Data Mining Judicial 2 - Extrator Básico


1. Introdução
O presente texto é o primeiro módulo da nossa abordagem sobre a coleta de dados, que está dividida em seis etapas, como definido no Data Mining Judicial I.
No presente texto, realizaremos a primeira dessas etapas, que é a elaboração do extrator que chamamos de básico porque ele utiliza estratégias voltadas apenas para a extração de conteúdos que estão em HTML, no código-fonte da página. Isso faz com que as estratégias exploradas neste momento sejam insuficientes para coletar alguns dados muito relevantes, como os andamentos processuais, que exigem a extração simultânea de múltiplas páginas (complexidade que será explorado no extrator intermediário). O objetivo deste ponto é desenvolver 3 habilidades fundamentais para realizar qualquer extração:
- Identificação dos dados relevantes e dos endereços em que eles se encontram;
- Requisição dos dados;
- Gravação das informações obtidas.
Embora este módulo seja voltado a pessoas que nunca elaboraram extratores de dados, a compreensão de todos os elementos aqui utilizados é muito facilitada pela realização do Curso de Programação para Juristas, um minicurso introdutório de cinco módulos nos quais você tem uma orientação minuciosa sobre os comandos básicos de Python e sobre as estratégias de programação que serão utilizadas nos programas de extração e de organização de dados: iteração, expressões condicionais, booleanos, manipulação de variáveis, bibliotecas, funções, etc.
O objetivo do Curso de Programação para Juristas é servir como uma preparação para que os estudantes da disciplina Data Science e Direito possam enfrentar os desafios de programação envolvidos na elaboração dos algoritmos de extração e organização de dados. Por isso, embora a devida compreensão do presente texto não dependa de conhecimentos avançados de informática, não nos dedicaremos a oferecer explicações minuciosas sobre os elementos que já foram tratados naquele curso preliminar.
2. Extração do código-fonte
2.1 Identificação das informações relevantes
Para iniciar a extração dos dados, você não precisa desenvolver previamente um modelo de dados completo, mas precisa ter uma definição clara da sua unidade de análise. O restante do modelo pode ser desenvolvido quando você realizar a organização dos dados em uma tabela, pois você precisará definir com clareza quais são os campos que comporão a sua base de dados.
A relação objeto/população é o centro de gravidade da sua coleta, pois é preciso coletar dados referentes a objetos específicos (unidade de análise), cuja consolidação permitirá fazer afirmações sobre o universo (população dos objetos). Tês combinações típicas são:
- Pesquisa de jurisprudência, que tem como unidade de análise as decisões;
- Pesquisa de processos, que tem como unidade de análise cada processo individual;
- Pesquisa de "pautas", cuja unidade é a data em que são realizadas as sessões. Ao estudar os tipos de processos e temas tratados em cada sessão, bem como os tipos de decisão, você pode investigar a agenda do Tribunal.
A escolha dessas abordagens decorre do fato de que os sistemas disponíveis nos tribunais costumam disponibilizar os dados organizados segundo duas unidades de análise, que geram dois bancos de dados distintos:
- Um banco de dados de decisões, que chamamos de Jurisprudência.
- Um banco de dados de processos, que chamamos normalmente de Acompanhamento Processual.
Uma vez que você escolha a sua unidade de análise e as conexões que você pretende explorar (perfil das decisões, perfil dos autores, composição da pauta, etc.), você precisará explorar as informações disponíveis, com o objetivo de definir que tipo de dados você vai coletar.
2.2 Requisições HTTP
Você pode começar o processo de definição das informações a serem coletadas começa por meio do seu navegador (Chrome, Edge, Firefox, etc.), que oferece instrumentos eficientes para essa análise prévia. Todo browser tem uma série de ferramentas que revelam as estruturas das páginas monitoram as informações trocadas com os servidores, sendo que tais funcionalidades não são voltadas aos usuários que têm por único objetivo navegar pela internet, mas aos desenvolvedores, que precisam dessas informações para projetar seus programas.
Para entender essas ferramentas e suas utilidades, você precisa inicialmente compreender melhor o modo pelo qual o seu computador se conecta com o servidor do STF e obtém deles as informações que você visualiza na tela.
Quando falamos que uma página está hospedada em um servidor (server, um computador que oferece serviços a outros), indicamos que esse host (computador que hospeda páginas), ao receber requisições que apontem para um determinado localizador, enviará como resposta os conteúdos armazenados nesse "endereço".
Esse processo de Requisição/Resposta é feito mediante um protocolo de comunicação entre computadores, que define as formas de solicitação e de resposta. O protocolo mais usado na internet é o HTTP (Hypertext Transfer Protocol), que possibilita que você faça vários tipos de requisições, das quais você precisa aprender apenas uma: a solicitação de tipo get, que busca o conteúdo da página e retorna uma string com o conteúdo de um documento de tipo HTML.
Cada vez que você digita uma URL (Uniform Resourse Locator) em sua barra de endereços, ou clica sobre um link ou um botão, o seu computador envia para o servidor do STF uma requisição tipo get. Cabe aqui um esclarecimento: embora localizador seja masculino, boa parte das pessoas usa o gênero feminino para falar de URLs. Você vai encontrar os dois gêneros usados para essa palavra, mas nos meus textos utilizo "a URL", pois é a maneira que considero mais eufônica e a que parece mais utilizada na prática.
O seu navegador é o programa responsável por realizar as requisições HTTP, receber as respostas e transformar as informações recebidas em uma visualização adequada na sua tela. Neste curso, usaremos o Chrome, mas funcionalidades similares estão disponíveis nos outros browsers.
Para ver uma requisição completa, abra as ferramentas do desenvolvedor, o que você pode fazer de 4 formas diferentes, que te levarão ao mesmo resultado:
- Pressionando F12;
- Pressionando Ctrl-Shift-i;
- Pressionando Ctr-Shift-C;
- Clicando no botão direito do mouse sobre esta frase e escolhendo a opção Inspecionar.
Qualquer desas opções dividirá a sua tela ao meio, abrindo uma série de informações na parte direita da tela. Você deve continuar esse exercício com esse formato de tela dividida. Note que, dependendo do tamanho da tela que você usa, as informações terão uma distribuição diferente.
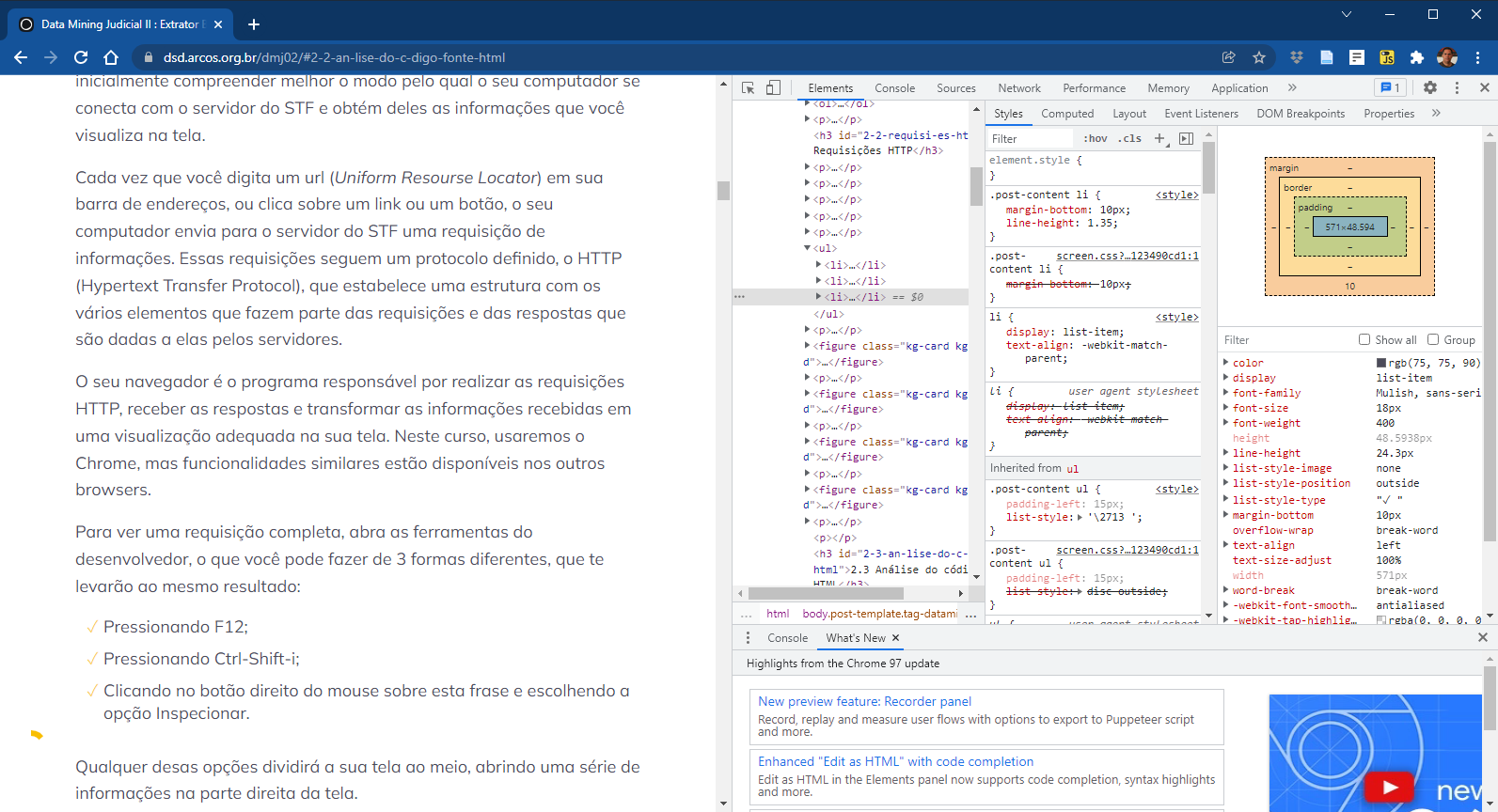
Agora você está vendo as estruturas das informações que são repassadas pelo STF para o seu computador. Boa parte delas são códigos para orientar o navegador sobre a maneira como os textos e imagens devem aparecer na tela, auxiliando com isso os web designers. No campo "Styles", por exemplo, você pode alterar os parâmetros de formatação da página e fazer testes com outros formatos: tamanhos de letra, cores, fontes, espaçamentos, etc.
Para acompanhar as requisições, é preciso abrir a aba Network, que passará a gravar as comunicações entre o seu computador e o servidor em que esta página está hospedada.
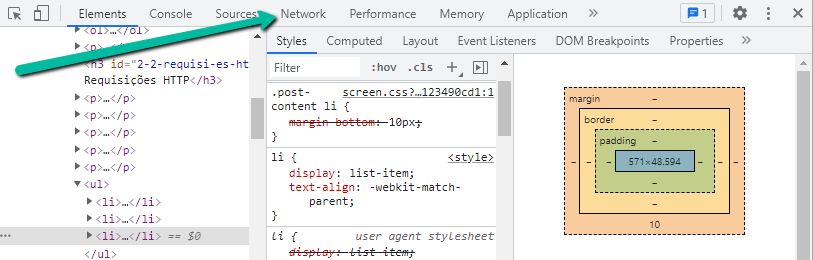
Você então deve chegar a uma janela com esse formato, que estará vazia porque somente agora os dados estão sendo gravados.
Agora, quando você digitar um endereço e pressionar Enter, ou quando clicar sobre um link, as várias trocas de dados entre o seu computador e o servidor serão gravados. Experimente clicar neste link para a página principal do STF: http://portal.stf.jus.br/. Você verá uma sucessão de entradas aparecendo na tela. No meu caso, foram exatamente 136 requisições trocadas em cerca de 5 segundos de atividade.
Experimente agora pesquisar a ADI-2222, inserindo esses dados na janela e clicando na lupa (ou pressionando enter). Essa ação desencadeará mais de 40 requisições, e interessa-nos ver especialmente a primeira delas, que você localiza subindo a barra até a primeira delas e clicando sobre ela, uma vez apenas, com o botão esquerdo do mouse, conforme o video abaixo.
Uma requisição completa é um texto longo, que tem informações Gerais ("General") e uma série de parâmetros que precisam ser definidos nos "Request Headers". Dos quais nos interessam especialmente o primeiro (Request URL, que transforma os termos inseridos por você nos campos de pesquisa em uma URL a ser buscada no servidor) e o último (User-Agent, que identifica o tipo de programa que faz a requisição).
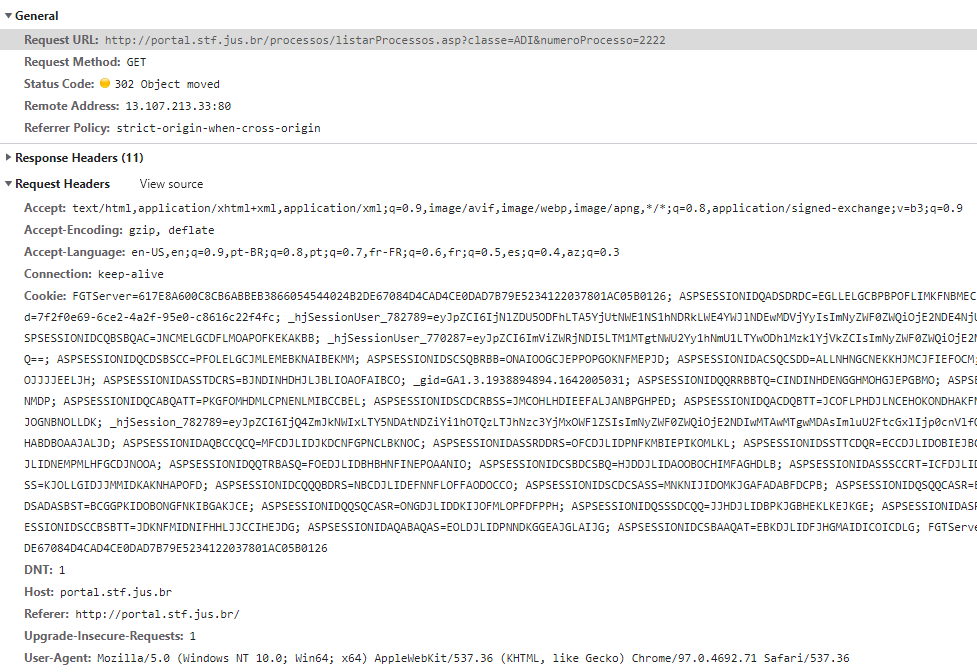
É importante que você saiba que essas requisições são as formas de comunicação dos computadores na internet, mas felizmente você não precisa gerenciar esse tipo de comunicação de forma manual. Quando você usa o seu navegador, ele opera essa intensa comunicação, que ocorre em segundo plano.
Quando você usa o Python, não existe a figura do navegador, mas você pode gerenciar essa comunicação por meio da biblioteca requests, que tem funções que automatizam essa troca de informações com os sevidores. Essa é uma biblioteca que permite gerenciar as requisições de forma simples e você pode aprender sobre ela na página Biblioteca Requests .
Porém, para tornar o trabalho de obtenção dos dados ainda mais simples, criamos no módulo dsd.py (com base na biblioteca requests) uma função específica para requisitar dados: a dsd.get().
Já quando você usa o Python, existem bibliotecas capazes de fazer esse gerenciamento de forma automatizada, deixando para você apenas a definição da URL a ser buscada, mas com a possibilidade de customizar os outros campos (sendo bastante indicado que você utilize, no campo User-Agent, os mesmos parâmetros contidos na imagem acima).
2.3 Análise do código-fonte: HTML
Agora que você aprendeu um pouco sobre como a comunicação entre os computadores se processa, podemos passar para a análise do conteúdo dessas informações que o servidor do STF envia para o seu computador, em resposta a suas requisições.
Como toda informação computacional, esses dados são codificados em uma determinada linguagem, sendo que a linguagem padrão da internet se chama HTML (Hypertext Markup Language).
Ao utilizar processadores de texto como o Word, você tem grande liberdade para definir tanto o conteúdo quanto o formato do seu texto, sendo que o texto que você vê na tela é idêntico ao que resultará de sua impressão, motivo pelo qual esse tipo de editor é chamado normalmente de WYSIWYG (What You See Is What You Get).
Esse tipo de abordagem está ligada à produção de textos para impressão, o que significa que esses editores respeitam uma regra implícita: é preciso trabalhar nos limites de uma folha de papel (real ou virtual), cujo tamanho você define no próprio documento. Não existe visualização do Word sem a prévia definição do "tamanho do papel", que é uma parte necessária do layout dos documentos.
Quando você escreve para a internet, a situação é muito diversa, pois existe uma multiplicidade de tamanhos de janelas de exibição. Experimente modificar a largura desta tela que você está lendo e você verá que o texto se adapta, mudando de forma, para adaptar-se às dimensões de sua exibição: seja um celular com 450 pixels de largura ou uma tela com 2500 pixels, é preciso que os navegadores consigam oferecer visualizações adequadas.
Essa plasticidade é fundamental para toda publicação na internet e, obviamente, ela demanda um planejamento exaustivo dos modos pelos quais a exibição será adaptada à tela do usuário. A programação dessa exibição flexível é feita utilizando uma linguagem computacional específica: o HTML, na qual é possível definir com comandos relativamente simples os modos pelos quais um texto será exibido nos mais variados formatos.
O custo da plasticidade oferecida pelo HTML é que, diversamente do que ocorre com os editores WYSIWYG, o texto que você enxerga quando escreve não é o texto que vai aparecer para o leitor, pois a formatação final depende do formato específico da tela de quem consome o conteúdo e das configurações do navegador, que podem ser muito diferentes daquelas que existem no ambiente de produção dos textos.
Na janela abaixo, está uma imagem do modo como eu vejo o texto que estou escrevendo, que é diferente do texto que você vê agora, pois ele não envolve nenhum dos formatos definidos no site dsd.arcos.org.br, e sim os formatos definidos no programa de edição do Ghost.

Para ver o HTML desta página basta clicar nela com o botão direito do mouse e escolher a opção "Exibir código fonte" (ou use Ctrl-U), que é o conjunto de códigos que o seu navegador recebeu do servidor, para ser capaz de exibir a tela que você vê agora.
Uma forma ainda mais interessante é utilizar o HTML viwer do Code Beautify. Entre em um jornal de grande circulação (como a Folha, o El País ou o NYT), escolha uma reportagem e copie a URL da página. Depois, entre no HTML viewer (veja a imagem abaixo), clique no Load Url, insira o endereço que você copiou, e clique em Load.
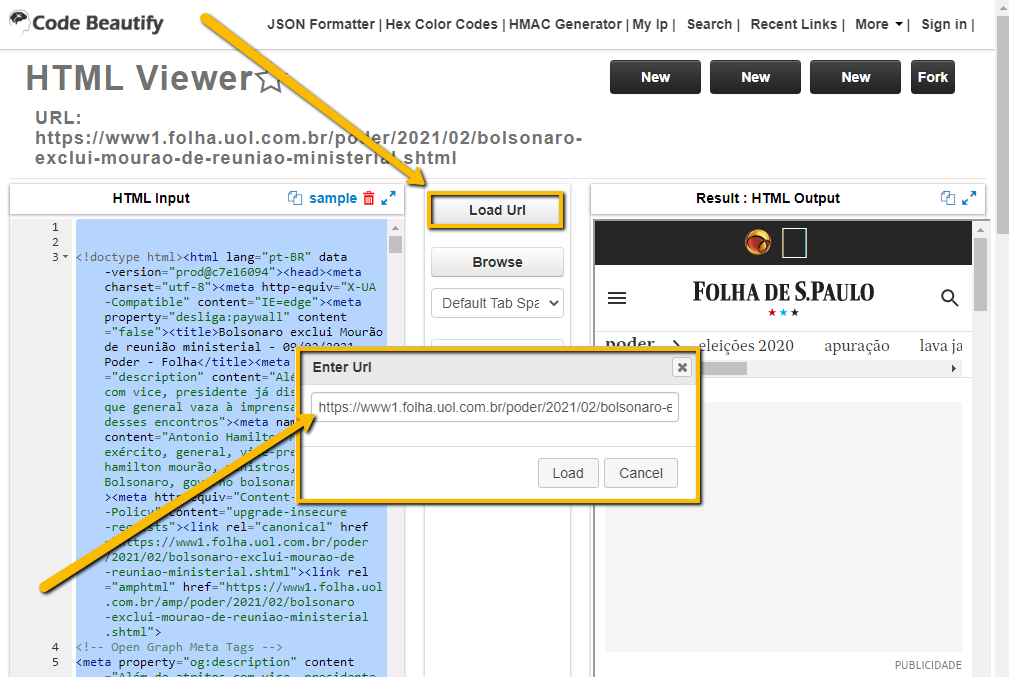
Esse programa exibirá, lado a lado, o código-fonte (o HTML input, que são as informações enviadas pelo servidor do jornal, com todos os códigos que definem a formatação a ser respeitada pelo navegdor) e o output, que é o modo como o navegador exibe as informações codificadas em HTML.
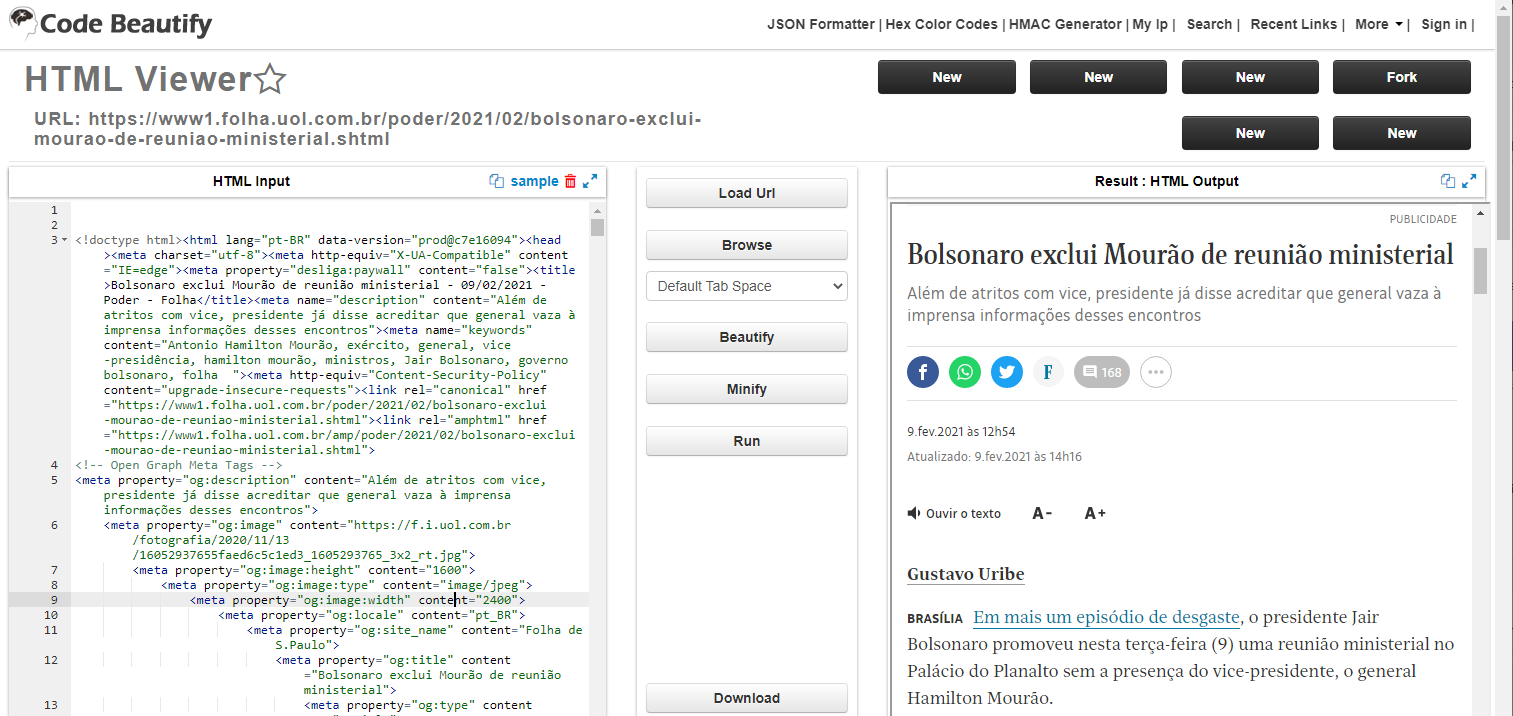
O HTML é uma markup language porque ela une, na mesma string, os conteúdos do seu texto e as marcações de formatação. Em programas como o Word, você define os parâmetros de formatação em janelas específicas, sendo impossível que você escreva, na mesma linha, o conteúdo e os códigos de formatação. Outra linguagem markup de ampla utilização é o Markdown (MD), que é mais amigável à escrita de textos e muito utilizada para escrever conteúdo para a internet, pois os documentos escritos em MD são convertidos em um código-fonte HTML.
Se você observar o código-fonte no HTML Viewer, notará que há partes em texto, entremeado por códigos que definem o modo como esse texto será visualizado: margens, fontes, tamanhos, fundos, etc.
As informações que vamos buscar na internet com o Python são aquelas que estão no código-fonte, pois estes são os dados efetivamente ofertados pelos servidores. Para se familiarizar com o tipo de informações que obteremos, abra no seu navegador (e não no HTML Viewer) o link abaixo, que tem as informações da ADI 333, na página específica de Controle Concentrado (STF/Processos/ADI, ADC, ADO e ADPF):
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&numProcesso=333
Com base nesses dados, faça o exercício abaixo.
Se você correu os olhos pelo código-fonte, deve ter notado que ele é dividido em linhas, que a primeira parte do documento contém uma série de informações sobre o cabeçalho ("Head") da página (linhas 8 a 49), sendo que as informações específicas sobre a ADI 333 começam na linha 70.
Observe, nas duas imagens abaixo, a comparação entre um texto exibido no Chrome e o código-fonte subjacente.
Exibição do Chrome
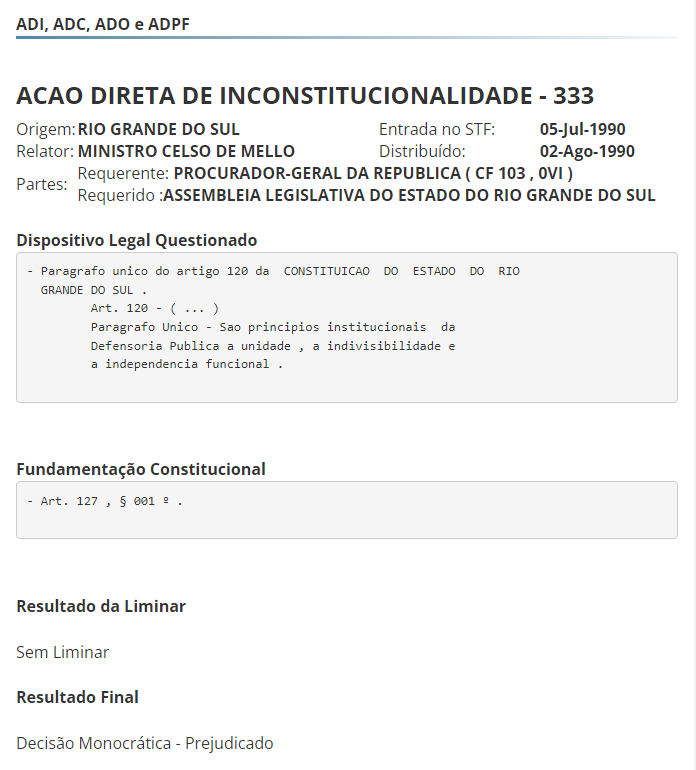
Código-fonte em HTML

Cotejando as duas imagens acima, você pode notar que a segunda contém os mesmos textos da primeira, mas incorpora também alguns códigos, sempre entre <>, que dão ao seu navegador parte das informações necessárias para exibir os conteúdos da forma como aparecem na primeira imagem.
Na linha 70, por exemplo, "<h3><strong>" indica que o texto "ACAO DIRETA DE INCONSTITUCIONALIDADE - 333" será exibido no formato Header3 e em negrito.
Você logo se acostumará com o fato de que <h3> marca o início da formatação Header3, enquanto </h3> marca o final dessa formatação, assim como <strong> marca o início dessa formatação, enquanto </strong> marca o final. Toda vez que você tiver um <h3> (ou <pre> ou <div> ou <strong>), necessariamente você terá um </h3> (ou </pre> ou </div> ou </strong>, pois toda marcação de início precisa de uma marcação de fim.
Familiarizar-se com o HTML é o começo do seu itinerário para extrair as informações, visto que você não trabalhará com a visualização do navegador, mas com os dados subjacentes, que estão no código-fonte (ou seja, escritos em HTML).
No primeiro momento, isso parece ser um problema, visto que aparecem muitos códigos que nós não entendemos e podemos ter a tentação de limpar os códigos. Porém, quando você começar a construir os módulos de organização de dados (ou seja, os geradores de tabela) essa multiplicidade de códigos será vista como uma grande vantagem, uma vez que os marcadores de formatação do HTML nos mostram a estrutura do documento e, consequentemente, nos servem como ótimos marcadores para localizar as informações que desejamos extrair.
A internet é baseada na construção de páginas que têm uma estrutura fixa (definida pelo HTML), e conteúdos variáveis, que são fornecidos a partir da URL que pesquisamos. A página da ADI-333 tem exatamente a mesma estrutura da página da ADI-444, e é exatamente por isso que somos capazes de gerar uma extração iterada, que repete o mesmo comando para coletar os dados de várias páginas diferentes.
2.4 Requisições do código-fonte com a função dsd.get()
Para começar o seu trajeto hacker, obtendo informações sem a necessidade de utilizar os navegadores, escolha uma ADI e busque o seu endereço por meio de uma pesquisa na página STF/Processos/ADI, ADC, ADO e ADPF. Eu escolhi a ADI 6058, mas você pode optar por qualquer ADI.
Nesta página, se você escolher a Base ADI e o Termo 6058, a pesquisa retornará como único resultado a ADI 6058 e, se você clicar sobre o link para esta ação, será aberta uma página com informações sobre este processo. O que nos interessa é localizar a URL que está na barra de endereços do seu navegador (neste caso, o Chrome), na parte superior da figura abaixo.
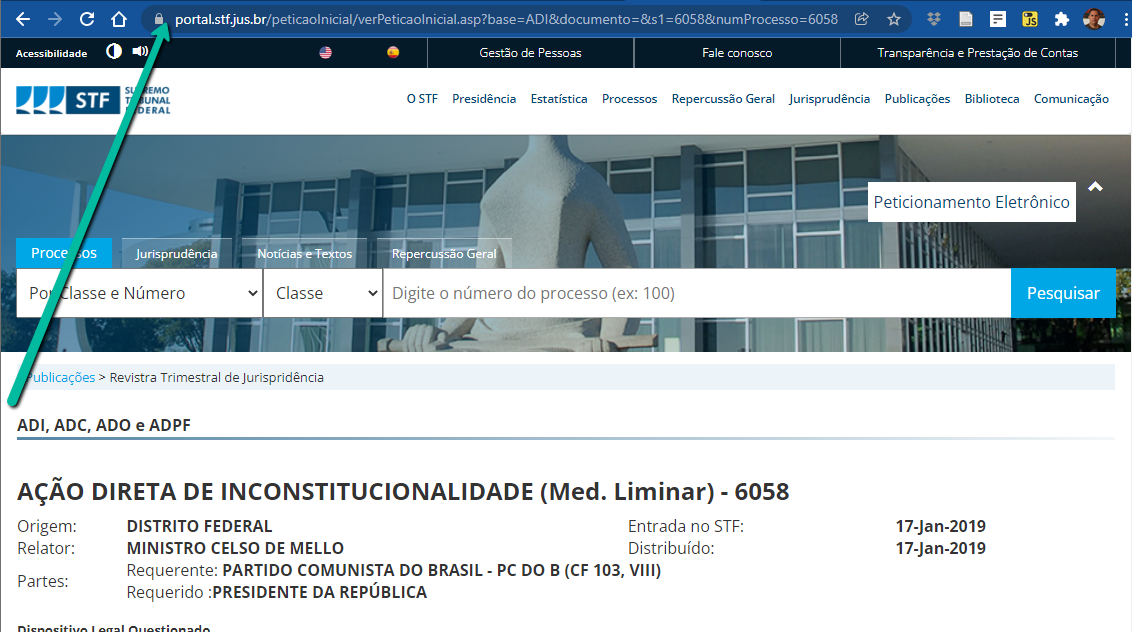
Uma vez que você identifique o endereço, você pode copiá-lo que terá o seguinte resultado:
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&documento=&s1=6058&numProcesso=6058
Uma vez que você tem o endereço, pode extrair as informações contidas nele por meio do seguinte código:
import dsd
# define a URL a ser buscada
url = 'Insira a URL que você escolheu'
# requisita os dados ao servidor e o atribui a uma variável string
html = dsd.get(url)
# imprime na tela os dados buscados
print (html)Este código importa o módulo dsd e utiliza a função dsd.get (que é baseada na biblioteca requests) para buscar o conteúdo de uma página. Infelizmente, se você utilizar diretamente a biblioteca requests, sem customizar o pedido, o STF responderá simplesmente que "Seu acesso a este website foi bloqueado de forma preventiva. Por favor, tente novamente em alguns minutos. (FD)". Para superar esse problema, que limita a transparência dos dados, a função dsd.get envia uma requisição com parâmetros que permitem ao servidor do STF (e à maioria dos servidores) responder à requisição HTTP apresentada.
O conteúdo da resposta é uma longa cadeia de caracteres, com o código-fonte, que o programa acima atribui à variável html e imprime na tela.
Se você seguir esses passos, chegará a um programa capaz de imprimir no console o código-fonte da página. O tamanho do código-fonte dificulta a sua devida observação no console, mas é possível abrir o seu conteúdo no Variable Explorer.
2.5 Gravação preliminar de dados
Agora que você tem um módulo básico de extração de dados, é preciso aprender a gravá-los. Para uma compreensão mais aprofundada, você pode ler o texto Gravando dados em Python, que explica as combinações de comandos necessárias para gerir diretamente esse processo.
Para gravar os dados recebidos em um arquivo, você pode utilizar a função dsd.gravar(), que tem apenas dois parâmetros: nome do arquivo e dados a serem gravados. Essa é uma função que precisa ser usada com cuidado porque ela sobrescreve todos os dados que estiverem porventura gravados anteriormente em um arquivo com o mesmo nome e localização.
import dsd
# define o Uniform Resourse Locator a ser buscado
url = 'Insira a URL que você escolheu'
# define o nome do arquivo a gravar
arquivo_a_gravar = 'Nomedoarquivo.txt'
# requisita os dados ao servidor e o atribui a uma variável string
html = dsd.get(url)
# grava o arquivo
dsd.gravar(arquivo_a_gravar, html)
# imprime na tela uma mensagem que indica que o programa foi concluído
print (f'Gravado arquivo {arquivo_a_gravar}')Este é um código que, uma vez inserido uma URL, é capaz de extrair os dados da página do STF e determinar sua gravação em um arquivo determinado.
Note que, na última linha do código, utilizamos o formato f-string, que permite interpolar strings e variáveis de um modo conciso. A f-string (cadeia de caracteres iniciada com um f' ) permite a interpolação do texto da string com variáveis e comandos, que devem vir sempre entre parênteses. Tudo o que estiver dentro de {} será interpretado como código em python, e não como uma cadeia de caracteres.
Para imprimir um aviso de que o programa foi concluído com êxito, determinamos o print da string f'Gravado arquivo {arquivo_a_gravar}', na qual o termo arquivo_a_gravar não opera como texto, mas como uma variável.
Quando você abrir o arquivo gravado, verá que a maior parte dele é composto por códigos, e que a primeira informação relevante ocorre apenas depois que aparece o título da página:
'ADI, ADC, ADO e ADPF'
O curso Python para juristas já te ensinou a utilizar a função dsd.extrair para extrair um texto de uma string, utilizando marcadores de início e de fim. Se você fizer uma busca por esse texto "ADI, ADC, ADO e ADPF", verá que ele não é um bom marcador porque, como se trata do nome da página, ele aparece em locais anteriores do texto.
Como foi abordado no referido curso, é melhor usar como marcador uma estrutura de HTML que seja única na página, e isso ocorre com a definição de formatação desse título, que é:
'<div class="titulo-formulario">'
Se você buscar no código-fonte por esse formato, ele somente ocorrerá uma vez, de tal forma que podemos complementar nosso código, para que o conteúdo gravado tenha início nesse marcador, o que reduzirá bastante o tamanho dos dados, retirando apenas parcelas da string que serão idênticas em todas as outras páginas. Note que, como há aspas duplas dentro do marcador, a string deve ser marcada com aspas simples, para evitar erros.
Além disso, você pode notar que não há conteúdos relevantes pouco depois do encerramento da sessão em que estão contidas as informações, tampouco há dados relevantes para a extração, o que permite utilizar como marcador de fim:
'<section id="mapa-do-site">'
O código seguinte incorpora esse recorte dos dados e, como já são vários elementos no programa, também incorpora comentários que explicam o que cada parte realiza.
import dsd
# define a url a ser buscado e nome do arquivo a gravar
url = ('https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp' +
'?base=ADI&documento=&s1=6058&numProcesso=6058')
arquivo_a_gravar = 'ADI6058.txt'
# coleta os dados
html = dsd.get(url)
# limita os dados a partir do início do conteúdo
html = dsd.extrair(html,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
# grava o arquivo
dsd.gravar(arquivo_a_gravar, html)
# imprime mensagem de conclusão
print (f'Gravado arquivo {arquivo_a_gravar}')Esse é um passo importante porque o arquivo com o código-fonte completo tinha 116Kb e o arquivo final tem apenas 14Kb, o que reduzirá o espaço em disco e acelerará o processamento dos dados.
3. Extração iterativa
Agora que você aprendeu a localizar os dados de uma página, extraí-los e gravá-los, utilizaremos uma estrutura que já foi trabalhada no curso de Data Science para Juristas, para realizar uma extração iterativa, que busque informações sobre todas as ações em um determinado intervalo.
Uma vez que você identificar os endereços em que estão disponíveis informações que te interessam, você poder partir para a atividade que faz valer a pena o esforço de aprender uma linguagem de programação: iterar a sua busca, de modo que o seu programa seja capaz de extrair os dados de todos os objetos que compõem o seu universo de pesquisa.
Para realizar essa iteração, você precisa entender melhor o modo como o site organiza as informações disponíveis, para poder criar um padrão de requisições que seja capaz de gerar múltiplos urls a serem extraídos.
3.1 Análise da estrutura de endereços
Iterar as buscas de páginas significa buscar várias páginas, uma de cada vez. Se o órgão judiciário disponibilizasse uma API, seria possível que ele criasse um sistema de busca que permitisse uma resposta agregada, que consolidasse os dados disponíveis em uma tabela. Essa, porém, não tem sido a prática do judiciário brasileiro, que disponibiliza apenas as buscas em suas páginas de acompanhamento processual e de jurisprudência.
Nesse contexto, criar um algoritmo que busque os dados de uma série de páginas exige que você desvende, inicialmente, o padrão de organização do site, possibilitando que você desenhe um algoritmo capaz de buscar todas as páginas de interesse para o seu universo.
Cada página da internet tem uma URL. A devida compreensão dos endereços é fundamental porque a nossa capacidade de extrair dados da internet vem, em grande medida, do fato de que os sites adotam sistemas bem definidos de endereçamento dos dados.
Cada site adota uma organização particular, cuja compreensão exige uma análise detida. Para construir extratores, você precisa analisar cuidadosamente o site em que os dados a serem "raspados" estão disponíveis, para entender o sistema de ordenação dos dados utilizados pelo site.
3.1.1 Elementos do URL
Tomemos, por exemplo o endereço da ADI 6058, que utilizamos no exemplo anterior:
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&documento=&s1=6058&numProcesso=6058
Para entender esse endereço, primeiro é necessário segmentá-lo nas partes que os constituem.
Protocolo
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&documento=&s1=6058&numProcesso=6058
Esquema de troca de informações, correspondente ao código que será utilizado na comunicação entre o seu computador e o servidor. HTTP (Hypertext Transfer Protocol) é o protocolo típico de páginas sem criptografia.
Domínio
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&documento=&s1=6058&numProcesso=6058
O domínio indica o endereço do servidor no qual estão as informações. Servidor é o computador onde estão rodando os programas que oferecem publicamente as páginas da internet. São computadores ligados 24h por dia e conectados sempre à rede, para que os conteúdos hospedados neles sejam sempre visíveis.
Subdomínio
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&documento=&s1=6058&numProcesso=6058
Essa parte antes do domínio indica um subdomínio, que é uma subdivisão do endereço do servidor.
Caminho (Path)
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&documento=&s1=6058&numProcesso=6058
O caminho indica o local do servidor em que estão as informações buscadas.
Consulta (Query)
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&documento=&s1=6058&numProcesso=6058
Consulta: conjunto de parâmetros que possibilitam ao servidor identificar a página solicitada, entre as várias páginas alojadas naquele caminho. Nessa query, estão definidos quatro parâmetros, unidos pelo '&':
- base=ADI
- documento=
- s1=6058
- numProcesso=6058
Nesse caso, somente interessam de fato os parâmetros 1 e 4, que nos conduzem ao processo desejado. O parâmetro 2 está vazio e o parâmetro s1 serve apenas para destacar na página as ocorrências do termo que havia sido utilizado na pesquisa. Você pode fazer o teste e verá que o link funciona perfeitamente com a exclusão desses dois parâmetros:
https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base=ADI&numProcesso=6058
Se você olhar o endereço da presente na barra de endereços, acima, verá uma conformação semelhante:
https://dsd.arcos.org.br/dmj02/
A maior diferença estrutural é que o protocolo muda de HTTP para HTTPS, que é um protocolo idêntico ao HTTP, mas com uma camada a mais de informação, permitindo a circulação de informações criptografadas. Por esse motivo, as páginas HTTPS aparecem com uma imagem de cadeado fechado ao lado.
O domínio é "arcos.org.br", sendo que o subdomínio "dsd" completa o endereço deste site, em que foi designado um subdomínio diferente para cada curso alojado nele.
Para chegar a este post, não se usa uma query, pois basta indicar o seu caminho exato. Para informações mais detalhadas sobre os URLs, bem como para a sua conexão com os IPs e os servidores DNS, consulte a página da UFSCar de conceitos básicos de Internet.
Você deve ter notado que a query é constituída pela combinação (por meio do &) de quatro parâmetros de consulta:
- base=ADI
- documento=
- s1=6058
- numProcesso=6058
Se você explorar um pouco esses parâmetros, notará algumas coisas interessantes. Inserir o valor 1 no parâmetro documento (documento=1) conduz a uma resposta que acrescenta um link para a petição inicial, o que seria muito interessante se o link funcionasse (ao menos as minhas tentativas não me levaram a links válidos).
Após algumas tentativas, você deve ter percebido que o s1 indica o termo que foi pesquisado na consulta da página e que alterá-lo não muda a página exibida. Em uma versão anterior da página, esse valor era importante porque esse texto era apresentado em vermelho na exibição, mas isso foi alterado em 2022, o que tornou esse parâmetro irrelevante.
Esses testes sugerem que você pode acessar qualquer ADI que tiver uma página própria nesse sistema por meio da alteração dos parâmetros 1 (base) e 4 (numProcesso). Inclusive, você pode excluir os parâmetros 2 e 3, sem interferência no resultado da consulta.
Agora que você desvendou o padrão de formação dos URLs que conduzem aos dados que você deseja extrair, é preciso criar o mecanismo de iteração, que usará estruturas trabalhadas no Curso de Python para Juristas.
3.2 Módulo gerador de URLs
Se você tiver alguma dificuldade com o Exercício 8, siga a leitura e veja se as sugestões feitas a seguir podem te ajudar a voltar ao exercício e completá-lo.
A primeira coisa a ter em mente é que esse algoritmo pode ser feito de várias formas. Você pode usar diferentes funções de iteração, mas a minha preferida é a for. E o modo pelo qual eu tenho construído esses extratores é definir duas variáveis que podemos alterar facilmente: NumeroInicial e NumeroFinal. O resultado da minha estratégia é:
# define os parâmetros de busca
Classe = "ADI"
NumeroInicial = 1
NumeroFinal = 10
# iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
url = ('https://portal.stf.jus.br/peticaoInicial/verPeticaoInicial.asp?base='
+ Classe
+ '&numProcesso='
+ str(NumeroInicial+n))
print (url)Veja que colocamos o conteúdo da variável url entre parênteses, pois isso permite quebrar as linhas sem afetar a continuidade do texto (desde que você não quebre a linha dentro de uma string). Esse mesmo formato será adotado para outros campos com um código longo.
Para que essa construção funcione bem, é preciso estar atento a alguns detalhes. A Classe é uma variável string, então podemos somá-la com as strings que contém a parte inalterada da URL, e isso gera uma concatenação. Porém, precisamos que NumeroInicial e NumeroFinal sejam variáveis integer, pois necessitamos delas para definir operações matemáticas com elas, sem as quais o iterador não funciona.
Inclusive, você notará que o fato de o Python considerar o valor inicial de "n" como 0, e não como 1, tem uma vantagem em nosso algoritmo: podemos usar "NumeroInicial + n" como sendo a fórmula para definir o número do processo a ser inserido no URL. Nesse caso, é preciso apenas ter o cuidado de transformar o int em str, para poder usar esse número como um nome (que de fato é a função do 'número' na designação dos processos).
O outro cuidado a tomar é que, na definição do range, é preciso somar 1 à diferença entre o NumeroFinal e o NumeroInicial, pois o nosso objetivo é incluir o número final no intervalo a ser buscado (que é de 10 ações e não de 9).
Por fim, devo ressaltar que existem formas mais elegantes de definir a URL (por exemplo, usando {} para entremear a string com as variáveis), mas creio que é mais interessante começar pelo uso do conector +, que deixa bem claro qual é a operação realizada nessa construção e facilita a compreensão da necessidade de converter em string o último valor.
3.3 Finalmente um extrator funcional!
Unindo os módulos de geração de URLs e de Gravação, você terá um resultado semelhante ao algoritmo abaixo. Note que, nesse caso, eu criei uma variável específica para conter uma string com o Número do Processo (calculada com a soma de NumeroInicial + n), para facilitar a sua inserção na URL e no nome do arquivo.
Veja também que foi necessário criar uma variável com o nome do arquivo a ser gravado, para gerar um arquivo por processo.
import dsd
# Definição dos parâmetros de busca
Classe = "ADI"
NumeroInicial = 5480
NumeroFinal = 5500
#iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
# define url a buscar
NumProcesso = str(NumeroInicial+n)
url = ('http://www.stf.jus.br/portal/peticaoInicial/verPeticaoInicial.asp?base='
+ Classe
+ '&documento=&s1=1&numProcesso='
+ NumProcesso)
# define nome do arquivo a gravar
arquivo = Classe + NumProcesso + '.txt'
# busca dados
html = dsd.get(url)
# grava dados no arquivo
dsd.gravar_dados_no_arquivo_nome(arquivo, html)
# exibe mensagem de conclusão
print (f'Gravado arquivo {arquivo}')Note que também alteramos as ações a extrair para os números 5480 a 5500, pois:
- apesar de se mais ampla, trata-se de uma extração relativamente rápida, o que não onera demasiadamente nossos testes, e
- é mais útil analisarmos ações que são relativamente novas (pois os dados tendem a ser mais completos e padronizados do que nas muito antigas), mas não tão novas assim (porque haverá poucos dados sobre julgamentos, que tomam em média mais de cinco anos).
Essa escolha de ações em torno do 5500 tem essa função de nos oferecer um grupo de processos que foram ajuizados há pouco mais de 5 anos.
3.4 Ajustando o extrator básico
Agora que você tem todos os módulos em mãos (Gerador de URL, Extração de dados e Gravação), convém fazer alguns ajustes.
O primeiro ajuste é inverter a ordem da extração, começando do NumeroFinal, pois normalmente a nossa prioridade é alcançar os processos mais recentes. Isso foi feito trocando no código que define a URL o 'NumeroInicial +n' (que gera uma sequência crescente, à medida que n aumenta), por 'NumeroFinal - n' (que gera uma sequência decrescente, à medida que n aumenta).
import dsd
# define os parâmetros de busca
Classe = "ADI"
NumeroInicial = 5480
NumeroFinal = 5500
# iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
# define a url a ser buscada
NumProcesso = str(NumeroFinal-n)
url = ('https://portal.stf.jus.br/'
+ 'peticaoInicial/verPeticaoInicial.asp?base='
+ Classe
+ '&numProcesso='
+ NumProcesso)
# define nome do arquivo a gravar
arquivo = f'{Classe}{str(0)*(4-len(NumProcesso))}{NumProcesso}.txt'
# coleta os dados
html = dsd.get(url)
# limita os dados a partir do início do conteúdo
html = dsd.extrair(html,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
# grava o arquivo
dsd.gravar(arquivo, html)
print (f'Gravado arquivo {arquivo}')Note que também foi adicionado um código para inserir zeros antes do número, a depender de quantos dígitos tem o NumProcesso. Isso é feito para que a ordem alfabética dos nomes dos arquivos seja a mesma ordem dos números. Quando não tomamos essa precaução, a ADI59 viria antes da ADI9, o que gera problemas para identificar os processos nos diretórios.
Porém, antes de passar para uma busca mais extensa, convém incorporar ao seu extrator mais alguns desenvolvimentos que vão facilitar o trabalho de análise.
4. Estratégias de gravação
4.1 Os desafios envolvidos
Todo formato de gravação tem vantagens e desvantagens. O formato proposto multiplica os arquivos gravados, o que facilita o processo de gravação, mas dificulta o processo de consulta, na medida em que abrir um arquivo de cada vez é uma atividade que consome muito processamento. A estratégia de gravar um arquivo com dados de cada processo é simples, possibilita uma consulta bastante intuitiva aos dados gravados, mas que exige depois que o seu computador trabalhe com milhares de arquivos, o que diminui a eficiência dos organizadores. Por outro lado, essa estratégia consegue lidar com muitos dados a partir de uma capacidade de processamento computacional reduzida (pois a capacidade computacional para lidar com cada arquivo é pequena).
Outra estratégia é consolidar os dados em arquivos maiores, o que torna muito mais rápido o processamento dessas informações. Porém, o fato de lidarmos com um volume relativamente grande de dados faz com que termos grandes arquivos abertos desafie a capacidade de processamento do seu PC. Um arquivo com todos os dados a serem coletados das ADIs tem cerca de 600 MB, o que faz com que seja inviável trabalhar com ele com editores de textos simples (como o Bloco de Notas ou o WordPad), que não abrem arquivos tão grandes.
Arquivos com 100 MB já são um desafio para esses editores de texto. Você pode trabalhar com eles dentro do Spyder, usando as ferramentas de Python, mas mesmo assim tomará bastante tempo para gravá-los e processar informações dentro deles. Os dados acima, para cerca de 7000 ADIs, consomem cerca de 66 MB e o meu NotePad demora cerca de um minuto para abrir esse arquivo e mais do que isso para gravar algumas alterações. Não é eficiente, mas serve para visualizar dados e fazer algumas edições bem pontuais.
Uma das estratégias mais típicas é gravar apenas os campos extraídos dos processos, o que gera arquivos mais enxutos, na medida em não são gravados os comandos de formatação do HTML, que tomam parte relevante dos arquivos. Ocorre que, no nosso caso, essa abordagem pode gerar problemas, ao menos no início, tendo em vista que é bem provável que seu levantamento inicial não consiga identificar todas as variáveis relevantes a serem extraídas. Existem dados processuais muito relevantes, mas que somente aparecem em uma quantidade restrita de casos, como o Relator para Acórdão ou os processos apensados. Refazer uma extração, em busca desses dados, pode ser uma estratégia mais onerosa do que gravar os dados em sua máquina para futuras consultas.
Já deve ter ficado claro que a definição da estratégia de gravação dos dados precisa ser medida em termos de custo-benefício. A arquitetura dos primeiros extratores que fizemos foi exatamente a do modelo acima: gravar arquivos relativamente pequenos com os dados de cada processo, o que permite que você analise diretamente o seu conteúdo.
A estratégia que fazemos hoje é a de consolidar os dados coletados em tabelas, pois esse modo de gravação permite uma otimização dos processos de análise dos dados. Porém, devemos ressaltar que a produção dos códigos deve ser feita com um número mais limitado de processos, para que os múltiplos testes necessários possam ser feitos de maneira célere.
4.2 Gravando os dados em formato csv
Para gerar arquivos unificados, você deve gerar dados que se estruturem como uma tabela. Como os dados gerados por esse extrator tendem a ter menos de 100 MB, é viável agrupar as informações em uma única tabela, por meio da utilização iterada da função dsd.write_csv_row(), que grava dados como se fossem linhas de uma tabela construída no modelo CSV (Comma Separated Values).
O que é um CSV? Trata-se de um formato de organização de dado bastante utilizado porque ele permite reduzir a estrutura tridimensional de uma tabela (que combina linhas e colunas) à estrutura unidimensional de uma string. Como muitos editores conseguem trabalhar bem com esse formato, ele se tornou o padrão para a gravação e compartilhamento de arquivos de dados, que podem ser manipulados pelos mais diferentes softwares.
As funções do módulo dsd.py que lidam com csv são construídas a partir da biblioteca csv, que tem funcionalidades gerais para lidar com esse tipo de organização de dados. Para entender melhor sobre csv e sobre as funções do dsd.py relativas a esse tema, leia o seguinte texto.
Para gerar um arquivo csv adequado, sugerimos que você use uma combinação de duas funções:
- dsd.write_csv_header(), que grava um cabeçalho em um arquivo com os nomes das colunas. Esses nomes devem estar em um formato string, com os campos separados por vírgulas.
- dsd.write_csv_row(), que grava uma linha com os dados definidos. Essa função exige que os dados a serem gravados tenham o formato de uma lista.
Para utilizar essas funções, introduzimos também na linha 7 um parâmetro para definir o nome do arquivo a ser gravado, e introduzimos também uma variável processo, definida na linha 29.
import dsd
# define os parâmetros de busca
Classe = "ADI"
NumeroInicial = 10
NumeroFinal = 15
arquivo = 'Controle_Concentrado.txt'
# iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
# define a url a ser buscada
NumProcesso = str(NumeroFinal-n)
url = ('https://portal.stf.jus.br/'
+ 'peticaoInicial/verPeticaoInicial.asp?base='
+ Classe
+ '&numProcesso='
+ NumProcesso)
# coleta os dados
html = dsd.get(url)
# limita os dados a partir do início do conteúdo
html = dsd.extrair(html,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
# define o campo processo, a partir de classe e número
processo = f'{Classe}{str(0)*(4-len(NumProcesso))}{NumProcesso}'
# grava arquivo em formato csv
## grava cabeçalho
dsd.write_csv_header(arquivo, 'processo, dados_CC')
## grava lista com dados em uma linha
dsd.write_csv_row(arquivo, [processo, html])
print (f'processando: {processo}')
print (f'Gravado arquivo {arquivo}')4.3 Últimos ajustes
4.3.1 Inserção da data
Quando você consulta os dados, uma informação importante é a da data de coleta dos dados. Cada vez que você coleta dados sobre um processo, terá informações diferentes, pois pode ser que:
- certos elementos se alterados (como o Relator),
- certas informações sejam corrigidas (devido a erros posteriormente identificados) e, principalmente,
- certos elementos sejam acrescentados posteriormente à extração, como julgamentos ou recursos.
Por esse motivo, convém que toda extração contenha a data na qual ela ocorreu, o que pode ser realizado mediante a utilização da biblioteca datetime. Para inserir apenas o dia da coleta de informações, você pode importar a função date(), que permite você introduzir a data do dia vigente com o simples comando:
date.today()Somente introduzimos agora essa nova informação porque foi apenas no último código que chegamos a uma construção que será bem repetida: a definição de uma lista com as informações a serem gravadas.
4.3.2 Limpeza do arquivo
Por fim, se você abrir o arquivo que gravamos, verá que ele incorpora os dados obtidos em todas as extrações, o que termina gerando várias entradas para o mesmo processo e uma acumulação de dados que deveriam ter sido apagados, por serem informações decorrentes dos nossos testes.
Para evitar essa acumulação de todos os dados, deixando apenas as informações obtidas na última extração (e também o cabeçalho corretamente definido), é possível utilizar a função dsd.limpar_arquivo(), que apaga o conteúdo do arquivo indicado como argumento.
Aproveite e abra também o seu diretório de trabalho e apague os arquivos que resultaram dos nossos testes variados, e que não serão necessários a partir deste momento. Em especial, vale a pena apagar todos os arquivos que têm dados específicos relativos a um processo (ADIs 1 a 10,
import dsd
from datetime import date
# define os parâmetros de busca
Classe = "ADI"
NumeroInicial = 5450
NumeroFinal = 5500
arquivo = 'Controle_Concentrado.txt'
dsd.limpar_arquivo(arquivo)
# iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
# define a url a ser buscada
NumProcesso = str(NumeroFinal-n)
url = ('https://portal.stf.jus.br/'
+ 'peticaoInicial/verPeticaoInicial.asp?base='
+ Classe
+ '&numProcesso='
+ NumProcesso)
# coleta os dados
html = dsd.get(url)
# limita os dados a partir do início do conteúdo
html = dsd.extrair(html,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
# define o campo processo, a partir de classe e número
processo = f'{Classe}{str(0)*(4-len(NumProcesso))}{NumProcesso}'
# grava arquivo em formato csv
## grava cabeçalho
dsd.write_csv_header(arquivo, 'processo, data_extração, dados_CC')
## grava lista com dados em uma linha
dsd.write_csv_row(arquivo, [processo, date.today(), html])
print (f'processando: {processo}')
print (f'Gravado arquivo {arquivo}')