
1. Introdução
Antes de começar esse texto, você já deve ter completado o tutorial Extrator básico de dados judiciais, em que você deve ter aprendido:
- Como identificar padrões nos URL;
- Como extrair textos usando a função dsd.get();
- Como gerar um iterador, usando a função for, para extrair os dados de um conjunto de ADIs;
- Como gravar esses dados em arquivos independentes e unificá-los em um arquivo de formato CSV
Naquele tutorial, você aprendeu a lidar com a página específica do Controle Concentrado, que contém algumas informações selecionadas sobre as ADIs, ADCs, ADOs e ADPFs. Neste tutorial, continuaremos o desenvolvimento daquele algoritmo, incorporando funcionalidades que permitam extrair os dados constantes do banco de informações processuais, que abrange todos os processos do Tribunal e contém dados mais abrangentes sobre cada ação.
2. A pesquisa de informações processuais
No cabeçalho de todas as páginas do STF, aparece o seguinte menu de pesquisa:
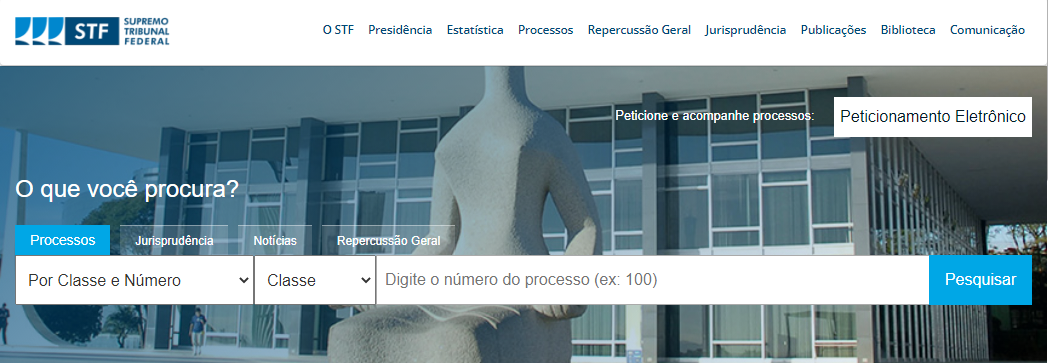
Como toda página da internet, o portal do Supremo está em constante desenvolvimento, o que faz com que algumas das capturas contidas nesta página possam não corresponder exatamente à configuração do site no momento em que você lê o presente texto. No ano passado, por exemplo, a estrutura era um pouco diferente:

Comparando as duas imagens, você deve perceber a parte de transparência tinha mais destaque, pois ficava em um botão sobre a imagem principal, ao lado do Peticionamento Eletrônico. Além disso, imagem focava no rosto da estátua da justiça (e não nas janelas do Tribunal) e a inserção do texto "O que você procura?" aumentou a altura da imagem.
Essas são mudanças superficiais, que não alteram o funcionamento dos nossos programas, mas é natural que também sejam realizadas outras alterações, que modificam o endereçamento das páginas e, por isso, comprometem o funcionamento dos nossos algoritmos. Os endereços da página de Controle Concentrado, por exemplo, foram alterados no início de 2022, o que exigiu uma adaptação dos códigos referentes ao Extrator Básico de Dados Judiciais. Se você notar que alguma alteração está impedindo o funcionamento dos programas referidos nesta página (ou em outras ligadas ao curso de Data Science e Direito), por favor nos avise pelo email alexandrearcos@unb.br.
3. Entendendo as URLs
Quando você insere nessa pesquisa o número de um processo, como da ADI 2222, você é levado a uma página com uma URL construída com base em um identificador (o incidente), que não temos como conhecer de antemão.
http://portal.stf.jus.br/processos/detalhe.asp?incidente=1825664
Esse número do incidente é o identificador único do processo, nos sistemas do Tribunal, e por isso ele é utilizado na query que busca as informações processuais. A dificuldade é que essa variável não é conhecido da antemão e tem valores arbitrários, o que impede a construção de um gerador de endereços com base em tal modelo de pesquisa.
Porém, como a pesquisa que você realizou indicou os parâmetros Classe e Número, é razoável intuir que existe uma maneira alternativa de chegar a esta mesma página, por meio de uma query que utilize esses dois argumentos. Como é possível descobrir esse formato?
Os seus conhecimentos sobre as requisições HTTP já permitem que você inspecione as requisições que são enviadas ao servidor do STF no momento em que você realiza tal pesquisa. De fato, no Data Mining Judicial II, você já utilizou as ferramentas do Inspecionar/Network e localizou que a primeira requisição enviada pelo seu computador ao servidor do STF não indica o endereço que aparece ao final do processo (com o incidente), mas outro:
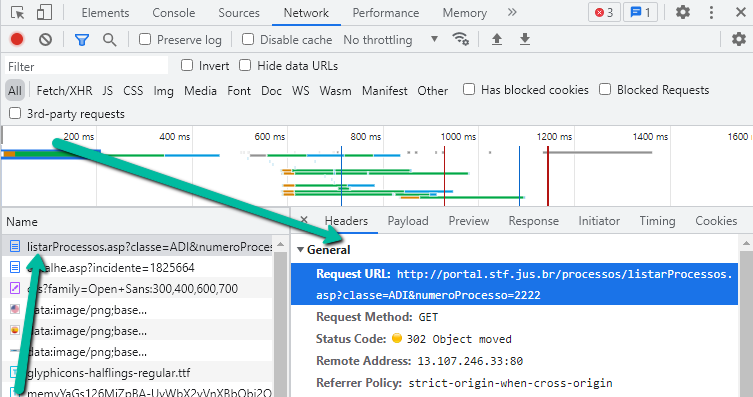
Portanto o localizador utilizado para desencadear o processo de requisição de informações tem o seguinte formato, que utiliza justamente os parâmetros classe e numeroProcesso, o que possibilita construir outros endereços com base no seguinte modelo.
http://portal.stf.jus.br/processos/listarProcessos.asp?classe=ADI&numeroProcesso=2222
4. Identificando as informações a serem extraídas
4. Identificando o campo 'incidente'
Você deve ter chegado facilmente a esses endereços (pois basta substituir a classe e o número no modelo acima), mas essas pesquisas terminam por conduzir a uma página cuja url é formada pelo incidente. Por que isso ocorre?
A resposta é dada quando você explora um pouco mais as abas do Inspecionar/Network e, ao buscar um Preview das informações enviadas em resposta à requisição inicial, obtém o seguinte resultado:
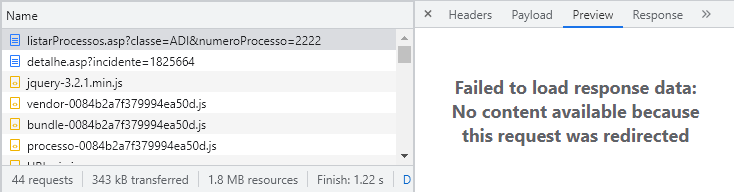
Isso indica que é o próprio servidor do STF que, em vez de oferecer uma resposta à query inicial, simplesmente redireciona a sua requisição para a página cujo endereço é composto pelo incidente. Portanto, embora a pesquisa inicial seja feita com base na classe e no número, sequência da comunicação entre o seu navegador e o servidor do STF é feita com base no número do incidente.
Como incidente é um campo que não aparece em lugar algum da página exibida no navegador, você não seria capaz de encontrá-lo quando utilizava apenas as funções básicas do seu browser. Porém, como você já sabe usar algumas funções mais avançadas, pode abrir o código fonte e buscar dentro dele a informação sobre o incidente.
3.2. O código-fonte e seus scripts
Você deve se lembrar que o Ctrl-U abre o código fonte e, com um Ctrl-F, pode identificar o incidente na linha 47.
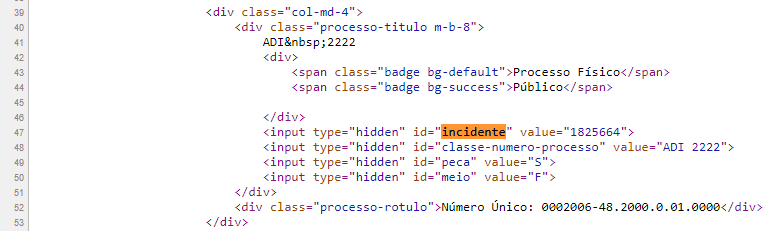
Se você continuar sua exploração do código fonte, verá que ele contém algumas informações vitais a partir da linha 85, como o nome do processo e o relator.
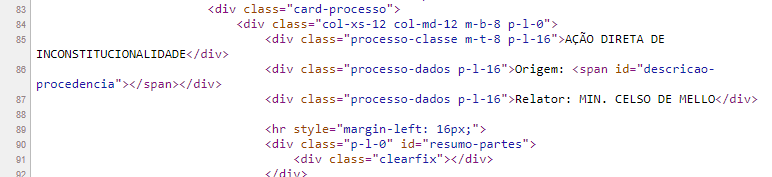
Porém, onde estão as demais informações, como Requerentes e Andamentos?
Esta busca será em vão porque tais informações simplesmente não estão contidas no código-fonte, embora elas apareçam na página exibida pelo navegador.
Por que essas informações não estão contidas no código-fonte? Para melhorar a sua experiência na página. Em vez de o STF enviar para você todos os dados do processo, que podem ser bem grandes e causar uma demora sensível no carregamento da página, o servidor faz um envio escalonado.
- Em primeiro lugar, manda o código-fonte;
- No código-fonte, existem alguns comandos que carregam as informações faltantes, mas isso é feito quando já existem informações na página, o que faz com que alguns elementos apareçam de forma quase imediata e chamem a sua atenção, enquanto o carregamento total é realizado pela porta dos fundos.
Esses comandos são chamados de scripts: pequenos programas que executam algumas funções simples e rápidas, como parte do funcionamento das páginas. Eles são tipicamente escritos na linguagem JavaScript, desenvolvida especialmente para essa função de codificar scripts em páginas de HTML.
Você certamente conhece algumas das principais utilizações de tais scripts: criar barreiras de paywall em jornais on line que têm assinaturas pagas. Esses meios de comunicação enfrentam um dilema: desejam indexar o seu conteúdo nos mecanismos de busca, para que tenham visibilidade, mas querem cobrar pelo acesso a suas reportagens. Isso é comumente resolvido por um mecanismo que envia o conteúdo ao seu computador (porque ele precisa estar no código-fonte para ser indexado), mas depois oculta o texto por meio de comandos de javascript.
Você pode fazer uma experiência com essas funcionalidades por meio da instalação de um plugin do Chrome chamado Toggle JavaScript, que possibilita habilitar e desabilitar a possibilidade de executar scripts nessa linguagem. Quando você desliga o JavaScript, vários dos paywalls deixam de funcionar, mas se você experimentar fazer uma pesquisa de informações processuais no STF, verá que ela tampouco funciona, já que essa busca mediada por um código em JavaScript.
Páginas que utilizam o JavaScript de forma ampla geram desafios para a extração de dados, justamente porque as informações que você deseja acessar podem estar "escondidas" atrás de uma barreira de JavaScript, dificultando a sua coleta. Estratégias mais completas para lidar com esses desafios serão exploradas no Extrator Avançado (ainda em construção), que utiliza a biblioteca Selenium, que é poderosa, mas requer um estudo mais longo e gera algoritmos mais lentos de extração. Também é possível usar a biblioteca Scrapy.
No extrator intermediário, utilizaremos estratégias mais simples para lidar com o JavaScript, mas que não são aplicáveis a todas as situações, mas apenas àquelas nas quais o JavaScript é usado apenas para carregar páginas que têm URLs que podemos identificar.
Essas abordagens não envolvem aprender JavaScript, mas exigem a identificação dos scripts para compreender suas funções básicas. Você pode encontrá-los facilmente porque eles têm marcadores de início e fim característicos: <script> e </script>. Nas páginas de informações processuais, é fácil localizar, por exemplo, os scripts situados entre as linhas 241 e 260.
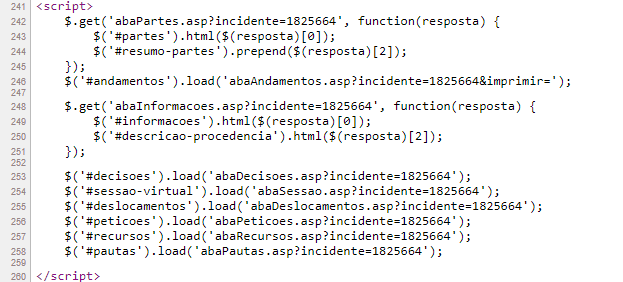
Não é preciso ser programador de JavaScript para entender que os nomes introduzidos por # correspondem justamente às abas da página visualizada no navegador, que contém as informações que buscamos.

Observe que, por padrão, a página abre na aba de Andamentos (sublinhada na visualização inicial), mas que essas outras abas contêm informações processuais relevantes, pelas quais você pode navegar.
Se você observar o Script, verá que um dos primeiros comandos é um .get (que você já sabe que é o nome da principal requisição HTTP) referente à 'abaAndamentos'. Mas o principal ponto a ser observado é que ocorrem no script vários .load (ou seja, carregar) ligados às diversas abas e que cada um deles tem um parâmetro que já deve ser familiar: uma query baseada no incidente, que tem toda a pinta de ser o complemento de um endereço buscado por esses scripts.
Se você explorar a intuição de que essas queries podem ser acopladas ao endereço com o path da página de informações processuais, verá que é possível construir URLs com base neles. Mas existe um caminho mais direto para esses endereços, que você já aprendeu a manejar: o Inspecionar Network. Se você analisar as requisições enviadas pelo seu computador ao STF, no processo de carregar a página da ADI 2222, notará as mesmas queries nas requisições subsequentes, como evidenciado no seguinte video.
Se você der um clique duplo sobre uma dessas queries, abrirá a página correspondente a ela e poderá ver que cada uma delas têm os conteúdos que nos interessam. Uma maneira de ver todos esses endereços é clicar na primeira requisição e escolher a aba Initiator.
Mesmo sem precisar de um estudo específico de JavaScript, você deve ter intuído que o script jquery-3.2.1.min.js carrega as páginas que contém as informações que nos interessam. Além disso, você pode copiar os endereços dessas páginas clicando sobre as respectivas requisições e usando o comando Copy>Link Adress.
Pronto! Com esses modelos de endereços, desde que você consiga extrair o incidente, você pode usar a mesma estrutura que trabalhamos no Extrator Básico de Dados Judiciais e buscar todas as informações relevantes.
3.3 Analisando as informações contidas nas abas
Continuando na ADI 2222, você pode analisar se todas as abas contêm informações relevantes a serem extraídas. As 3 primeiras abas (informações, partes e andamentos) têm muitos dados inequivocamente relevantes.
Já a aba decisões está vazia, o que sugere que essas informações não são plenamente confiáveis, já que há andamentos decisórios no processo. Se você observar outras ADIs, como a 5000, notará que essa aba contém, de fato, informações repetidas: ela mostra os andamentos nos quais existe atribuição do andamento a um ministro específico (que aparece com fundo azul, logo abaixo da data do andamento). Trata-se, pois, de uma página que apenas filtra alguns andamentos, o que torna dispensável extraí-la, o que economiza tempo de processamento e uma request a mais ao servidor do STF.
A aba Sessão Virtual está vazia e se você consultar outros processos, notará que ela permanece vazia, mesmo em casos que foram julgados de forma virtual. Nossa análise indicou que essa aba só contém dados das ações que estão em julgamento no Plenário Virtual, e que podem ser verificadas consultando a pauta da sessão vigente no momento, na página Pauta de Julgamento. Portanto, não faz sentido extrair as informações dessa aba para os processos em geral.
A aba de Deslocamentos é centrada em uma informação que não está contida nos andamentos, que são as Guias de deslocamento, que marcam envios dos processos de uma área para outra. Esse é um dado que, aparentemente, interessa somente a pesquisas focadas nesses deslocamentos, motivo pelo qual não incorporaremos essa informação à nossa base.
A aba de Petições também indica apenas o ingresso de uma petição numerada, mas não têm informações específicas sobre esse peticionamento, que pode ser analisado com mais densidade a partir de uma análise dos andamentos. Por esse motivo, também excluiremos esta aba da nossa base.
A aba Recursos é vazia na ADI 2222, mas consultando outros processos você poderá notar que ele indicará a ocorrência de recursos, o que é uma informação que pode ser relevante quando enfrentarmos o desafio espinhoso de classificar os andamentos decisórios.
Por fim, você também notará que a aba Pautas é constituída por um filtro dos andamentos de 'Pauta Publicada no DJE', o que faz com que tampouco seja necessário extraí-la.
Assim, o nosso extrator pode se limitar a coletar o código-fonte da página inicial e também das abas Informações, Partes, Andamentos e Recursos.
4. Desenvolvendo o código
4.1 Extrair o incidente
Agora que você desvendou a rede de endereços que precisa ser explorada para extrair todas as informações processuais, precisamos desenvolver o Extrator Básico, de forma que ele consiga ampliar o seu escopo.
Para realizar essa função, o primeiro passo é extrair o número do incidente, que você já sabe que é ocorre na linha 47 do código-fonte.
Como já dissemos algumas vezes, há várias formas de conseguir os mesmos resultados. Se você inseriu um novo dsd.get() para conseguir os dados das Informações Processuais e um dsd.extrair() para obter o incidente, você deve ter conseguido gravar um arquivo agora mais rico, por conter agora o nome do processo, o incidente, as informações da página de controle concentrado e as informações da página de informações processuais.
No código abaixo, fazemos uma adaptação do mesmo tipo, sendo que a necessidade de acoplar pesquisas de duas páginas diferentes tornou adequada uma abordagem que deixe clara essa duplicidade. As variáveis ligadas ao Controle Concentrado foram renomeadas com a adição de um '_CC', enquanto os campos ligados às Informações Processuais (IP) estão marcadas como '_IP'. Se você avaliar esse código, verá também alguns ligeiros polimentos, que depois serão descritos.
import dsd
# define os parâmetros de busca
Classe = "ADI"
NumeroInicial = 4595
NumeroFinal = 5500
arquivo = 'InformacoesProcessuais.txt'
dsd.limpar_arquivo(arquivo)
# elementos das URLs
dominio = 'https://portal.stf.jus.br/'
path_CC = 'peticaoInicial/verPeticaoInicial.asp?base='
path_IP = 'processos/listarProcessos.asp?classe='
# iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
# define o número do processo a ser buscado e o campo processo
NumProcesso = str(NumeroFinal-n)
processo = f'{Classe}{str(0)*(4-len(NumProcesso))}{NumProcesso}'
# define as URLs a serem buscadas
url_CC = (dominio + path_CC + Classe + '&numProcesso=' + NumProcesso)
url_IP = (dominio + path_IP + Classe + '&numProcesso=' + NumProcesso)
# coleta e limita os dados relevantes dos códigos-fonte
## controle concentrado
html_CC = dsd.get(url_CC)
html_CC = dsd.extrair(html_CC,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
## informacões processuais
html_IP = dsd.get(url_IP)
html_IP = dsd.extrair(html_IP,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
# extrai o incidente
incidente = dsd.extrair(html_IP,
'<input type="hidden" id="incidente" value="',
'"')
# grava arquivo em formato csv
## grava cabeçalho
dsd.write_csv_header(arquivo, 'processo,incidente, html_CC, html_IP')
## grava lista com dados em uma linha
dsd.write_csv_row(arquivo, [processo, incidente, html_CC, html_IP])
print (f'processando: {processo}')
print (f'Gravado arquivo {arquivo}')Para reduzir o tamanho das linhas com as URLs, e torná-las mais facilmente compreensíveis, definimos na linha 10 um campo domínio (que contem a parte invariável dos endereços), e nas linhas 11 e 12 temos os complementos necessários para gerar os endereços das páginas CC e IP, logo antes de inserir a classe processual. Com isso, as linhas 22 e 23 podem definir as URLs basicamente por meio da concatenação dos conteúdos das variáveis acima referidas (o que as torna mais curtas e mais legíveis).
Além disso, precisamos definir marcadores adequados para que html_IP ficasse apenas com as linhas de 40 a 55, onde estão os únicos conteúdos relevantes desta página (o restante está dentro dos endereços carregados pelo JavaScript).
Por fim veja que definimos uma lista de campos a serem gravados pela dsd.write_csv_row(), mas que o parâmetro da dsd.write_csv_header() é uma string e não uma lista. Por que isso ocorre? Para facilitar essa definição, por meio de um copiar e colar da linha 47.
Do modo como o programa está construído, você pode definir na linha 47 quais são os campos a serem gravados e depois substituir o conteúdo da string que serve como parâmetro para a função do cabeçalho pelo conteúdo entre colchetes da função de gravação (o que é especialmente útil quando você grava um grande número de campos).
4.2 Requisitar os dados das abas
Agora que você conseguiu isolar o campo incidente, pode construir com base nele os extratores das informações contidas em cada uma das abas da página de acompanhamento processual (partes, andamentos, etc.), a partir dos urls que você já identificou no Inspecionar/Network.
Para realizar essa tarefa, era necessário construir uma URL adequada e usar a função dsd.get para extrair os seus dados. Além disso, era preciso adaptar os parâmetros de gravação dos dados e do cabeçalho.
Na janela seguinte, segue uma solução que extrai não apenas as partes, mas também os demais campos faltantes.
import dsd
# Define os parâmetros de busca
Classe = "ADI"
NumeroInicial = 5500
NumeroFinal = 5500
arquivo = 'InformacoesProcessuais2.txt'
dsd.limpar_arquivo(arquivo)
# Elementos das URLs
dominio = 'https://portal.stf.jus.br/'
path_CC = 'peticaoInicial/verPeticaoInicial.asp?base='
path_IP = 'processos/listarProcessos.asp?classe='
# Iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
# redefine variáveis para que, se não houver texto, apareça 'NA'
url_CC = 'NA'
url_IP = 'NA'
incidente = 'NA'
processo = 'NA'
partes = 'NA'
andamentos = 'NA'
informacoes = 'NA'
recursos = 'NA'
# Define o número do processo a ser buscado e o campo processo
NumProcesso = str(NumeroFinal-n)
processo = f'{Classe}{str(0)*(4-len(NumProcesso))}{NumProcesso}'
# Define a URL_IP a ser buscada
url_IP = (dominio + path_IP + Classe + '&numeroProcesso=' + NumProcesso)
html_IP = dsd.get(url_IP)
html_IP = dsd.extrair(html_IP,
'<div class="processo-titulo m-b-8">',
'<div class="clearfix">')
## Condiciona a busca da url_CC controle concentrado
if (Classe == 'ADI'
or Classe == 'ADO'
or Classe == 'ADC'
or Classe == 'ADPF'):
url_CC = (dominio + path_CC + Classe + '&numProcesso=' + NumProcesso)
# Coleta e limita os dados do CC
html_CC = dsd.get(url_CC)
html_CC = dsd.extrair(html_CC,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
# Extrai o incidente
incidente = dsd.extrair(html_IP,'id="incidente" value="','"')
# Extrai as informações das abas relevantes
partes = dsd.get(dominio + 'processos/abaPartes.asp?incidente=' +
incidente)
andamentos = dsd.get(dominio + 'processos/abaAndamentos.asp?incidente=' +
incidente +'&imprimir=')
informacoes= dsd.get(dominio + 'processos/abaInformacoes.asp?incidente=' +
incidente)
recursos = dsd.get(dominio + 'processos/abaRecursos.asp?incidente=' +
incidente)
# Grava arquivo em formato csv, quando há incidente
if incidente != 'NA' and incidente != '':
## Grava cabeçalho
dsd.write_csv_header(arquivo, '''processo,
incidente,
html_CC,
html_IP,
informacoes,
partes,
andamentos,
recursos''')
## Grava lista com dados em uma linha
dsd.write_csv_row(arquivo, [processo,
incidente,
html_CC,
html_IP,
informacoes,
partes,
andamentos,
recursos])
## Imprime aviso de que a ação foi processada
print (f'processado: {processo}')
# Imprime aviso de finalização do programa
print (f'Gravado arquivo {arquivo}')Lendo esse código, você vai notar algumas novidades.
- A partir da linha 19, definimos todas as variáveis usadas como 'NA', garantindo algum funcionamento imprevisto possa gerar uma herança indevida dos valores do último ciclo realizado. Você já viu que uma variável só é modificada quando ela é redefinida e, por isso, é mais seguro fazer essa redefinição no início de cada loop.
- A existência de duas combinações de url e dsd.get() faz com que seja melhor agrupar esses blocos, especialmente porque os dados do CC só devem ser buscados caso se trate de algumas ações específicas e, agora, o seu extrator pode coletar dados de outros tipos processuais.
- Também foi inserida uma condicionante para só gravar dados de processos com incidente, o que exclui números processuais que não correspondem a ações, o que ocorre no caso de alguns processos com autuação anulada e, principalmente, números que fazem sentido mas se designam ações que ainda não foram protocoladas (como a ADI 7100, no momento em que escrevemos esse texto).
5. Gestão das interrupções de extração
Agora que você tem um programa capaz de extrair muitos dados ao mesmo tempo, e gravá-los adequadamente, você precisa lidar com uma contingência: você fatalmente será captado pelo 'radar' do STF para 'robôs', que são cada vez mais comuns e cujo uso indiscriminado pode gerar causam sobrecarga no sistema. Isso faz com que, em extrações a partir de uma centena de processos, você tem um risco substancial de que sua conexão com o host pode ser encerrada unilateralmente e você receba uma mensagem do tipo:
ConnectionError: HTTPConnectionPool(host='portal.stf.jus.br', port=80): Max retries exceeded with url: /processos/abaRecursos.asp?incidente=3855802 (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000002E570C11FD0>: Failed to establish a new connection: [WinError 10060] Uma tentativa de conexão falhou porque o componente conectado não respondeu\r\ncorretamente após um período de tempo ou a conexão estabelecida falhou\r\nporque o host conectado não respondeu'))5.1 Módulo de espera
Se o sistema derrubar o seu extrator com muita frequência, você precisará eliminar o comando dsd.limpar_arquivo, pois será necessário manter os dados já extraídos. Além disso, deverá inserir um módulo de espera, que reduz o ritmo de requisições realizadas e, com isso, diminui o risco de você ser derrubado rapidamente. De toda forma, a velocidade de extração é limitada.
Com a minha máquina e a minha conexão, o referido extrator é capaz de realizar cerca de 600 consultas por hora. As esperas aumentam esse tempo, mas evitam que você tenha de reiniciar as consultas com frequência.
O dsd.py a função dsd.esperar(), construída a partir da função time.sleep(), que tem 3 parâmetros a serem defindos:
- o tempo de espera, em segundos;
- o número de ciclos (loops) entre cada tempo de espera
- a variável que define o número de loops.
Com isso, você pode colocar depois do for n in range() um comando como:
dsd.esperar (2, 5, n)Costumo colocar esse módulo logo depois do primeiro for, de tal forma que, de cinco em cinco processos (tecnicamente, quando a divisão da variável n por 5 não gerar resto), o programa fica parado pelo tempo que você definir. Em 2020, 1 ou 2 segundos bastavam para garantir uma extração com mais de uma hora de duração, que é capaz de solicitar os dados de mais de 500 processos. Neste ano, para garantir uma extração com menos interrupções pelo servidor, estou usando intervalos bem maiores.
dsd.esperar(8,7,vezes)
dsd.esperar(600,70,vezes)Esses valores precisam ser bem trabalhados, pois a sua otimização depende da qualidade de sua conexão e da velocidade do seu computador. Se você for derrubado muito rápido, pode aumentar o tempo ou gerar novas esperas. Eu tenho intercalado esperas menores a cada 7 ciclos e esperas maiores (de 10 min) a cada 70 ciclos. Isso gera um maior tempo de espera, mas possibilita extrações sem muitas suspensões pelo servidor, o que acaba economizando tempo. Com essa configuração de tempo de espera, em 14/02/2021, consegui extrair cerca de 900 ações em 3 horas de processamento.
5.2 Retomada facilitada
Uma estratégia para facilitar a retomada dos trabalhos, após uma interrupção, e fazer uma leitura dos dados que já foram inseridos e excluí-los do processo de coleta de informações. Se você não fizer isso automaticamente, terá de ajustar manualmente os parâmetros de busca, identificando os processos que já foram processados e alterando os números de início e fim da extração.
No código a seguir, inserimos um mecanismo que cria uma lista dos processos já gravados e insere uma condiciona, buscando novos processos apenas nos casos em que eles não estejam na lista. Para essa operação, é necessário importar a biblioteca os, que tem o comando os.list(), que gera uma listagem dos arquivos em um determinado diretório.
Como é possível ter, então, processos extraídos em diferentes datas, inserimos também (a partir da biblioteca date), uma informação sobre a data na qual foi realizada a extração. E, com isso, chegamos ao fim do extrator intermediário de dados.
Por fim, definimos que a gravação de dados somente deve ocorrer quando estiver presente o campo incidente, pois existem alguns nomes de processos que não correspondem a processos existentes na base (sendo nomes processuais com sentido, mas sem conteúdo). Por fim, note que definimos os parâmetros de coleta para as ações 500 a 5500, constituindo um grupo de 500 processos, que serão usados como base para a construção do Organizador.
6. Extrator_STF.py: versão final
import dsd, os
from datetime import date
# Define os parâmetros de busca
Classe = "ADI"
NumeroInicial = 5000
NumeroFinal = 5500
arquivo = 'InformacoesProcessuais2.txt'
# dsd.limpar_arquivo(arquivo) # acione essa linha quando quiser limpar
processos_gravados = []
processos_consultados = 0
# Identifica os processos já gravados
if arquivo in os.listdir():
arquivo_presente = True
else:
arquivo_presente = False
if arquivo_presente:
dados_gravados = dsd.csv_to_list(arquivo)
for item in dados_gravados:
processos_gravados.append(item[0])
# Elementos das URLs
dominio = 'https://portal.stf.jus.br/'
path_CC = 'peticaoInicial/verPeticaoInicial.asp?base='
path_IP = 'processos/listarProcessos.asp?classe='
# Iteração para gerar as urls
for n in range (NumeroFinal-NumeroInicial+1):
# redefine variáveis para que, se não houver texto, apareça 'NA'
url_CC = 'NA'
url_IP = 'NA'
incidente = 'NA'
processo = 'NA'
partes = 'NA'
andamentos = 'NA'
informacoes = 'NA'
recursos = 'NA'
# Define o número do processo a ser buscado e o campo processo
NumProcesso = str(NumeroFinal-n)
processo = f'{Classe}{str(0)*(4-len(NumProcesso))}{NumProcesso}'
# evita a busca de processos já gravados
if processo not in processos_gravados:
# módulo de espera
processos_consultados = processos_consultados + 1
dsd.esperar(17, 15, processos_consultados)
dsd.esperar(60, 70, processos_consultados)
dsd.esperar(300, 400, processos_consultados)
# Define a URL_IP a ser buscada
url_IP = (dominio + path_IP + Classe +
'&numeroProcesso=' + NumProcesso)
html_IP = dsd.get(url_IP)
html_IP = dsd.extrair(html_IP,
'<div class="processo-titulo m-b-8">',
'<div class="clearfix">')
## Condiciona a busca da url_CC controle concentrado
if (Classe == 'ADI'
or Classe == 'ADO'
or Classe == 'ADC'
or Classe == 'ADPF'):
url_CC = (dominio + path_CC + Classe +
'&numProcesso=' + NumProcesso)
# Coleta e limita os dados do CC
html_CC = dsd.get(url_CC)
html_CC = dsd.extrair(html_CC,
'<div class="titulo-formulario">',
'<section id="mapa-do-site">')
# Extrai o incidente
incidente = dsd.extrair(html_IP,'id="incidente" value="','"')
# Extrai as informações das abas relevantes
partes = dsd.get(dominio + 'processos/abaPartes.asp?incidente=' +
incidente)
andamentos = dsd.get(dominio + 'processos/abaAndamentos.asp?incidente=' +
incidente +'&imprimir=')
informacoes= dsd.get(dominio + 'processos/abaInformacoes.asp?incidente=' +
incidente)
recursos = dsd.get(dominio + 'processos/abaRecursos.asp?incidente=' +
incidente)
# Grava arquivo em formato csv, quando há incidente
if incidente != 'NA' and incidente != '':
## Grava cabeçalho
dsd.write_csv_header(arquivo, '''processo,
incidente,
date.today(),
html_CC,
html_IP,
informacoes,
partes,
andamentos,
recursos''')
## Grava lista com dados em uma linha
dsd.write_csv_row(arquivo, [processo,
incidente,
date.today(),
html_CC,
html_IP,
informacoes,
partes,
andamentos,
recursos])
## Imprime aviso de que a ação foi processada
print (f'processado: {processo}')
# Imprime aviso de finalização do programa
print (f'Gravado arquivo {arquivo}')






