem uma limitação do número de caracteres por célula que é ultrapassado pelos campos de alguns processos, como os andamentos de processos com muitas movimentações. Por isso, se você abrir o arquivo no Excel, não estarão presentes os dados completos de células muito grandes (sem aviso de que elas terão sido truncadas) e, se você salvar o arquivo com esse programa, haverá perda de informações.
Para utilizar o Spyder, o primeiro passo é carregar as informações que estão no arquivo, o que pode ser realizado facilmente com a dsd.csv_to_list(), que tem como parâmetro o nome do arquivo a ser aberto. Essa função abre o arquivo e, utilizando-se da biblioteca csv, converte os dados gravados em uma lista e retorna os caracteres '|' para '\n', o que torna as informações mais legíveis.
import dsd
# importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')Um arquivo com este código, e com os demais programas desenvolvidos neste tutorial, estão disponíveis no repertório STF_Organizadores, no GitHub.
Se você rodar esse código, definindo adequadamente o nome do arquivo gerado pelo extrator (no caso usamos o nome 'InformacoesProcessuais.txt', que é gerado pelo programa de extração), ele atribuirá à variável dados o valor de uma lista em que cada linha do csv será uma lista de dados. No exemplo do vídeo abaixo, abri com esse programa um arquivo que contém cerca de 2500 ADIs:
Como se trata de um arquivo grande, o processo de conversão em lista durou alguns segundos e também foi necessário algum tempo de processamento para abrir a janela com o arquivo. Você deve ter visto que é fácil gerar a lista e abrir a variável dados no explorador de variáveis, de forma que você pode selecionar qualquer dos elementos (que correspondem a cada ação) e, dentro de cada um deles, abrir as informações referentes aos processos.
Como os arquivos completos são muito grandes e podem sobrecarregar a sua máquina neste momento, o melhor é começar com um grupo menor de processos, motivo pelo qual fizemos uma extração de apenas 50 ações. Além disso, você pode ter notado que as ações da minha lista não aparecem na ordem exata, pois elas foram gravadas na ordem de extração, que não seguiu exatamente a ordem dos processos.
Então, vamos aprimorar um pouco o código utilizando a função sort(), que coloca os dados em ordem alfabética. Nesse caso específico, utilizamos o sort(reverse = True), que gera uma ordem alfabética decrescente, pois isso mantém o cabeçalho no lugar e deixa as ações mais novas na frente.
Além disso, para evitar uma sobrecarga do seu computador, nessa fase em que serão necessários múltiplos testes para ir ajustando os algoritmos de extração e limpeza das variáveis, é útil restringir o conteúdo do campo dados a um número pequeno de processos. Podemos começar com 50 processos e, quando o algoritmo estiver mais estável, podemos testar com 500 e depois com 2500, para ver se aparecem problemas.
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:51]Gerada essa lista com os dados, precisamos aprender a visualizar tais informações de modo legível. O primeiro passo para isso é dominar bem o explorador de variáveis e conhecer seus limites. Experimente abrir a variável dados (com um duplo clique), o que abrirá uma lista com os elementos que deixamos nesse campo (no programa do vídeo, foram apenas 10 elementos), sendo que cada um deles é uma lista com 25 objetos (os 25 campos gravados por nosso Extrator_STF.py).
Com um pouco de prática, você conseguirá navegar por esses dados de forma eficiente. No vídeo acima, nós abrimos o campo dados (Type:list, Size:10) e, dentro dele, abrimos o primeiro elemento, referente à ADI5500. Trata-se de uma nova lista, desta vez com 25 elementos (de 0 a 24), do qual abrimos o quinto item (ou seja, o item com index = 4, que é uma string com 7819 caracteres).
Esta é uma maneira simples de observar os dados referentes à página de controle concentrado, mas trata-se de uma forma limitada de visualização porque (i) o editor do explorador de variáveis não tem um comando de busca (Ctrl-F) e (ii) o texto aparece todo na mesma cor. Para superar essa dificuldade, e utilizar todas as funcionalidades interessantes do Spyder, sugerimos que você:
- selecione todo o texto da janela (com um Ctrl-A);
- crie um novo documento no Spyder (com o botão New File, ou Ctrl-N);
- cole os dados copiados (com um Ctrl-V).
Essa operação faz com que você consiga visualizar os dados em um formato bastante adequado, dentro de uma janela de edição e comandos de busca (Ctrl-F). Para melhorar a experiência sugerimos que você realize um split horizontal na tela do editor (Ctrl-_ ou clicando nas opções do editor, como mostra o video abaixo), de forma a dividir a tela em 3 segmentos verticais:
- um para o código que você está escrevendo;
- um para os dados em que você está fazendo as buscas;
- outro para o explorador de variáveis.
Sugerimos que você use o Spyder com uma configuração semelhante à que está na imagem abaixo, escolhendo os arquivos que devem aparecer em cada tela (o que pode ser feito clicando nas abas marcadas pelas seta verdes).
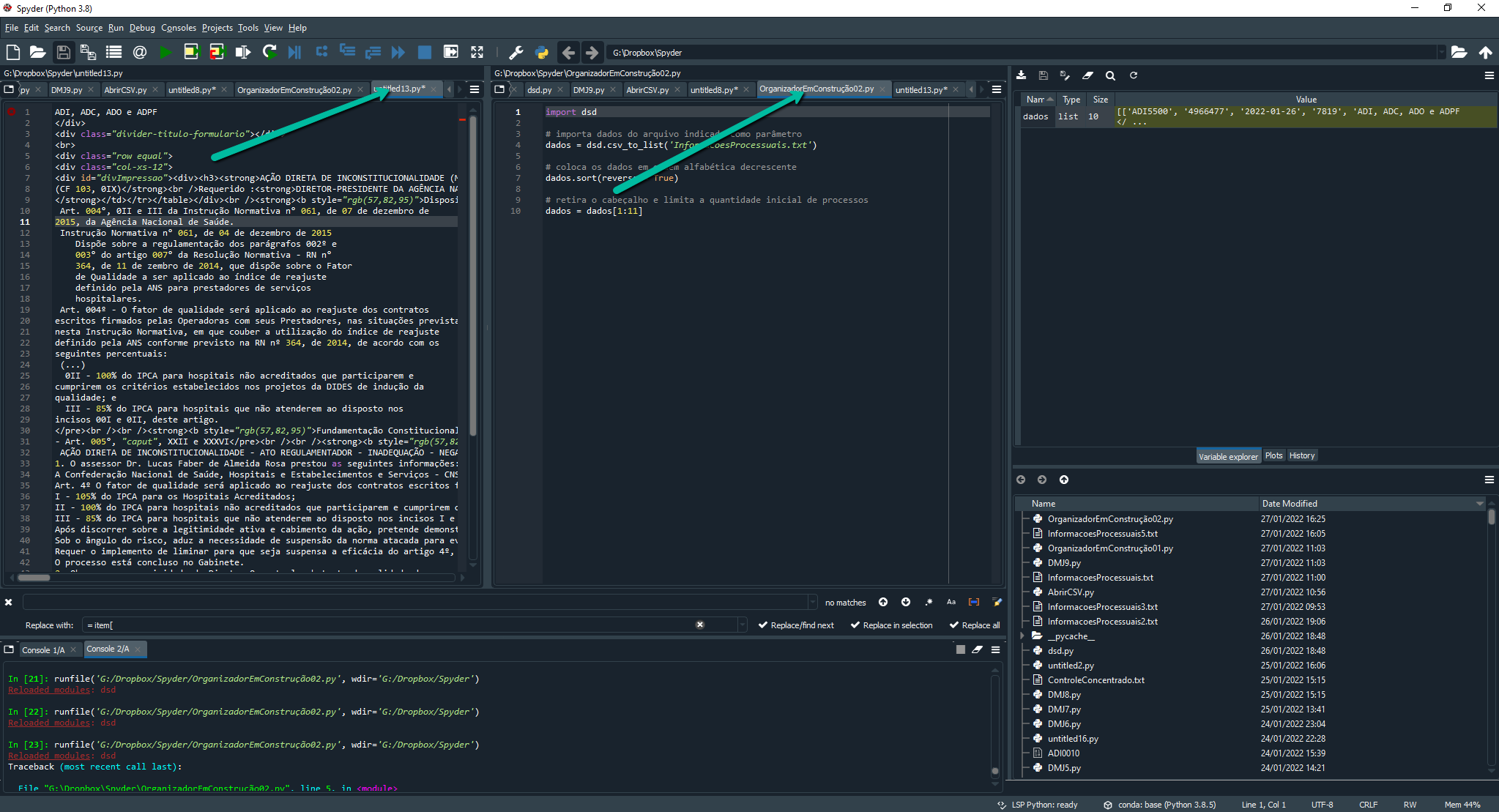
Com essa configuração, você será capaz de observar os dados e definir, de modo eficiente, quais devem ser os argumentos utilizados com a função dsd.extrair(), para extrair exatamente as informações que você deseja.
2. Elementos do modelo de dados
Como discutido no texto Classificações e Marco Teórico, o modelo de dados é uma estrutura em que estabelecemos uma relação entre certos objetos e os atributos que são próprios de cada um deles.
Quando definimos uma unidade de análise (como processos ou decisões), escolhemos uma categoria abstrata, uma classe de objetos. As linhas da tabela correspondem a cada um dos objetos que pertencem a essa classe (cada processo individual, cada decisão particular).
Já as colunas são compostas pelos valores correspondentes a cada um desses objetos. Esses valores seriam constantes, se eles fossem os mesmos para toda a gama de objetos que compõem a unidade de análise. Por exemplo, todas as ADIs são processos que correm perante o STF, o que torna dispensável a catalogação deste dado em um banco de ADIs. Porém, os dados que coletaremos variam de acordo com o objeto mapeado, motivo pelo qual eles são chamados de variáveis.
A primeira linha da tabela não costuma se relacionar a um objeto de análise, mas costuma trazer o nome do campo correspondente a cada coluna: classe, número, data de ajuizamento, relator, etc. Nas demais linhas, aparecem os valores correspondentes ao atributo do objeto mapeado em cada linha (ADI, 2222, 22/02/2020, Gilmar Mendes, etc).
Quando falamos em variáveis, falamos do nome do campo, e não dos valores. 'ADI' e '2222' podem ser valores de um determinado objeto (a ADI2222), mas não devemos incidir na imprecisão de chamar esses valores específicos de variáveis. Variável é uma categoria abstrata, é o nome de um atributo que pode assumir valores que variam entre os diversos objetos mapeados pelas linhas da tabela.
Em resumo, o nosso banco de dados (que, nesse caso, será um banco de dados relacional, que tem a forma de uma tabela) será composto por um conjunto de dados (que são os valores), e o significado desses dados será definido pela sua posição na tabela (a linha definirá o objeto, a coluna definirá qual é o atributo), e o modelo de dados é justamente a forma de organização de toda essa estrutura. Portanto, os principais elementos que você precisa definir são:
- O tipo de objeto que corresponderá a cada uma das linhas (unidade de análise);
- O universo corresponde ao conjunto dos objetos analisados (população);
- O conjunto de objetos que serão efetivamente mapeados (que pode ser a própria população ou uma amostra dela);
- As variáveis correspondem às colunas (atributos a serem mapeados);
- Os tipos de valores que cada variável pode assumir (classificações, números, cadeias de caracteres, datas, etc.).
Para que essa tabela seja de fato um banco de dados relacional, é preciso que todos os dados possam ser acessados a partir da combinação específica entre a linha e a coluna. Por isso, toda coluna deve ter um nome indicando o atributo nela contido, o que afasta colunas sem nome e colunas com nomes idênticos.
No caso da tabela que desenvolveremos, a unidade de análise será processo, pois é com base nesse tipo de objeto que agregaremos as informações, e é com base nessa unidade que os dados já foram gravados na tabela que contém os dados brutos, coletados pelo Extrator.
O universo será todo o conjunto das ADIs (será um levantamento censitário), e, a partir deste momento, vamos analisar os dados em busca de definir quais serão as variáveis mapeadas.
3. Definição preliminar do modelo de dados
3.1 Indicadores
Embora não seja obrigatório, é muito conveniente que a primeira coluna da sua tabela tenha um campo que funcione como indicador, ou seja, que ofereça um nome único para o objeto que é tratado em cada linha. A existência do indicador faz com que haverá uma informação capaz de distinguir cada um dos objetos diferentes na tabela.
Nas nossas tabelas sobre o STF, costumamos usar como identificador a sigla da Classe + o número do processo, com 5 dígitos. Como vimos no DMJ3, o STF utiliza um indicador, que não aparece nas páginas exibidas nos navegadores, mas que é utilizado na estrutura das páginas e que ele chama de incidente.
A existência do indicador tem a grande vantagem de possibilitar que integremos tabelas diferentes, pois teremos certeza de que esse campo apontará especificamente para o objeto que ele designa. Isso permite que sejamos capazes, por exemplo, de articular uma tabela de Partes com uma tabela de Andamentos. Se tivermos uma tabela com as partes de cada processo e outra tabela com os seus andamentos, a existência de um indicador servirá como uma ponte que possibilitará que essas duas tabelas sejam concatenadas em um sistema integrado de informações (um banco de dados).
Para extrair esses dados, com relação a cada processo, precisamos criar uma interação que busque os dados de cada processo, utilizando para isso a já conhecida função dsd.write_csv_row().
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:51]
# Define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
# Cria lista para armazenar todos os dados
dados_totais = []
# Iteração para extrair os dados de cada processo
for item in dados:
# Define campos já individualizados
processo = item[0]
incidente = item[1]
# Define os dados a serem gravados
dados_processo = [processo,incidente]
# Armazena os dados na lista (para facilitar vizualização dos testes)
dados_totais.append(dados_processo)
# Grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,'''processo,incidente''')
dsd.write_csv_row(arquivo,dados_processo)
print (f'Gravado arquivo {arquivo}')Já temos aqui a espinha dorsal do nosso organizador de dados, que oferece a estrutura de para acumulação dos dados de cada ação específica (na lista dados_processo) e para que todos esses dados sejam reunidos (na lista dados_gravar) e gravados em um arquivo único.
3.2 Página do Controle Concentrado
Agora que temos a base do programa de extração, precisamos avançar na análise das várias strings que contêm os dados que serão extraídos.
Vamos começar com a página do controle concentrado, que está armazenada no index 4 de cada uma das listas com os dados dos processos específicos.
As linhas 7 e 8 têm o seguinte conteúdo:
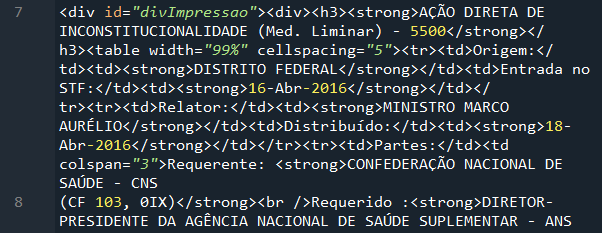
Nesse trecho do código, você consegue encontrar alguns dados importantes:
- Classe: 'AÇÃO DIRETA DE INCONSTITUCIONALIDADE'
- Pedido de liminar: '(Med. Liminar)'
- Número: '5500'
- Origem: 'DISTRITO FEDERAL'
- Entrada no STF: '16-Abr-2016'
- Relator: 'MINISTRO MARCO AURÉLIO'
- Requerente: 'CONFEDERAÇÃO NACIONAL DE SAÚDE - CNS'
- Tipo do requerente: '(CF 103, 0IX)'
- Requerido: 'DIRETOR-PRESIDENTE DA AGÊNCIA NACIONAL DE SAÚDE SUPLEMENTAR - ANS'
Vamos nos concentrar nesses campos pois a sua extração é simples e nos possibilita desenvolver as habilidades e as funções necessárias para extrair as informações restantes. Mas antes disso, pensemos um pouco nos seus atributos.
- Classe: dimensão, range de 40 valores
- Pedido de liminar: dimensão, binário (dummy)
- Número: dimensão (apesar de ser numérico), range de quase 7000
- Origem: dimensão, range de 30 valores
- Entrada no STF: data, dias desde 1988
- Relator: dimensão, range de 30 valores
- Requerente: dimensão, range de quase 1000 valores
- Tipo do requerente: dimensão, range de 9 valores
- Requerido: dimensão, range de quase 1000 valores
Veja que quase todas as informações desse trecho são variáveis categoriais, que indicam atributos do processo. Mesmo campos compostos por numerais (como o número da ação) não são variáveis quantitativas, pois não é possível fazer cálculos a partir deles. Nesse trecho, o único campo que possibilita cálculos é a data de entrada.
3.3 Extração das informações
Se você abrir os dados referentes a outras ações, verá que a estrutura dos códigos de HTML é idêntica, e somente os conteúdos se alteram de uma para outra, o que possibilita definir um algoritmo de extração único para todo esse conjunto de informações.
Como já foi discutido antes, os marcadores que utilizaremos tipicamente envolvem os parâmetros específicos do HTML (sempre entre <>), mas também podemos utilizar textos que se repetem em todas as páginas (como 'Requerente:' ou 'Requerido").
Evite usar, nos marcadores, textos que não façam parte da estrutura da página. Certa vez, utilizem como marcador de início um trecho que continha o texto 'MIN.', que parecia se repetir em todos os casos. Não notei, porém, que, no caso do presidente, não havia abreviação e o texto era 'MINISTRO PRESIDENTE', o que fez com que esse relator não fosse identificado pelo restrator. Repare, em nosso caso, que o trecho 'MINISTRO' da string 'MINISTRO MARCO AURÉLIO' é parte do conteúdo variável da página, e não da sua estrutura (diferentemente de 'Relator' ou 'Origem').
Outra questão que gera uma complexidade é o fato de que os campos Classe, Pedido de Liminar e Número vêm no mesmo trecho do código, o que faz com que seja mais eficiente extrair primeiro esse bloco e depois, de dentro dele, extrair as informações que queremos. Por isso, neste primeiro momento nós trataremos essas 3 informações como um bloco, que será posteriormente decomposto.
Como sempre, existem várias formas de realizar a mesma tarefa, e o código que construímos para isso foi:
import dsd
# importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:51]
# define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
#cria lista para armazenar todos os dados
dados_totais = []
# iteração para extrair os dados de cada processo
for item in dados:
# defindo campos já individualizados
processo = item[0]
incidente = item[1]
# extrai dados do campo html_CC
html_CC = item[4]
cln = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>')
origem = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>')
entrada = dsd.extrair(html_CC,
'Entrada no STF:</td><td><strong>',
'</strong>')
relator = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>')
# define os dados a serem gravados
dados_processo = [processo,
incidente,
cln,
origem,
entrada,
relator]
# armazena os dados na lista (para facilitar vizualização dos testes)
dados_totais.append(dados_processo)
# grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,'''processo,
incidente,
cln,
origem,
entrada,
relator''')
dsd.write_csv_row(arquivo,dados_processo)
print (f'Gravado arquivo {arquivo}')Chamamos de html_CC os dados extraídos da página de controle concentrado, pois foi esse o nome que esse mesmo campo tem no extrator. Com uma definição adequada de marcadores de início e de fim, é possível extrair todos os dados relevantes.
No código abaixo, acrescentamos o restante das informações que podem ser retiradas da página e cuja definição é feita exatamente com a mesma estratégia. A única coisa que mudamos foi chamar todos os campos extraídos de html_CC com o sufixo _CC, para marcar que os dados serão retirados dessa fonte, e não das informações processuais (que serão a origem da maior parte das nossas informações).
Note que definimos uma série de variáveis, com os valores extraídos de html_CC, e que precisamos inseri-las na lista de campos a serem gravados (dados_processo, na linha 80) e que essas informações devem ser copiadas e coladas na linha 101, para que o cabeçalho dos dados fique correto). Para conferir, convém vocês rodarem o programa abaixo e abrirem, no Excel, o arquivo gerado (STF_total.txt).
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:51]
# Define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
# Cria lista para armazenar todos os dados
dados_totais = []
# Iteração para extrair os dados de cada processo
for item in dados:
# Define campos já individualizados
processo = item[0]
incidente = item[1]
# Extrai dados do campo html_CC
html_CC = item[4]
cln_CC = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>')
origem_CC = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>')
entrada_CC = dsd.extrair(html_CC,
'Distribuído:</td><td><strong>',
'</strong>')
relator_CC = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>')
requerente_CC = dsd.extrair(html_CC,
'Requerente: <strong>',
'</strong>')
requerido_CC = dsd.extrair(html_CC,
'Requerido :<strong>',
'</strong>')
dispositivo_CC = dsd.extrair(html_CC,
'Legal Questionado</b></strong><br /><pre>',
'</pre>')
fundamento_CC = dsd.extrair(html_CC,
'Constitucional</b></strong><br /><pre>',
'</pre>')
resultado_liminar_CC = dsd.extrair(html_CC,
'Resultado da Liminar</b></strong><br /><br />',
'<br />')
resultado_final_CC = dsd.extrair(html_CC,
'Resultado Final</b></strong><br /><br />',
'<br />')
monocratica_final_CC = dsd.extrair(html_CC,
'Decisão Monocrática Final</b></strong><br /><pre>',
'</pre>')
indexacao_CC = dsd.extrair(html_CC,
'Indexação</b></strong><br /><pre>',
'</pre>')
# Define os dados a serem gravados
dados_processo = [processo,
incidente,
cln_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_CC,
requerido_CC,
dispositivo_CC,
fundamento_CC,
resultado_liminar_CC,
resultado_final_CC,
monocratica_final_CC,
indexacao_CC]
# Armazena os dados na lista (para facilitar vizualização dos testes)
dados_totais.append(dados_processo)
# Grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,
'''processo,
incidente,
cln_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_CC,
requerido_CC,
dispositivo_CC,
fundamento_CC,
resultado_liminar_CC,
resultado_final_CC,
monocratica_final_CC,
indexacao_CC''')
dsd.write_csv_row(arquivo,dados_processo)
print (f'Gravado arquivo {arquivo}')4. Importando dados do CSV para o Excel
É conveniente gravar dados estruturados, como os produzidos pelo seu organizador, no formato CSV, que já foi tratado de forma panorâmica no Extrator Básico, que já utilizou a função dsd.write_csv_row().
É possível usar outras estratégias de gravação, mas a estrutura do csv é muito legível por outros programas, de modo que ela se mostra uma saída útil para nossos objetivos, que envolverão análise de dados feita pelo Excel (que é amplamente conhecido e consegue fazer uma boa análise preliminar dos dados) e posteriormente pelo Tableau (que é uma ferramenta poderosa para construir gráficos).
Ocorre que, apesar de o csv ser compatível com o Excel, é preciso tomar certos cuidados para que os dados sejam devidamente incorporados a esse programa, que privilegia o uso do seu formato nativo (o .xlsx).
Eu costumava nomear os arquivos gerados pelo programa com a extensão .csv, mas desisti dessa estratégia porque, ao abrir um arquivo com essa extensão, o Excel gera uma visualização inadequada. Se você renomear o STF_total.txt para STF_total.csv e abrir esse arquivo no Excel, o resultado será totalmente inadequado.
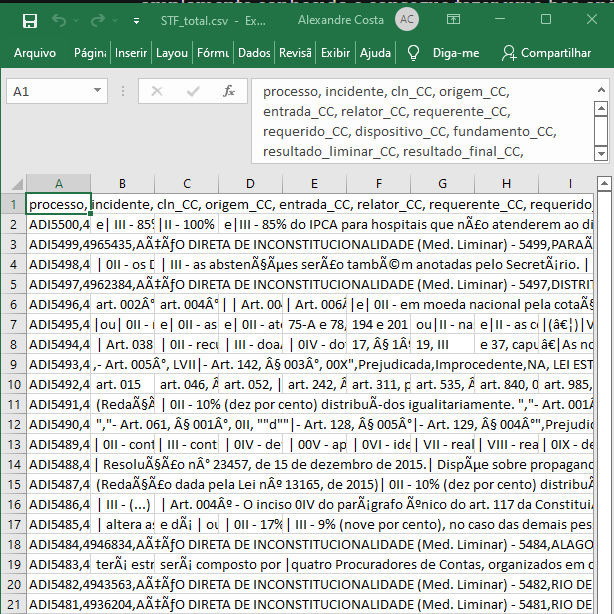
No Excel, você não deve abrir diretamente arquivos .csv, mas pode importar os seus dados usando uma estratégia que funciona tanto para extensões .txt quanto para extensões .csv: criar um arquivo novo e usar o comando de importar dados.
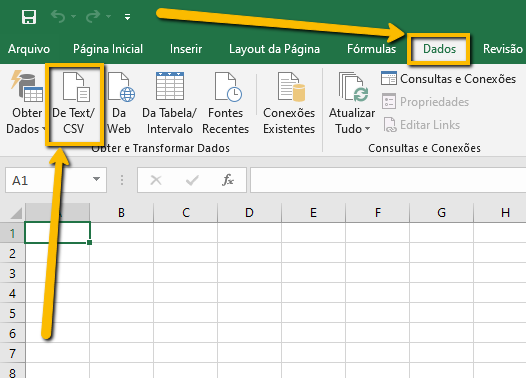
Após clicar no obter dados de text/csv, você terá a oportunidade de definir o encoding, que aparece como origem do arquivo. Nessa opção, o mais correto é o UTF-8, mas selecionar a opção nenhum também costuma funcionar. O que você não pode fazer é deixar na opção padrão (1252: Europeu Ocidental), pois esse encoding é incapaz de ler a acentuação em português.
Como delimitador (separador), você deve indicar vírgula, mas isso não oferece dificuldade porque costuma ser o padrão. Por vezes, ocorre de o Excel sugerir tabulações como delimitadores, o que também acarreta uma leitura errada do arquivo.
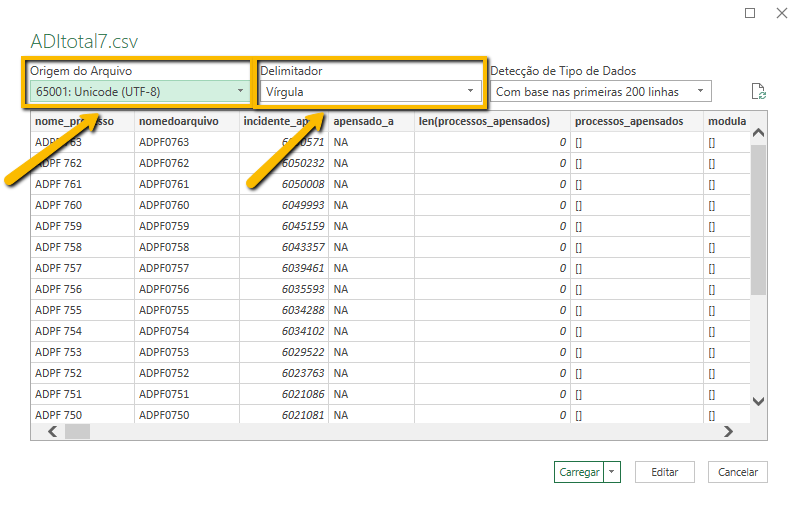
Esse é um modo que funciona e que tem uma vantagem: ele não gera propriamente um arquivo com os dados, mas uma importação que pode ser atualizada, se o arquivo original for modificado. Com isso, quando você ampliar a sua extração, não precisará abrir novamente o arquivo STF_total.txt, bastando atualizar a extração. Por esse motivo, a estratégia de gerar uma importação de arquivos é adequada para essa fase de testes.
A desvantagem desse formato é que a sua capacidade de editar os dados é limitada, além do fato de que esse uso da importação exige conhecimentos que nem todas as pessoas têm. Por esse motivo, optamos por usar a estrutura do CSV, mas por gravar os arquivos com a extensão .txt, que é aberta pelo Excel de uma forma mais intuitiva, o Excel abre uma caixa de diálogo para que você defina os parâmetros de leitura do arquivo txt: o Assistente de Importação de Textos.
A desvantagem de usar o .txt é que, a cada vez que você abrir o arquivo, precisará fazer essa definição: indicar necessariamente que os dados são delimitados por vírgula e que a "origem do arquivo" (nome usado pelo Excel em português para se referir ao encoding) é UTF-8. Convém indicar que os dados possuem cabeçalho, mas o Excel costuma abrir adequadamente o arquivo, mesmo sem essa definição.
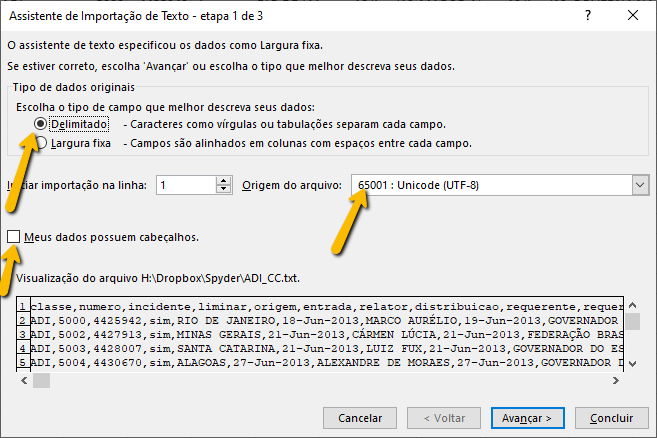
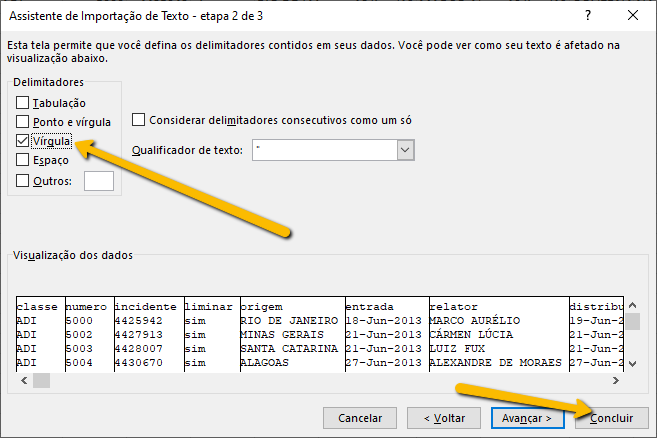
Como estamos em um processo de testes, o mais adequado é que você não abra diretamente o arquivo, mas que use a primeira estratégia: crie um arquivo novo e gere uma extração de dados. Esse modo de trabalho vai poupar você de abrir e fechar o arquivo a cada momento e evitará um erro comum: rodar o organizador sem fechar o arquivo no Excel, o que terminará por gerar um erro de gravação, porque o Python não pode gravar dados em um arquivo que já está aberto em outro programa (no caso, o Excel).
Usando a estratégia de importação dos dados (e não a abertura direta do arquivo), você poderá manter uma janela do Excel aberta para visualizar os resultados (que são bastante legíveis nesse formato) e fazer as adaptações necessárias no código, de maneira bastante fluida.
5. Tratamento e limpeza dos dados da página de Controle Concentrado
5.1 Maíusculas/Minúsculas e acentos
Observando os dados no Excel, podemos notar que eles podem ser trabalhados para que se tornem mais simples e consistentes. Cada campo tem suas peculiaridades, mas alguns pontos podem ser organizados de modo geral, para evitar incongruências.
Em primeiro lugar, devemos ter em mente que os dados do STF não têm uma padronização adequada de maiúsculas/minúsculas nem de acentuação (que por vezes ocorre, por vezes não). Por esse motivo, convém transformar os dados todos em maiúsculas e retirar os acentos, o que reduz a complexidade dos dados.
Você pode transformar todos os caracteres em maúsculos com o uso da função .upper(). Toda string à qual você acrescentar esse sufixo passará a ter todos os caracteres em maiúsculos. O contrário pode ser feito pelo uso do sufixo .lower()
Essa redução de complexidade não gera problemas em variáveis categoriais, mas ela pode reduzir a legibilidade de campos que contém linguagem natural, como o do Dispositivo Legal Questionado.
Seria mais simples alterar diretamente a variável html_CC, mas essa solução parece pouco conveniente porque nosso objetivo era criar um espelho do código-fonte das páginas, o que permite, inclusive, que a análise direta das páginas do STF possa ser um subsídio para a construção dos programas. Alterar o conteúdo desses arquivos faria com que marcadores de início e fim retirados do código-fonte não funcionassem dentro do programa, visto que os códigos HTML normalmente usam minúsculas.
Por esse motivo, consideramos que o mais adequado é fazer essa transformação depois da extração de cada campo, para que cada um deles possa ser tratado conforme suas peculiaridades, como no seguinte código. Note que também expandimos o número de dados analisados para 501, pois podemos identificar a estrutura imutável da página com poucos casos, mas a análise da consistência dos mecanismos de extração exige o trabalho com amostras maiores.
import dsd
# importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:501]
# define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
#cria lista para armazenar todos os dados
dados_totais = []
# iteração para extrair os dados de cada processo
for item in dados:
# defindo campos já individualizados
processo = item[0]
incidente = item[1]
# extrai dados do campo html_CC
html_CC = item[4]
# extrai e trata o campo cln_CC
cln_CC = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>').upper()
cln_CC = dsd.remover_acentos(cln_CC)
# extrai e trata o campo origem_CC
origem_CC = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>').upper()
origem_CC = dsd.remover_acentos(origem_CC)
# extrai e trata o campo entrada_CC
entrada_CC = dsd.extrair(html_CC,
'Distribuído:</td><td><strong>',
'</strong>').upper()
entrada_CC = dsd.remover_acentos(entrada_CC)
# extrai e trata o campo relator_CC
relator_CC = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>').upper()
relator_CC = dsd.remover_acentos(relator_CC)
# extrai e trata o campo requerente_CC
requerente_CC = dsd.extrair(html_CC,
'Requerente: <strong>',
'</strong>').upper()
requerente_CC = dsd.remover_acentos(requerente_CC)
# extrai e trata o campo requerido_CC
requerido_CC = dsd.extrair(html_CC,
'Requerido :<strong>',
'</strong>').upper()
requerido_CC = dsd.remover_acentos(requerido_CC)
# extrai e trata o campo dispositivo_CC
dispositivo_CC = dsd.extrair(html_CC,
'Legal Questionado</b></strong><br /><pre>',
'</pre>')
# extrai e trata o campo fundamento_CC
fundamento_CC = dsd.extrair(html_CC,
'Constitucional</b></strong><br /><pre>',
'</pre>').upper()
fundamento_CC = dsd.remover_acentos(fundamento_CC)
# extrai e trata o campo resultado_liminar_CC
resultado_liminar_CC = dsd.extrair(html_CC,
'Resultado da Liminar</b></strong><br /><br />',
'<br />').upper()
resultado_liminar_CC = dsd.remover_acentos(resultado_liminar_CC)
# extrai e trata o campo resultado_final_CC
resultado_final_CC = dsd.extrair(html_CC,
'Resultado Final</b></strong><br /><br />',
'<br />').upper()
resultado_final_CC = dsd.remover_acentos(resultado_final_CC)
# extrai e trata o campo monocratica_final_CC
monocratica_final_CC = dsd.extrair(html_CC,
'Decisão Monocrática Final</b></strong><br /><pre>',
'</pre>')
# extrai e trata o campo indexacao_CC
indexacao_CC = dsd.extrair(html_CC,
'Indexação</b></strong><br /><pre>',
'</pre>').upper()
indexacao_CC = dsd.remover_acentos(indexacao_CC)
# define os dados a serem gravados
dados_processo = [processo,
incidente,
cln_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_CC,
requerido_CC,
dispositivo_CC,
fundamento_CC,
resultado_liminar_CC,
resultado_final_CC,
monocratica_final_CC,
indexacao_CC]
# armazena os dados na lista (para facilitar vizualização dos testes)
dados_totais.append(dados_processo)
# grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,
'''processo,
incidente,
cln_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_CC,
requerido_CC,
dispositivo_CC,
fundamento_CC,
resultado_liminar_CC,
resultado_final_CC,
monocratica_final_CC,
indexacao_CC''')
dsd.write_csv_row(arquivo,dados_processo)
print (f'Gravado arquivo {arquivo}')Essa organização permite que desenvolvamos os algoritmos de tratamento de cada um dos campos, uma operação na qual você deve se familiarizar com o uso de algumas funções que já foram trabalhadas.
5.2 Campo cln (classe + liminar + numero)
O primeiro fato a ser observado é que, mesmo que existam aqui 3 informações, duas delas são redundantes, pois estão previstas no nome do processo. Extraí-las somente tem sentido como um fator de análise de consistência: para nos assegurarmos de que, ao buscar os dados de uma ação, obtivemos efetivamente as informações referentes a ela. Porém, uma análise preliminar desse bloco de informações, no Excel, permite ter segurança suficiente sobre os dados.
Assim, o único elemento que realmente interessa é a existência ou não de pedido de liminar, que é marcada pela presença do texto '(MED. LIMINAR)' dentro da string.
Uma forma de obter esse resultado é criar uma expressão condicional:
if '(MED. LIMINAR)' in cln_CC:
cln_CC = 'SIM'Em vez de criar uma nova variável, que exigiria uma nova extração (porque toda mudança no número de colunas exige novas extrações), vamos simplesmente mudar para 'SIM' o valor do campo, o que nos permitirá combinar a programação do Spyder com um dos principais instrumentos de análise do Excel: o fitro.
Para dominar essa funcionalidade, execute o código abaixo, que incorpora as mudanças indicadas na linha 40 e também realiza uma redefinição das variáveis no início de cada loop (linhas 24 e 25). Além disso, o código substitui, no campo cln, o texto 'ACAO DIRETA DE INCONSTITUCIONALIDADE' por 'ADI', para reduzir o tamanho do arquivo e para aumentar a legibilidade.
import dsd
# importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# retira o cabeçalho e limita a quantidade inicial de processos
# dados = dados[1:500]
# define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
#cria lista para armazenar todos os dados
dados_totais = []
# iteração para extrair os dados de cada processo
for item in dados:
#redefine variáveis
processo = 'NA'
incidente = 'NA'
# defindo campos já individualizados
processo = item[0]
incidente = item[1]
# extrai dados do campo html_CC
html_CC = item[4]
# extrai e trata o campo cln_CC
cln_CC = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>').upper()
cln_CC = dsd.remover_acentos(cln_CC)
if '(MED. LIMINAR)' in cln_CC:
cln_CC = 'SIM'
cln_CC = cln_CC.replace('ACAO DIRETA DE INCONSTITUCIONALIDADE','ADI')
# extrai e trata o campo origem_CC
origem_CC = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>').upper()
origem_CC = dsd.remover_acentos(origem_CC)
# extrai e trata o campo entrada_CC
entrada_CC = dsd.extrair(html_CC,
'Distribuído:</td><td><strong>',
'</strong>').upper()
entrada_CC = dsd.remover_acentos(entrada_CC)
# extrai e trata o campo relator_CC
relator_CC = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>').upper()
relator_CC = dsd.remover_acentos(relator_CC)
# extrai e trata o campo requerente_CC
requerente_CC = dsd.extrair(html_CC,
'Requerente: <strong>',
'</strong>').upper()
requerente_CC = dsd.remover_acentos(requerente_CC)
# extrai e trata o campo requerido_CC
requerido_CC = dsd.extrair(html_CC,
'Requerido :<strong>',
'</strong>').upper()
requerido_CC = dsd.remover_acentos(requerido_CC)
# extrai e trata o campo dispositivo_CC
dispositivo_CC = dsd.extrair(html_CC,
'Legal Questionado</b></strong><br /><pre>',
'</pre>')
# extrai e trata o campo fundamento_CC
fundamento_CC = dsd.extrair(html_CC,
'Constitucional</b></strong><br /><pre>',
'</pre>').upper()
fundamento_CC = dsd.remover_acentos(fundamento_CC)
# extrai e trata o campo resultado_liminar_CC
resultado_liminar_CC = dsd.extrair(html_CC,
'Resultado da Liminar</b></strong><br /><br />',
'<br />').upper()
resultado_liminar_CC = dsd.remover_acentos(resultado_liminar_CC)
# extrai e trata o campo resultado_final_CC
resultado_final_CC = dsd.extrair(html_CC,
'Resultado Final</b></strong><br /><br />',
'<br />').upper()
resultado_final_CC = dsd.remover_acentos(resultado_final_CC)
# extrai e trata o campo monocratica_final_CC
monocratica_final_CC = dsd.extrair(html_CC,
'Decisão Monocrática Final</b></strong><br /><pre>',
'</pre>')
# extrai e trata o campo indexacao_CC
indexacao_CC = dsd.extrair(html_CC,
'Indexação</b></strong><br /><pre>',
'</pre>').upper()
indexacao_CC = dsd.remover_acentos(indexacao_CC)
# define os dados a serem gravados
dados_processo = [processo,
incidente,
cln_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_CC,
requerido_CC,
dispositivo_CC,
fundamento_CC,
resultado_liminar_CC,
resultado_final_CC,
monocratica_final_CC,
indexacao_CC]
# grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,
'''processo,
incidente,
cln_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_CC,
requerido_CC,
dispositivo_CC,
fundamento_CC,
resultado_liminar_CC,
resultado_final_CC,
monocratica_final_CC,
indexacao_CC''')
dsd.write_csv_row(arquivo,dados_processo)
print (f'Gravado arquivo {arquivo}')Uma vez executado o código, você deve atualizar a extração de dados do Excel, o que vai atualizar a coluna cln_CC. Depois disso, você pode verificar, no filtro, se os valores contidos na coluna são compatíveis com os resultados desejados.
Esse filtro serve para observar os dados, sendo que ele mostra todos os diferentes valores contidos em cada coluna, permitindo que você verifique se todos valores estão todos no range adequado, ou se há valores muito desviantes (como classes com nomes sem sentido ou caracteres estranhos aos campos que deveriam conter somente algarismos).
Nesse caso, a maioria dos valores é 'SIM' e, como era de se esperar, as células em que não ocorre o nome '(MED. LIMINAR)' são casos sem indicação de pedido de liminar (são compostos apenas pela classe e o número). Todavia, seria enganoso já pressupor que nossa expressão condicional funciona para todas as situações, pois ainda é preciso expandir a seleção.
Nesse caso específico, já sabemos que algumas das primeiras ADIs contêm o texto 'MED.LIMINAR' (sem espaço), o que faz com que o nosso condicional, de fato, não seja adequado a todos os casos (somente à maioria). Porém, isso somente ficará claro quando todos os dados forem inseridos no organizador.
5.3 Campo origem
Se você filtrar o campo de origem, verá que ele contém apenas nomes de estados e do DF, além de ocorrências de "NA". Se você isolar apenas os "NA", verá que eles ocorrem em processos vazios, que têm apenas um incidente, o que sugere que se trada de casos com autuação cancelada. Essa utilização do filtro permite, então, localizar valores potencialmente desviantes e identificar os itens em que eles ocorrem, o que permite realizar a conferência necessárias para verificar se os dados estão corretos ou se houve algum equívoco, seja nos próprios dados, seja no algoritmo de extração.
5.4 Campo entrada
O campo data oferece algumas complexidades especiais. Observando os resultados, você verá que há uma combinação de dois formatos diferentes. Alguns usam "/" e oferecem datas compreensíveis para o Excel, mas a maioria utiliza um formato com hífens e uma abreviatura do nome do mês.
Para ajustar esses problemas, podemos iniciar pelo uso de uma função replace(), para trocar os hifens por barras.
entrada_CC = entrada_CC.replace('-','/')Já para ajustar o mês, criamos a seguinte função dsd.ajustar_mes(), que você pode utilizar para ajustar esse campo de data.
def ajusta_mes (string):
string = string.replace('JAN','01')
string = string.replace('FEV','02')
string = string.replace('MAR','03')
string = string.replace('ABR','04')
string = string.replace('MAI','05')
string = string.replace('JUN','06')
string = string.replace('JUL','07')
string = string.replace('AGO','08')
string = string.replace('SET','09')
string = string.replace('OUT','10')
string = string.replace('NOV','11')
string = string.replace('DEZ','12')
return stringVocê deve ter notado que, como a nossa função retorna um valor (a string transformada), o modo correto de incluí-la seria:
entrada_CC = dsd.ajustar_mes(entrada_CC)5.5 Campo relator
No campo do relator, não há motivo para gravarmos a palavra Ministro ou Ministra, motivo pelo qual podemos retirar ambas do valores do campo, o que você já deve conseguir fazer com facilidade usando o replace().
Para não termos de repetir a cada vez o código, sugerimos que você tente fazer essa alteração e execute seu programa para ver se funciona. Em caso de dúvida, consulte a próxima ocorrência do código, um pouco abaixo, nesta página.
Depois de fazer os ajustes, verifique os dados com o filtro de valores, no Excel. E não passe para o próximo parágrafo antes disso, para evitar spoilers.
Você deve ter notado, que ao lado do previsível nome dos ministros, há alguns casos de evidente erro de digitação, o que sugere que esses dados são ingressados manualmente no sistema.
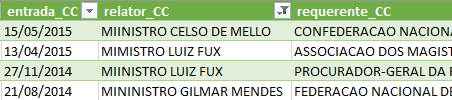
Para ter dados completamente limpos, é necessário ajustar o programa para excluir também esses casos em que a palavra ministro foi grafada de forma errada.
5.6 Campos requerente e requerido
Nesta página, não aparecem todos os atores exibidos na aba de Partes, na página de informações processuais. Por esse motivo, não é preciso extrair daqui o nome das partes. Porém, há uma informação muito interessante nesse campo: o inciso do art. 103 que confere legitimidade ao requerente. Por esse motivo, é útil extrair esse dado, que pode auxiliar a realizar uma classificação dos requerentes.
Uma estratégia para extrair esse dado é usar a função split(), que quebra uma string em duas partes, separadas a partir do marcador definido como parâmetro. No nosso caso, você pode usar um comando como:
requerente_CC = requerente_CC.split('103,')[1]Esse comando quebra a string em duas partes e, por ficar apenas com o segundo elemento, retorna a informação do inciso buscado. Ocorre que esse comando não é muito robusto, pois ele leva a erro nos casos em que não exista na string o trecho '103,', o que leva a lista a ter apenas um elemento, o que gera erro na expressão que busca pelo segundo item dessa lista.
Para evitar esse problema, você pode usar uma expressão condicional do tipo:
if '103,' in requerente_CC:
requerente_CC = requerente_CC.split('103,')[1]Avançamos um pouco, mas quando você rodar o código com essa inclusão, verá que existem dois casos de lançamento dos dados fora do padrão: um '103.' e um '103 ' (sem a vírgula). Como isso pode ocorrer em outros processos (lembre-se que estamos analisando menos de 10% do total das ADIs), sugerimos que você complete o código com uma transformação que regularize essas situações, antes de realizar o split.
requerente_CC = dsd.remover_acentos(requerente_CC)
requerente_CC = requerente_CC.replace('103 ','103,')
requerente_CC = requerente_CC.replace('103 ','103.')
if '103,' in requerente_CC:
requerente_CC = requerente_CC.split('103,')[1]Por fim, esse campo nos oferece a possibilidade de aprender uma outra função de limpeza: a strip(). Sem definir argumentos específicos, ela retira os espaços vazios no início e no fim da string. Se você definir argumentos, ela retira do início e do fim as expressões que você indicar.
Atenção! Para retirar apenas o texto existente no início, use lstrip() (l para left) no lugar de strip(). Para retirar apenas o texto existente no final, use rstrip().
Nesse caso específico, você pode completar a limpeza com 3 strips: o primeiro retira os espaços vazios, o segundo retira os zeros do início (que não fazem sentido com a numeração romana) e o terceiro retira os parênteses do final, limpando definitivamente os dados.
requerente_CC = dsd.remover_acentos(requerente_CC)
requerente_CC = requerente_CC.replace('103 ','103,')
requerente_CC = requerente_CC.replace('103 ','103.')
if '103,' in requerente_CC:
requerente_CC = requerente_CC.split('103,')[1]
requerente_CC = requerente_CC.strip()
requerente_CC = requerente_CC.strip('0')
requerente_CC = requerente_CC.strip(')')5.7 Campo dispositivo
O dispositivo nos oferece desafios específicos, pois se trata de um trecho em linguagem natural, que pode ter strings bastante grandes e com elementos muito heterogêneos. Indicam-se os dispositivos impugnados, mas não há uma classificação desses dados (que ocorrerá na indexação). Por esse motivo, nossa sugestão é a de que eles não sejam extraídos para a tabela, e sim salvos em um arquivo específico.
Desenvolva no seu código um comando para gravar esse dispositivo em um arquivo especificamente criado para isso, lembrando-se de gravar também um indicador, que permitirá que esses dados sejam posteriormente concatenados com as outras informações tabuladas. E não se esqueça de acrescentar, no início do código (por volta da linha 14) uma função de limpeza do arquivo criado para esse fim.
Quando você retirar o campo dispositivo_CC dos dados a gravar, a sua importação de dados no Excel vai parar de funcionar, pois toda mudança nos campos gera a necessidade de criar uma importação nova. Aproveite esse momento para ajustar os outros nomes dos campos cujo sentido foi modificado (o cln, que passou a conter dados apenas sobre a existência de pedido de liminar na inicial, e o requerente) ou que foram excluídos (como requerido).
5.8 Campo fundamento
O fundamento também é um elemento heterogêneo porque há alguns casos em que há um fundamento apenas e outros casos em que há múltiplos fundamentos. Nesse caso, sugerimos que você use uma estratégia nova: crie uma lista de fundamentos, usando o comando split().
Antes disso, porém, convém limpar um pouco o texto, pois antes de cada 'ART', aparece um '- ', que pode ser excluído. Quando você definir o split, é preciso lembrar que o '|' substitui um '\n' na nossa gravação de csv e, por isso, você deve usar o comando fundamento_CC.split('\n'). Você também notará que há um símbolo de parágrafo antes do primeiro 'ART', que pode ser excluído por meio de um .strip('\n').
5.9 Campos resultado liminar e resultado final
Os campos de resultado contém duas informações diferentes: resultado e órgão julgador da liminar. Por isso, convém segmentar essas informações, deixando um campo para conter o valor da decisão ('PROCEDENTE', 'DEFERIDA', etc.) e outro para conter o órgão decisor (diferenciando monocráticas de colegiadas). No caso destes dados, só temos informação precisa sobre as monocráticas, e não temos uma garantia de que todas as outras são colegiadas.
Você também notará que, nas decisões, não há uma padronização total dos resultados. Há resultados 'PREJUDICADA' e 'PREJUDICADO', que talvez não sejam idênticos. Para avaliar isso, convém isolar essas ocorrências dentro do filtro do Excel, que permite avaliar se isso é apenas uma falta de padronização ou se são decisões diferentes. No caso do nosso conjunto de ações, resta claro que os dois 'PREJUDICADO' são apenas um lançamento sem a padronização adequada. Como são poucos casos, porém, convém ampliar primeiro a seleção para verificar isso ocorre também nas outras situações.
5.10 Campos indexador e prevenção
O campo indexador contém também duas informações. Uma parece indicar uma classificação do ato impugnado, feita pelo Tribunal. Mas ela também contém uma indicação dos processos em que existe prevenção, o que deve ser mapeado em um campo específico.
5.11 Organizador atualizado
A realização das atualizações acima referida leva a um código como o seguinte:
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais2.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:500]
# Define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
dsd.limpar_arquivo('dispositivos_CC.txt')
# Cria lista para armazenar todos os dados
dados_totais = []
# Iteração para extrair os dados de cada processo
for item in dados:
# Redefine variáveis
processo = 'NA'
incidente = 'NA'
# Defindo campos já individualizados
processo = item[0]
incidente = item[1]
data_extracao = item[2]
# Extrai dados do campo html_CC
html_CC = item[3]
# Extrai e trata o campo cln_CC
pedido_de_liminar_CC = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>').upper()
## Remove acentos
pedido_de_liminar_CC = dsd.remover_acentos(pedido_de_liminar_CC)
## Extrai a informação sobre pedido de liminar na petição inicial
if '(MED. LIMINAR)' in pedido_de_liminar_CC:
pedido_de_liminar_CC = 'SIM'
## Reduz o nome da ação para a sigla ADI
pedido_de_liminar_CC = pedido_de_liminar_CC.replace(
'ACAO DIRETA DE INCONSTITUCIONALIDADE',
'ADI')
# Extrai e trata o campo origem_CC
origem_CC = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>').upper()
## Remove acentos
origem_CC = dsd.remover_acentos(origem_CC)
# Extrai e trata o campo entrada_CC
entrada_CC = dsd.extrair(html_CC,
'Distribuído:</td><td><strong>',
'</strong>').upper()
## Remove acentos
entrada_CC = dsd.remover_acentos(entrada_CC)
entrada_CC = entrada_CC.replace('-','/')
entrada_CC = dsd.ajustar_mes(entrada_CC)
# Extrai e trata o campo relator_CC
relator_CC = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>').upper()
## Remove acentos
relator_CC = dsd.remover_acentos(relator_CC)
## Exclui o trecho MINISTRO/A e variações
relator_CC = relator_CC.replace('MINISTRO','')
relator_CC = relator_CC.replace('MINISTRA','')
relator_CC = relator_CC.replace('MIINISTRO','')
relator_CC = relator_CC.replace('MIMISTRO','')
relator_CC = relator_CC.replace('MININISTRO','')
# Extrai e trata o campo requerente_CC
requerente_CC = dsd.extrair(html_CC,
'Requerente: <strong>',
'</strong>').upper()
## Remove acentos
requerente_CC = dsd.remover_acentos(requerente_CC)
## Corrige dados fora do padrão
requerente_CC = requerente_CC.replace('103 ','103,')
requerente_CC = requerente_CC.replace('103 ','103.')
## Extrai o inciso com o tipo do requerente
if '103,' in requerente_CC:
requerente_CC = requerente_CC.split('103,')[1]
## limpa o tipo do requerente
requerente_CC = requerente_CC.strip()
requerente_CC = requerente_CC.strip('0')
requerente_CC = requerente_CC.strip(')')
# Converte o campo requerente em tipo de requerente
requerente_tipo_CC = requerente_CC
# Extrai e trata o campo dispositivo_CC
dispositivo_CC = dsd.extrair(html_CC,
'Legal Questionado</b></strong><br /><pre>',
'</pre>')
# Extrai e trata o campo fundamento_CC
fundamento_CC = dsd.extrair(html_CC,
'Constitucional</b></strong><br /><pre>',
'</pre>').upper()
## Remove acentos
fundamento_CC = dsd.remover_acentos(fundamento_CC)
# Limpa o campo
fundamento_CC = fundamento_CC.replace('- ART','ART')
fundamento_CC = fundamento_CC.strip('\n')
# Gera lista de fundamentos
fundamento_CC = fundamento_CC.split('\n')
# Extrai e trata o campo resultado_liminar_CC
resultado_liminar_CC = dsd.extrair(html_CC,
'Resultado da Liminar</b></strong><br /><br />',
'<br />').upper()
## Remove acentos
resultado_liminar_CC = dsd.remover_acentos(resultado_liminar_CC)
## Define campo para identificar decisões monocráticas
orgao_liminar_CC = 'NA'
## Corrige dados fora do padrão
resultado_liminar_CC = resultado_liminar_CC.replace('MONOACRATICA',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('LIMINAR ','')
## Gera campo órgão nos casos de decisão monocrática
if 'DECISAO MONOCRATICA - ' in resultado_liminar_CC:
resultado_liminar_CC = resultado_liminar_CC.replace(
'DECISAO MONOCRATICA -','')
orgao_liminar_CC = 'MONOCRATICA'
# Extrai e trata o campo resultado_final_CC
resultado_final_CC = dsd.extrair(html_CC,
'Resultado Final</b></strong><br /><br />',
'<br />').upper()
## Remove acentos
resultado_final_CC = dsd.remover_acentos(resultado_final_CC)
## Define o campo orgao
orgao_resultado_final_CC = 'NA'
## Corrige dados fora do padrão
resultado_final_CC = resultado_final_CC.replace('MONOCRATICO',
'MONOCRATICA')
## Gera campo orgao
if 'DECISAO MONOCRATICA - ' in resultado_final_CC:
resultado_final_CC = resultado_final_CC.replace(
'DECISAO MONOCRATICA -','')
orgao_resultado_final_CC = 'MONOCRATICA'
# Extrai e trata o campo monocratica_final_CC
monocratica_final_CC = dsd.extrair(html_CC,
'Decisão Monocrática Final</b></strong><br /><pre>',
'</pre>')
# Extrai e trata o campo indexacao_CC
indexacao_CC = dsd.extrair(html_CC,
'Indexação</b></strong><br /><pre>',
'</pre>').upper()
## Remove acentos
indexacao_CC = dsd.remover_acentos(indexacao_CC)
## Cria o campo prevenção
prevencao_CC = 'NA'
## Limpa o campo indexação de textos indevidos
indexacao_CC = indexacao_CC.replace('<BR />','')
## Gera o dado sobre prevenção e adapta o campo indexação
if 'PREVENCAO' in indexacao_CC:
prevencao_CC = dsd.extrair(indexacao_CC, 'PREVENCAO - ', '\n')
indexacao_CC = dsd.extrair(indexacao_CC, prevencao_CC,'')
# Define os dados a serem gravados
dados_processo = [processo,
incidente,
pedido_de_liminar_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_tipo_CC,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC]
# Grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,
'''processo,
incidente,
pedido_de_liminar_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_tipo_CC,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC''')
dsd.write_csv_row(arquivo,dados_processo)
# Grava o arquivo com os dispositivos legais impugnados
dsd.write_csv_header('dispositivos_CC.txt','processo,dispositivo')
dsd.write_csv_row('dispositivos_CC.txt',[processo,dispositivo_CC])
# Grava mensagem de finalização do progama com êxito
print (f'Gravado arquivo {arquivo}')6. Tratamento e limpeza dos dados da página de Informações Processuais
Neste tutorial, você desenvolveu habilidade para extrair e limpar diversos campos simples, e inclusive um campo com formato de lista (fundamentos). A extração dos demais campos simples (que não são listas de elementos complexos) não representa um desafio mais complexo do que o que foi realizado até aqui e, por isso, propomos que você faça essa tentativa de extrair as informações dos demais códigos-fonte coletados no site do STF.
No próximo tutorial, trabalharemos com os campos de Partes, Andamentos, Deslocamentos e Sessões, que têm uma complexidade maior. Porém, neste texto, ainda precisamos criar as bases para você poder extrair os dados das Informações Processuais.
No código seguinte (Organizador_STF_09), inserimos uma definição dos demais campos contidos na nossa base de dados não-tratados (linhas 42 a 50) e condicionamos a extração dos dados html_CC ao fato de fazerem parte de uma das classes do controle concentrado (linha 58), o que exigiu que criássemos uma definição de todas as variáveis a serem extraídas dos processos de controle concentrado (e que serão vazias nas demais classes processuais).
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:]
# Define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
dsd.limpar_arquivo('dispositivos_CC.txt')
# Cria lista para armazenar todos os dados
dados_totais = []
# Iteração para extrair os dados de cada processo
for item in dados:
# Redefine variáveis
processo = 'NA'
incidente = 'NA'
pedido_de_liminar_CC = 'NA'
origem_CC = 'NA'
entrada_CC = 'NA'
relator_CC = 'NA'
requerente_tipo_CC = 'NA'
fundamento_CC = 'NA'
resultado_liminar_CC = 'NA'
orgao_liminar_CC = 'NA'
resultado_final_CC = 'NA'
orgao_resultado_final_CC = 'NA'
monocratica_final_CC = 'NA'
indexacao_CC = 'NA'
prevencao_CC = 'NA'
# Defindo campos já individualizados
processo = item[0]
incidente = item[1]
data_extracao = item[2]
html_CC = item[3]
html_IP = item[4]
informacoes = item[5]
partes = item[6]
andamentos = item[7]
recursos = item[8]
# Extrai dados do campo html_CC
if ('ADI' in processo or
'ADPF' in processo or
'ADO' in processo or
'ADC' in processo):
## Extrai e trata o campo cln_CC
pedido_de_liminar_CC = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>').upper()
### Remove acentos
pedido_de_liminar_CC = dsd.remover_acentos(pedido_de_liminar_CC)
### Extrai a informação sobre pedido de liminar na petição inicial
if '(MED. LIMINAR)' in pedido_de_liminar_CC:
pedido_de_liminar_CC = 'SIM'
### Reduz o nome da ação para a sigla ADI
pedido_de_liminar_CC = pedido_de_liminar_CC.replace(
'ACAO DIRETA DE INCONSTITUCIONALIDADE',
'ADI')
# Extrai e trata o campo origem_CC
origem_CC = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>').upper()
### Remove acentos
origem_CC = dsd.remover_acentos(origem_CC)
## Extrai e trata o campo entrada_CC
entrada_CC = dsd.extrair(html_CC,
'Distribuído:</td><td><strong>',
'</strong>').upper()
### Remove acentos
entrada_CC = dsd.remover_acentos(entrada_CC)
entrada_CC = entrada_CC.replace('-','/')
entrada_CC = dsd.ajustar_mes(entrada_CC)
## Extrai e trata o campo relator_CC
relator_CC = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>').upper()
### Remove acentos
relator_CC = dsd.remover_acentos(relator_CC)
### Exclui o trecho MINISTRO/A e variações
relator_CC = relator_CC.replace('MINISTRO','')
relator_CC = relator_CC.replace('MINISTRA','')
relator_CC = relator_CC.replace('MIINISTRO','')
relator_CC = relator_CC.replace('MIMISTRO','')
relator_CC = relator_CC.replace('MININISTRO','')
## Extrai e trata o campo requerente_CC
requerente_CC = dsd.extrair(html_CC,
'Requerente: <strong>',
'</strong>').upper()
### Remove acentos
requerente_CC = dsd.remover_acentos(requerente_CC)
### Corrige dados fora do padrão
requerente_CC = requerente_CC.replace('103 ','103,')
requerente_CC = requerente_CC.replace('103 ','103.')
### Extrai o inciso com o tipo do requerente
if '103,' in requerente_CC:
requerente_CC = requerente_CC.split('103,')[1]
### limpa o tipo do requerente
requerente_CC = requerente_CC.strip()
requerente_CC = requerente_CC.strip('0')
requerente_CC = requerente_CC.strip(')')
# Converte o campo requerente em tipo de requerente
requerente_tipo_CC = requerente_CC
## Extrai e trata o campo dispositivo_CC
dispositivo_CC = dsd.extrair(html_CC,
'Legal Questionado</b></strong><br /><pre>',
'</pre>')
# Extrai e trata o campo fundamento_CC
fundamento_CC = dsd.extrair(html_CC,
'Constitucional</b></strong><br /><pre>',
'</pre>').upper()
### Remove acentos
fundamento_CC = dsd.remover_acentos(fundamento_CC)
# Limpa o campo
fundamento_CC = fundamento_CC.replace('- ART','ART')
fundamento_CC = fundamento_CC.strip('\n')
# Gera lista de fundamentos
fundamento_CC = fundamento_CC.split('\n')
## Extrai e trata o campo resultado_liminar_CC
resultado_liminar_CC = dsd.extrair(html_CC,
'Resultado da Liminar</b></strong><br /><br />',
'<br />').upper()
### Remove acentos
resultado_liminar_CC = dsd.remover_acentos(resultado_liminar_CC)
### Define campo para identificar decisões monocráticas
orgao_liminar_CC = 'NA'
### Corrige dados fora do padrão
resultado_liminar_CC = resultado_liminar_CC.replace('MONOACRATICA',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('LIMINAR ','')
### Gera campo órgão nos casos de decisão monocrática
if 'DECISAO MONOCRATICA - ' in resultado_liminar_CC:
resultado_liminar_CC = resultado_liminar_CC.replace(
'DECISAO MONOCRATICA -','')
orgao_liminar_CC = 'MONOCRATICA'
# Extrai e trata o campo resultado_final_CC
resultado_final_CC = dsd.extrair(html_CC,
'Resultado Final</b></strong><br /><br />',
'<br />').upper()
### Remove acentos
resultado_final_CC = dsd.remover_acentos(resultado_final_CC)
### Define o campo orgao
orgao_resultado_final_CC = 'NA'
### Corrige dados fora do padrão
resultado_final_CC = resultado_final_CC.replace('MONOCRATICO',
'MONOCRATICA')
### Gera campo orgao
if 'DECISAO MONOCRATICA - ' in resultado_final_CC:
resultado_final_CC = resultado_final_CC.replace(
'DECISAO MONOCRATICA -','')
orgao_resultado_final_CC = 'MONOCRATICA'
# Extrai e trata o campo monocratica_final_CC
monocratica_final_CC = dsd.extrair(html_CC,
'Decisão Monocrática Final</b></strong><br /><pre>',
'</pre>')
## Extrai e trata o campo indexacao_CC
indexacao_CC = dsd.extrair(html_CC,
'Indexação</b></strong><br /><pre>',
'</pre>').upper()
### Remove acentos
indexacao_CC = dsd.remover_acentos(indexacao_CC)
### Cria o campo prevenção
prevencao_CC = 'NA'
### Limpa o campo indexação de textos indevidos
indexacao_CC = indexacao_CC.replace('<BR />','')
### Gera o dado sobre prevenção e adapta o campo indexação
if 'PREVENCAO' in indexacao_CC:
prevencao_CC = dsd.extrair(indexacao_CC, 'PREVENCAO - ', '\n')
indexacao_CC = dsd.extrair(indexacao_CC, prevencao_CC,'')
# Define os dados a serem gravados
dados_processo = [processo,
incidente,
pedido_de_liminar_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_tipo_CC,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC]
# Grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,
'''processo,
incidente,
pedido_de_liminar_CC,
origem_CC,
entrada_CC,
relator_CC,
requerente_tipo_CC,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC''')
dsd.write_csv_row(arquivo,dados_processo)
# Grava o arquivo com os dispositivos legais impugnados
dsd.write_csv_header('dispositivos_CC.txt','processo,dispositivo')
dsd.write_csv_row('dispositivos_CC.txt',[processo,dispositivo_CC])
# Grava mensagem de finalização do progama com êxito
print (f'Gravado arquivo {arquivo}')A partir deste código, você pode fazer as adaptações necessárias para extrair as demais informações relevantes. Note que os dados de decisões e de pautas são tipos de andamentos, o que dispensa sua extração autônoma. Portanto, os dados que você pode se exercitar para extrair são aqueles contidos na página principal do processo (html_IP) e na aba de informações.
7. Organizador Básico Final
O código abaixo, contido no GitHub como Organizador_Básico_Final.py, incorpora as funcionalidades do organizador básico, com a extração dos dados faltantes (exceto os dados complexos, que serão abordados no extrator intermediário) e um tratamento devido dessas informações, de modo a produzir uma base de dados adequada.
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais5.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:]
# Define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
dsd.limpar_arquivo('dispositivos_CC.txt')
# Cria lista para armazenar todos os dados
dados_totais = []
# Iteração para extrair os dados de cada processo
for item in dados:
# Redefine variáveis
processo = 'NA'
incidente = 'NA'
protocolo_data = 'NA'
eletronico_fisico = 'NA'
sigilo = 'NA'
numerounico = 'NA'
assuntos = 'NA'
orgaodeorigem = 'NA'
origem_sigla = 'NA'
numerodeorigem = 'NA'
pedido_de_liminar_CC = 'NA'
origem_CC = 'NA'
entrada_CC = 'NA'
relator_CC = 'NA'
requerente_tipo_CC = 'NA'
dispositivo_CC = 'NA'
fundamento_CC = 'NA'
resultado_liminar_CC = 'NA'
orgao_liminar_CC = 'NA'
resultado_final_CC = 'NA'
orgao_resultado_final_CC = 'NA'
monocratica_final_CC = 'NA'
indexacao_CC = 'NA'
prevencao_CC = 'NA'
# Defindo campos já individualizados
processo = item[0]
incidente = item[1]
data_extracao = item[2]
html_CC = item[3]
html_IP = item[4]
informacoes = item[5]
partes = item[6]
andamentos = item[7]
recursos = item[8]
# Extrai dados do campo html_IP
eletronico_fisico = dsd.extrair(html_IP,'bg-primary">','</span>')
eletronico_fisico = eletronico_fisico.replace('Processo Eletrônico','E')
if eletronico_fisico != 'E':
eletronico_fisico = dsd.extrair(html_IP,'bg-default">','</span>')
eletronico_fisico = eletronico_fisico.replace(
'Processo Físico','F')
sigilo = dsd.extrair(html_IP,'bg-success">','</span>').upper()
sigilo = sigilo.replace('PÚBLICO','P')
nome_processo =dsd.extrair(html_IP,'-processo" value="','">')
numerounico = dsd.extrair(html_IP,'-rotulo">','</div>')
numerounico = dsd.extrair(numerounico,': ', '')
# Extrai dados do campo informacoes
assuntos = dsd.extrair(informacoes,
'<ul style="list-style:none;">',
'</ul>').upper()
assuntos = dsd.remover_acentos(assuntos)
assuntos = dsd.limpar(assuntos)
assuntos = dsd.extrair(assuntos,'<LI>','')
assuntos = assuntos.replace('</LI>','')
assuntos = dsd.limpar(assuntos)
assuntos = assuntos.split('<LI>')
protocolo_data = dsd.extrair(informacoes,
'Data de Protocolo:',
'Órgão de Origem:')
protocolo_data = dsd.extrair(protocolo_data, 'm-l-0">','</div>')
protocolo_data = protocolo_data.replace('\n','')
protocolo_data = protocolo_data.strip()
orgaodeorigem = dsd.extrair(informacoes,'Órgão de Origem:','Origem')
orgaodeorigem = dsd.extrair(orgaodeorigem,'processo-detalhes">','<')
orgaodeorigem = orgaodeorigem.replace('SUPREMO TRIBUNAL FEDERAL','STF')
orgaodeorigem = dsd.limpar(orgaodeorigem)
origem = dsd.extrair(informacoes, '\n Origem:', 'Origem:')
origem = dsd.extrair(origem, 'processo-detalhes">', '<')
origem = dsd.limpar(origem)
origem_sigla = dsd.extrair(informacoes,'procedencia">','<')
origem_sigla = dsd.limpar(dsd.extrair(origem_sigla,'','-'))
numerodeorigem = dsd.extrair(informacoes,
'Número de Origem:\n </div>\n <div class="col-md-5 processo-detalhes">\n',
'</div>')
numerodeorigem = dsd.limpar(numerodeorigem)
numerodeorigem = numerodeorigem.replace(' ','')
numerodeorigem = numerodeorigem.split(',')
if len(numerodeorigem) != 1:
if numerodeorigem[0] == numerodeorigem[1]:
numerodeorigem.pop(1)
# Extrai dados do campo html_CC
if ('ADI' in processo or
'ADPF' in processo or
'ADO' in processo or
'ADC' in processo):
## Extrai e trata o campo cln_CC
pedido_de_liminar_CC = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>').upper()
### Remove acentos
pedido_de_liminar_CC = dsd.remover_acentos(pedido_de_liminar_CC)
### Extrai a informação sobre pedido de liminar na petição inicial
if 'LIMINAR' in pedido_de_liminar_CC:
pedido_de_liminar_CC = 'SIM'
### Reduz o nome da ação para a sigla ADI
pedido_de_liminar_CC = pedido_de_liminar_CC.replace(
'ACAO DIRETA DE INCONSTITUCIONALIDADE',
'ADI')
# Extrai e trata o campo origem_CC
origem_CC = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>').upper()
### Remove acentos
origem_CC = dsd.remover_acentos(origem_CC)
## Extrai e trata o campo entrada_CC
entrada_CC = dsd.extrair(html_CC,
'Distribuído:</td><td><strong>',
'</strong>').upper()
### Remove acentos
entrada_CC = dsd.remover_acentos(entrada_CC)
entrada_CC = entrada_CC.replace('-','/')
entrada_CC = dsd.ajustar_mes(entrada_CC)
## Extrai e trata o campo relator_CC
relator_CC = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>').upper()
### Remove acentos
relator_CC = dsd.remover_acentos(relator_CC)
### Exclui o trecho MINISTRO/A e variações
relator_CC = relator_CC.replace('MINISTRO','')
relator_CC = relator_CC.replace('MINISTRA','')
relator_CC = relator_CC.replace('MIINISTRO','')
relator_CC = relator_CC.replace('MIMISTRO','')
relator_CC = relator_CC.replace('MININISTRO','')
## Extrai e trata o campo requerente_CC
requerente_CC = dsd.extrair(html_CC,
'Requerente: <strong>',
'</strong>').upper()
### Remove acentos
requerente_CC = dsd.remover_acentos(requerente_CC)
### Corrige dados fora do padrão
requerente_CC = requerente_CC.replace('103 ','103,')
requerente_CC = requerente_CC.replace('103 ','103.')
### Extrai o inciso com o tipo do requerente
if '103,' in requerente_CC:
requerente_CC = requerente_CC.split('103,')[1]
else:
requerente_CC = 'NA'
### limpa o tipo do requerente
requerente_CC = dsd.limpar(requerente_CC)
requerente_CC = requerente_CC.strip(',')
requerente_CC = requerente_CC.strip()
requerente_CC = requerente_CC.strip('0')
requerente_CC = requerente_CC.strip('0')
requerente_CC = requerente_CC.strip('(')
requerente_CC = requerente_CC.strip(')')
requerente_CC = requerente_CC.strip('2')
requerente_CC = requerente_CC.strip('CF')
requerente_CC = dsd.limpar(requerente_CC)
# Converte o campo requerente em tipo de requerente
requerente_tipo_CC = requerente_CC
## Extrai e trata o campo dispositivo_CC
dispositivo_CC = dsd.extrair(html_CC,
'Legal Questionado</b></strong><br /><pre>',
'</pre>')
# Extrai e trata o campo fundamento_CC
fundamento_CC = dsd.extrair(html_CC,
'Constitucional</b></strong><br /><pre>',
'</pre>').upper()
### Remove acentos
fundamento_CC = dsd.remover_acentos(fundamento_CC)
# Limpa o campo
fundamento_CC = fundamento_CC.replace('- ART','ART')
fundamento_CC = fundamento_CC.strip('\n')
# Gera lista de fundamentos
fundamento_CC = fundamento_CC.split('\n')
## Extrai e trata o campo resultado_liminar_CC
resultado_liminar_CC = dsd.extrair(html_CC,
'Resultado da Liminar</b></strong><br /><br />',
'<br />').upper()
### Remove acentos
resultado_liminar_CC = dsd.remover_acentos(resultado_liminar_CC)
### Define campo para identificar decisões monocráticas
orgao_liminar_CC = 'NA'
### Corrige dados fora do padrão
resultado_liminar_CC = resultado_liminar_CC.replace('MONOACRATICA',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('MONICRATICA',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('MONOCRATICO',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('LIMINAR ','')
### Gera campo órgão nos casos de decisão monocrática
if 'DECISAO MONOCRATICA - ' in resultado_liminar_CC:
resultado_liminar_CC = resultado_liminar_CC.replace(
'DECISAO MONOCRATICA -','')
resultado_liminar_CC = resultado_liminar_CC.replace(
'DECISAO MONOCRATICA ','')
orgao_liminar_CC = 'MONOCRATICA'
# Extrai e trata o campo resultado_final_CC
resultado_final_CC = dsd.extrair(html_CC,
'Resultado Final</b></strong><br /><br />',
'<br />').upper()
### Remove acentos
resultado_final_CC = dsd.remover_acentos(resultado_final_CC)
### Define o campo orgao
orgao_resultado_final_CC = 'NA'
### Corrige dados fora do padrão
resultado_final_CC = resultado_final_CC.replace('MONOCRATICO',
'MONOCRATICA')
### Gera campo orgao
if 'DECISAO MONOCRATICA - ' in resultado_final_CC:
resultado_final_CC = resultado_final_CC.replace(
'DECISAO MONOCRATICA -','')
orgao_resultado_final_CC = 'MONOCRATICA'
# Extrai e trata o campo monocratica_final_CC
monocratica_final_CC = dsd.extrair(html_CC,
'Decisão Monocrática Final</b></strong><br /><pre>',
'</pre>')
## Extrai e trata o campo indexacao_CC
indexacao_CC = dsd.extrair(html_CC,
'Indexação</b></strong><br /><pre>',
'</pre>').upper()
### Remove acentos
indexacao_CC = dsd.remover_acentos(indexacao_CC)
### Cria o campo prevenção
prevencao_CC = 'NA'
### Limpa o campo indexação de textos indevidos
indexacao_CC = indexacao_CC.replace('<BR />','')
### Gera o dado sobre prevenção e adapta o campo indexação
if 'PREVENCAO' in indexacao_CC:
prevencao_CC = dsd.extrair(indexacao_CC, 'PREVENCAO - ', '\n')
indexacao_CC = dsd.extrair(indexacao_CC, prevencao_CC,'')
indexacao_CC = dsd.limpar(indexacao_CC)
# Define os dados a serem gravados
if incidente != 'NA' and incidente != '':
dados_processo = [processo,
incidente,
protocolo_data,
eletronico_fisico,
sigilo,
numerounico,
assuntos,
orgaodeorigem,
origem_sigla,
origem_CC,
numerodeorigem,
pedido_de_liminar_CC,
entrada_CC,
relator_CC,
requerente_tipo_CC,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC]
# Grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,
'''processo,
incidente,
protocolo_data,
eletronico_fisico,
sigilo,
numerounico,
assuntos,
orgaodeorigem,
origem_sigla,
origem_CC,
numerodeorigem,
pedido_de_liminar_CC,
entrada_CC,
relator_CC,
requerente_tipo_CC,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC''')
dsd.write_csv_row(arquivo,dados_processo)
# Grava o arquivo com os dispositivos legais impugnados
dsd.write_csv_header('dispositivos_CC.txt','processo,dispositivo')
dsd.write_csv_row('dispositivos_CC.txt',[processo,dispositivo_CC])
# Grava mensagem de finalização do progama com êxito
print (f'Gravado arquivo {arquivo}')