
1. Introdução
No Organizador Básico, você aprendeu as funcionalidades básicas para criar organizador de dados que gera uma base estruturada de dados, no formato de um csv. Neste ponto, você deve ser capaz de:
- Definir um Modelo de Dados;
- Leitura dos arquivos que contém os dados extraídos;
- Extrair os dados definidos no modelo;
- Limpeza dos dados;
- Gravar os dados em uma tabela.
2. Campos compostos por listas
No presente texto, passamos a um segundo nível de complexidade: extrair dados que não são unitários, mas que são conjuntos de dados. Nos dados unitários, você pode extrair strings menores (como no caso do incidente ou da classe), ou strings maiores (como no caso da legislação impugnada ou da decisão monocrática).
Porém, há vários dados processuais que não são objetos simples, mas conjuntos de objetos, tais como:
- Partes de um processo;
- Andamentos processuais;
- Decisões;
- Recursos.
De fato, o organizador básico gera uma lista de fundamentos, mas esta é uma lista bastante simples, composta de elementos unitários. Essa é uma estratégia que não funciona para os campos de partes e andamentos, que são compostos por dados mais complexos.
Cada processo não tem apenas um andamento (como ele tem uma e apenas uma data de distribuição e um e apenas um relator atual). Assim, na página em que o STF apresenta os andamentos processuais, cada processo tem sempre uma multiplicidade de andamentos. Além disso, cada andamento é composto por vários elementos (data, nome, complemento, etc.).
Essa pluralidade de objetos no mesmo campo faz com que as strings que conseguimos extrair do código-fonte nos ofereçam dados que não se deixam traduzir diretamente em informações úteis: precisamos estruturar esses dados para que o valor do campo andamentos seja uma lista organizada, que possa servir como fonte para as nossas análises.
Se trabalhássemos com bancos de dados relacionais mais complexos (com várias tabelas interligadas), poderíamos criar uma tabela para cada processo e inserir em cada linha a unidade andamento processual. Essa é uma possibilidade efetiva, mas ela agrega demasiada complexidade para os nossos objetivos, que são o de conseguir gerar dados adequados para a pesquisa empírica em direito, com o mínimo possível de ferramentas.
A estratégia que usamos aqui é a de reduzir a complexidade dos conjuntos de dados a uma lista, que tem por objeto os andamentos. Essa é uma saída que faz com que o nosso banco seja relacional (porque é uma tabela), mas ele terá campos complexos (compostos por listas), que demandam uma camada extra de interpretação para que essas informações possam ser usadas nas ferramentas de análise de dados.
Essa estratégia nos faz ter objetos complexos, com informações muito ricas, mas cuja compreensão depende de uma interpretação cuidadosa.
2.1 Listas de Listas
No Extrator Básico de Dados Judiciais, tratava-se de ligar várias informações simples a uma unidade básica, o processo. Agora, temos um novo nível de complexidade, pois os processos são ligados a informações também compostas por um conjunto de dados interligados.
No caso dos andamentos e das partes, temos uma elevada complexidade, pois cada um dos campos (Requerente, Requerido, Julgamento final, Decisão liminar, etc.) tem uma série de atributos (nome, tipo, relator, órgão decisor, etc).
O conjunto dos andamentos de um processo apenas não é uma lista, mas é uma lista de listas: cada andamento contém um conjunto de informações, e não apenas uma informação unitária.
Uma decisão monocrática pode ser uma string longa e complexa, mas podemos gravá-la como um campo simples. Mas todo andamento processual, por mais singelo que seja (como uma autuação), consiste em uma composição de múltiplos atributos, o que faz com que precisemos contar com um modelo de dados complexo. Temos unidades de análise (processos), que têm atributos complexos (uma lista de andamentos), sendo que cada andamento precisa também de um modelo de dados particular (porque ele é uma composição de atributos).
Isso faz com que cada andamento corresponda a uma lista de elementos (nome, complemento, número de ordem, órgão julgador, etc) e que esses vários andamentos sejam inseridos em uma lista, que será o conteúdo do campo andamentos, para cada processo. Toda lista que contém outra lista é chamada de nested list.
Essa peculiaridade faz com que, antes de entrar propriamente na extração dos atributos, seja necessário compreender com precisão o modo de constituição das listas e as formas de construir listas mediante iteração de comandos.
3. As listas em Python
3.1 Estrutura das listas
Como foi estudado no Módulo 2 do Curso de Programação para juristas, as listas são estruturas do Python que constituem exatamente no que o nome indica: uma sequência de elementos que têm duas características básicas:
- O início e o fim da lista são marcados por colchetes,
- Os elementos são elementos separados por vírgulas.
Uma lista de ministros do STF teria o seguinte formato em julho de 2020:
MinistrosSTF = ['Luiz Fux', 'Rosa Weber', 'Marco Aurélio',
'Gilmar Mendes', 'Ricardo Lewandowski', 'Cármen Lúcia',
'Dias Toffoli', 'Roberto Barroso', 'Edson Fachin',
'Alexandre de Moraes']
Uma das vantagens da lista é que ela é uma conjunto dos elementos mais diversos: pode-se combinar dentro delas strings, variáveis, números e, inclusive, outras listas. Tudo o que você quiser, pode entrar numa lista, o que faz com que elas sejam ótimas para armazenar conjuntos heterogêneos de dados, como é o caso de um andamento processual.
Outra característica da lista é que ela ordena os elementos e confere a cada um deles uma posição:
- MinistrosSTF[1] indica o segundo elemento da lista;
- MinistrosSTF[0] indica o primeiro elemento da lista;
- MinistrosSTF[2] indica o terceiro elemento da lista;
- MinistrosSTF[-1] indica o último elemento da lista;
- MinistrosSTF[-2] indica o penúltimo elemento da lista.
Essa notação é muito prática e, não por acaso, ela se parece muito com a notação das strings. A diferença é que a string é um conjunto de caracteres, de tal forma que string[0] indica o primeiro caractere de uma sequência, enquanto a lista é um conjunto de objetos, sendo que lista[0] indica o segundo elemento da sequência.
O único problema dessa notação é que ela é a principal causa de erros que levam ao travamento dos meus programas. Se inserirmos em um código o MinistrosSTF[10], ele vai travar e indicar que houve erro porque o código faz referência a um elemento fora do range da lista. Isso costuma ocorrer quando fazemos um cálculo de que o Tribunal tem 11 ministros, mas esquecemos de que um deles pode se aposentar e a corte pode ficar apenas com os elementos de 0 a 9.
3.2 Funções pop() e append()
Para lidar com as listas, existem várias ferramentas. No Gerador de CSV, utilizamos o listdir() para gerar uma lista dos processos em um diretório, que usamos para fazer iterações. Como nosso objetivo é utilizar o mínimo de ferramentas, vamos aprender apenas mais dois comandos para gerir listas.
A função mais importante é o append, que significa literalmente apensar, anexar. No Python, um comando do tipo lista.append(objeto) acrescenta o objeto entre parênteses ao final de uma lista. A posse do min. Nunes Marques exigiu que acrescentemos um novo nome, o que poderemos fazer pelo comando:
MinistrosSTF = ['Luiz Fux', 'Rosa Weber', 'Marco Aurélio', 'Gilmar Mendes',
'Ricardo Lewandowski', 'Cármen Lúcia', 'Dias Toffoli',
'Roberto Barroso', 'Edson Fachin', 'Alexandre de Moraes']
MinistrosSTF.append('Nunes Marques')
print (MinistrosSTF)
Para retirar o último elemento da lista, você pode usar a construção:
MinistrosSTF = MinistrosSTF[0:-1]Uma outra função interessante é a pop(), que exclui um elemento da lista e retorna o elemento retirado.
ultimo_ministro = MinistrosSTF.pop()A função pop() possibilita uma escrita mais concisa do código:
ultimo_ministro = MinistroSTF[-1]
MinistrosSTF = MinistrosSTF[0:-1]4. O campo de Partes
4.1 Abrindo as informações sobre partes
No organizador básico, você já aprendeu a carregar os dados gravados no arquivo 'InformacoesProcessuais.txt' e a extrair deles informações simples. Neste momento, você aprenderá a extrair as informações mais complexas, contidas nos campos de partes e andamentos.
Nas ADIs, são possíveis várias partes: Requerentes, Amici Curiae, Interessados (que antes eram chamados de Requeridos), Advogados. Na elaboração do extrator intermediário, nós identificamos que as informações referentes às partes processuais ficam disponíveis em endereços que seguem o seguinte padrão, construído a partir do identificador 'incidente':
https://portal.stf.jus.br/processos/abaPartes.asp?incidente=1480010
Esses dados foram extraídos e inseridos dentro do arquivo 'InformacoesProcessuais.txt', na sétima coluna (index=6) do texto. Como a extração completa é muito longa, fizemos esse pequeno programa para poder ler apenas as informações da ADI 1:
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[-1:]Este programa abre o arquivo, carrega os dados e os dispõem em ordem alfabética descrescente, o que faz com que o último elemento (index = -1) seja justamente o da ADI 1.
Rodando esse programa, você poderá abrir no explorador de variáveis o campo "dados", uma nested list cujo único elemento é justamente a lista com o conjunto de informações referentes à ADI0001. Você pode abrir esta lista com nove elementos, dos quais o sétimo (index = 6) é justamente o conjunto de dados referente às partes. No video abaixo, abrimos, selecionamos (com o Ctrl-A) e copiamos estes dados.
Colamos abaixo os dados copiados, para podermos analisá-los.
<div id="todas-partes">
<div class="processo-partes lista-dados m-l-16 p-t-0">
<div class="detalhe-parte">REQTE.(S)</div>
<div class="nome-parte">GOVERNADOR DO ESTADO DE RONDÔNIA</div>
</div>
<div class="processo-partes lista-dados m-l-16 p-t-0">
<div class="detalhe-parte">ADV.(A/S)</div>
<div class="nome-parte">ERASTO VILLA VERDE DE CARVALHO</div>
</div>
<div class="processo-partes lista-dados m-l-16 p-t-0">
<div class="detalhe-parte">INTDO.(A/S)</div>
<div class="nome-parte">ASSEMBLÉIA LEGISLATIVA DO ESTADO DE RONDÔNIA</div>
</div>
<div class="processo-partes lista-dados m-l-16 p-t-0">
<div class="detalhe-parte">INTDO.(A/S)</div>
<div class="nome-parte">GOVERNADOR DO ESTADO DE RONDÔNIA</div>
</div>
</div>
<div id="partes-resumidas">
<div style="display: flex; flex-direction:row">
<div class="processo-partes m-t-4 col-md-2">REQTE.(S)</div>
<div class="processo-partes m-t-4 col-md-8">GOVERNADOR DO ESTADO DE RONDÔNIA </a></div>
</div>
<div style="display: flex; flex-direction:row">
<div class="processo-partes m-t-4 col-md-2">ADV.(A/S)</div>
<div class="processo-partes m-t-4 col-md-8">ERASTO VILLA VERDE DE CARVALHO </a></div>
</div>
<div style="display: flex; flex-direction:row">
<div class="processo-partes m-t-4 col-md-2">INTDO.(A/S)</div>
<div class="processo-partes m-t-4 col-md-8">ASSEMBLÉIA LEGISLATIVA DO ESTADO DE RONDÔNIA </a></div>
</div>
<div style="display: flex; flex-direction:row">
<div class="processo-partes m-t-4 col-md-2">INTDO.(A/S)</div>
<div class="processo-partes m-t-4 col-md-8">GOVERNADOR DO ESTADO DE RONDÔNIA </a></div>
</div>
</div>Diversamente do que ocorre quando você observa o código-fonte da página, o encoding de nossa base de dados está adequadamente definido, o que possibilita uma exibição correta das informações.
Você deve ter percebido que há dois conjuntos de informações nesse mesmo trecho de código. Entre as linas 1 e 31 estão contidas as informações de todas as partes, marcadas pelo id="todas-partes". A partir da linha 32, há uma repetição das mesmas informações, em um conjunto de partes selecionadas (id="partes-resumidas"), sendo que a análise de outros processos indica que são excluídos dessa lista os amici curiae e alguns advogados. Como nos interessa o conjunto total das partes, convém cuidar para a extração opere apenas no primeiro trecho, o que pode ser feito alterando a linha 59 para:
partes = dsd.extrair(item[6], '', '<div id="partes-resumidas">')Observando os dados acima, você percebe que há uma designação de vários atores processuais, sendo que existe um marcador que indica o início do trecho referente a cada um deles:
<div class="processo-partes lista-dados m-l-16 p-t-0">'A presença desse marcador permite que utilizemos uma estratégia de segmentação da string, que seja capaz de gerar uma lista com todas as partes, a partir da função split(), que gera uma lista, segmentando a string em cada ocorrência do argumento.
partes = partes.split('<div class="processo-partes lista-dados">')Note que a função acima realiza uma segmentação da string partes, gerando uma lista com todas as partes do processo. Com isso, esse algoritmo faz com que a variável partes deixa de ser uma string e passa a ser uma lista.
Feita essa segmentação, é preciso organizar os dados e limpá-los, de forma que o código gere uma lista adequada de partes. Para simplificar esse processo, o módulo dsd tem uma função listar_partes(string, processo), que extrai as partes contidas em uma string (que siga o mesmo padrão usado no STF) e retorna os dados de modo organizado, inclusive com a informação específica do processo em que a parte ocorre.
Essa é uma informação relevante porque ela permite modificar a unidade de análise: em vez de uma tabela de processos, com todas as partes ligadas a eles, podemos gerar uma listagem das partes, o que permitirá fazer análises sobre os atores individualmente considerados.
Se você observar o módulo dsd.py, verá que essa função tem os seguintes comandos, que segmentam a string e geram uma lista com os dados que são extraídos de cada um dos itens que compõem a lista gerada pela função split.
def listar_partes(string, processo):
string = remover_acentos(string)
partes = string.split('<div class="processo-partes lista-dados m-l-16 p-t-0">')
lista_partes = []
for parte in partes[1:]:
tipo = extrair(parte, 'detalhe-parte">', '<').upper()
tipo = tipo.replace('REQTE.(S)','REQTE')
tipo = tipo.replace('INTDO.(A/S)','INTDO')
tipo = tipo.replace('REQDO.(A/S)','INTDO')
tipo = tipo.replace('ADV.(A/S)','ADV')
tipo = tipo.replace('AM. CURIAE.','AMICUS')
tipo = tipo.replace('PROC.(A/S)(ES)','ADV/PUB')
tipo = limpar(tipo)
nome = extrair(parte, '"nome-parte">', '<').upper()
nome = ajustar_nome(nome)
if tipo == 'ADV' or tipo == 'ADV/PUB':
if "(" in nome:
nome = extrair(nome, '', '(')
nome = nome.strip()
nome = nome.replace(' ',' ')
lista_partes.append([nome, tipo, processo])
return lista_partesPara usar essa função, basta inserir no seu código uma linha:
lista_das_partes = dsd.listar_partes(partes, processo)5. O campo andamentos
5.1 O modelo de dados
O campo mais importante e rico das páginas de acompanhamento processual é o dos andamentos. Esse é também o campo mais desafiador, dada a heterogeneidade das informações contidas nos andamentos processuais.
Observando o que fizemos no campo parte, você pode notar que o primeiro passo é fazer um modelo de dados para os andamentos. Quais são os campos que levantaremos com relação a cada andamento específico? Precisamos disso para poder gerar uma função capaz de retornar uma lista com os andamentos.
O primeiro passo é buscar andamentos que sejam complexos, pois os andamentos simples não têm todos os campos de informação preenchidos. Nesse caso, uma estratégia importante é fazer uma pesquisa da ADI6000 pelo navegador, para observar a diversidade dos andamentos e buscar alguns que sejam especialmente completos.
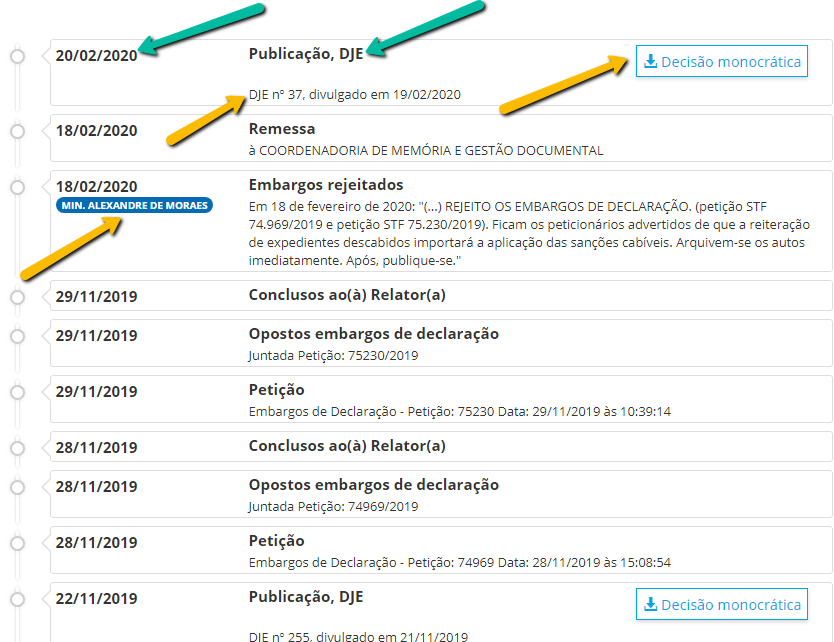
Essa análise nos mostra que somente três campos parecem ser comuns a todos os andamentos, que são indicados em verde na figura acima.
- Data: todo andamento tem uma data;
- Nome: todo andamento tem um nome, que aparece em negrito;
- Número na lista: esse não é um campo com informações contidas diretamente na página, mas que pode ser construído tal como fizemos com os requerentes. Essa numeração dos andamentos é útil para a ordenação, pois o Python ordena facilmente os campos em ordem crescente (ou decrescente), mas é mais complexo ordená-los por data (especialmente porque o campo de data pode ter vários formatos). Neste caso, é importante ordenar os andamentos do último para o primeiro, pois a ordem de ocorrência é inversa.
Além disso, existem 3 campos que ocorrem apenas em alguns andamentos:
- Link para download de arquivo: no caso dos andamentos da figura acima, são textos de decisões monocráticas;
- Complemento: em letra normal, sem negrito. Enquanto o título do andamento é escolhido em uma lista de andamentos possíveis, o complemento parece ser escrito livremente por quem lança o andamento. Trata-se do elemento mais 'livre' do andamento, e por isso mesmo o mais heterogêneo.
- Órgão julgador: no andamento "Embargos Rejeitados", aparece o nome do min. Alexandre de Moraes. Porém, quando avançamos na lista de andamentos, podemos identificar também outros conteúdos para esse mesmo campo, como no caso da decisão Procedente:

Essa imagem mostra o andamento da decisão final de mérito, que foi colegiada, de tal forma que não aparece o ministro relator, mas um órgão do STF. Isso permite que desdobremos as informações contidas nesse campo para nos indicarem dois dados diferentes:
- Órgão julgador: ministro (no caso de monocráticas) ou órgão (no caso de colegiadas) que editou o andamento decisório. No caso de andamento não-decisório, o valor é NA.
O resultado dessa análise nos aponta para o seguinte modelo de dados:
- Posição: posição do andamento na lista
- Data: valor de uma data específica
- Nome: que segue uma lista finita de possibilidades
- Complemento: que é um texto livre
- Link: presente apenas em alguns casos
- Órgão julgador: com valores de ministros (nas monocráticas) ou de órgãos (nas colegiadas)
5.2 Extraindo os andamentos
Definido o modelo de dados, a extração dos andamentos pode ser feita por uma adaptação da mesma lógica da extração das partes: identificar o marcador para split e depois identificar os marcadores de início e fim de cada elemento.
Essa extração é feita pela função dsd.extrair_andamentos.py, que tem como único parâmetro a string em que estão gravados os dados a serem extraídos. Você pode consultar o módulo dsd.py, para analisar a funç
def extrair_andamentos(string):
string = remover_acentos(string)
string = limpar(limpar(string))
andamentos = string.split('<div class="andamento-item">')
n= len(andamentos)
lista_andamentos = []
for andamento in andamentos[1:]:
data = 'NA'
nome = 'NA'
complemento = 'NA',
docs = 'NA'
julgador = 'NA'
decisao_tipo = 'NA'
# com esse formato, os andamentos indevidos não são incorporados, pois a classe deles envolve 'andamento indevido', para gerar o taxado
n = n-1
ordem = str(n).zfill(4)
andamento = andamento.replace('"col-md-9 p-0 "','"col-md-9 p-0"')
data = extrair(andamento, '<div class="andamento-data ">','</div>').upper()
nome = extrair(andamento, '<h5 class="andamento-nome ">','</h5>').upper()
complemento = extrair(andamento, '<div class="col-md-9 p-0">','</div>').upper()
if complemento == ' ' or complemento == '':
complemento = 'NA'
docs = extrair(andamento, '"col-md-4 andamento-docs">','</div>')
if docs == ' ' or docs == '':
docs = 'NA'
if 'href=' in docs:
docs = extrair(docs,'href="', '"')
julgador = extrair(andamento, 'julgador badge bg-info ">','</span>').upper()
#print ([ordem, data, nome, complemento, docs, julgador])
lista_andamentos.append([ordem, data, nome, complemento,
docs, julgador])
return lista_andamentos6. Organizador geral de dados processuais
Com essas complementações, o organizador é capaz de processar as informações processuais e transformá-las em uma tabela.
O fato de que alguns campos são demasiadamente grandes fez com que gravemos um arquivo específico com os andamentos e deixemos no arquivo geral apenas os últimos 10 andamentos de cada processo, o que possibilita uma observação rápida de sua situação atual.
Já para o caso das partes e dos andamentos, precisamos de um organizador específico, capaz de lidar com as complexidades desses dados.
import dsd
# Importa dados do arquivo indicado como parâmetro
dados = dsd.csv_to_list('InformacoesProcessuais.txt')
# Coloca os dados em ordem alfabética decrescente
dados.sort(reverse = True)
# Retira o cabeçalho e limita a quantidade inicial de processos
dados = dados[1:]
# Define arquivo a gravar
arquivo = 'STF_total.txt'
dsd.limpar_arquivo(arquivo)
dsd.limpar_arquivo('dispositivos_CC.txt')
dsd.limpar_arquivo('STF_andamentos.txt')
# Cria lista para armazenar todos os dados
dados_totais = []
# Iteração para extrair os dados de cada processo
for item in dados:
# Redefine variáveis
processo = 'NA'
incidente = 'NA'
protocolo_data = 'NA'
eletronico_fisico = 'NA'
sigilo = 'NA'
numerounico = 'NA'
assuntos = 'NA'
orgaodeorigem = 'NA'
origem_sigla = 'NA'
numerodeorigem = 'NA'
pedido_de_liminar_CC = 'NA'
origem_CC = 'NA'
entrada_CC = 'NA'
relator_CC = 'NA'
requerente_tipo_CC = 'NA'
dispositivo_CC = 'NA'
fundamento_CC = 'NA'
resultado_liminar_CC = 'NA'
orgao_liminar_CC = 'NA'
resultado_final_CC = 'NA'
orgao_resultado_final_CC = 'NA'
monocratica_final_CC = 'NA'
indexacao_CC = 'NA'
prevencao_CC = 'NA'
# Defindo campos já individualizados
processo = item[0]
incidente = item[1]
data_extracao = item[2]
html_CC = item[3]
html_IP = item[4]
informacoes = item[5]
partes = dsd.extrair(item[6], '', '<div id="partes-resumidas">')
andamentos = item[7]
recursos = item[8]
# Extrai dados do campo html_IP
eletronico_fisico = dsd.extrair(html_IP,'bg-primary">','</span>')
eletronico_fisico = eletronico_fisico.replace('Processo Eletrônico','E')
if eletronico_fisico != 'E':
eletronico_fisico = dsd.extrair(html_IP,'bg-default">','</span>')
eletronico_fisico = eletronico_fisico.replace(
'Processo Físico','F')
sigilo = dsd.extrair(html_IP,'bg-success">','</span>').upper()
sigilo = sigilo.replace('PÚBLICO','P')
nome_processo =dsd.extrair(html_IP,'-processo" value="','">')
numerounico = dsd.extrair(html_IP,'-rotulo">','</div>')
numerounico = dsd.extrair(numerounico,': ', '')
relator_IP = dsd.extrair(html_IP, '>Relator:','<')
relator_IP = relator_IP.strip(' ')
relator_IP = relator_IP.replace('MIN. ','')
relator_IP = dsd.remover_acentos(relator_IP)
redator_acordao = dsd.extrair(html_IP,'>Redator do acórdão:','</div>')
redator_acordao = dsd.remover_acentos(redator_acordao)
redator_acordao = redator_acordao.replace('MIN. ','')
redator_acordao = redator_acordao.strip(' ')
redator_acordao = redator_acordao.replace ('MINISTRO ','')
relator_ultimo_incidente = dsd.extrair(html_IP,
'Relator do último incidente:'
,'</div>')
relator_ultimo_incidente = relator_ultimo_incidente.replace ('MIN. ','')
relator_ultimo_incidente = relator_ultimo_incidente.replace ('MINISTRO ','')
relator_ultimo_incidente = relator_ultimo_incidente.strip(' ')
relator_ultimo_incidente = dsd.remover_acentos(relator_ultimo_incidente)
ultimoincidente = dsd.extrair(relator_ultimo_incidente,"(",'')
relator_ultimo_incidente = dsd.extrair(relator_ultimo_incidente,'','(')
ultimoincidente = ultimoincidente.replace(')','')
ultimoincidente = ultimoincidente.strip(' ')
apensado_a = dsd.extrair(html_IP,'Apenso Principal:','</a>')
apensado_a = dsd.limpar(apensado_a)
if apensado_a != 'NA':
apensado_a = dsd.limpar(dsd.extrair(apensado_a,'>',''))
lista_processos_apensados = []
processos_apensados = dsd.extrair(html_IP,
'Processo(s) Apensado(s):','</div>')
processos_apensados = dsd.limpar(processos_apensados).replace(' ','')
if processos_apensados != 'NA':
processos_apensados = processos_apensados.split('</a>')[:-1]
for item in processos_apensados:
processos_apensados = dsd.limpar(dsd.extrair(item,'>',''))
lista_processos_apensados.append(processos_apensados)
# Extrai dados do campo informacoes
assuntos = dsd.extrair(informacoes,
'<ul style="list-style:none;">',
'</ul>').upper()
assuntos = dsd.remover_acentos(assuntos)
assuntos = dsd.limpar(assuntos)
assuntos = dsd.extrair(assuntos,'<LI>','')
assuntos = assuntos.replace('</LI>','')
assuntos = dsd.limpar(assuntos)
assuntos = assuntos.split('<LI>')
protocolo_data = dsd.extrair(informacoes,
'Data de Protocolo:',
'Órgão de Origem:')
protocolo_data = dsd.extrair(protocolo_data, 'm-l-0">','</div>')
protocolo_data = protocolo_data.replace('\n','')
protocolo_data = protocolo_data.strip()
orgaodeorigem = dsd.extrair(informacoes,'Órgão de Origem:','Origem')
orgaodeorigem = dsd.extrair(orgaodeorigem,'processo-detalhes">','<')
orgaodeorigem = orgaodeorigem.replace('SUPREMO TRIBUNAL FEDERAL','STF')
orgaodeorigem = dsd.limpar(orgaodeorigem)
origem = dsd.extrair(informacoes, '\n Origem:', 'Origem:')
origem = dsd.extrair(origem, 'processo-detalhes">', '<')
origem = dsd.limpar(origem)
origem_sigla = dsd.extrair(informacoes,'procedencia">','<')
origem_sigla = dsd.limpar(dsd.extrair(origem_sigla,'','-'))
numerodeorigem = dsd.extrair(informacoes,
'Número de Origem:\n </div>\n <div class="col-md-5 processo-detalhes">\n',
'</div>')
numerodeorigem = dsd.limpar(numerodeorigem)
numerodeorigem = numerodeorigem.replace(' ','')
numerodeorigem = numerodeorigem.split(',')
if len(numerodeorigem) != 1:
if numerodeorigem[0] == numerodeorigem[1]:
numerodeorigem.pop(1)
# Extrai campo andamentos
andamentos = dsd.extrair_andamentos(andamentos)
if andamentos != []:
data_ultimo_andamento = andamentos[0][1]
else:
data_ultimo_andamento = 'NA'
# Extrai campo partes
lista_das_partes = dsd.listar_partes(partes,processo)
for item in lista_das_partes:
item[0] = dsd.ajustar_nome(item[0])
intdos = ''
for item in lista_das_partes:
if item[1] == 'INTDO':
intdos = intdos + item[0] + ';'
# Aplica função de identificar atos federais
origem_ato = dsd.origem_ato (origem_sigla, intdos)
# Extrai dados do campo html_CC
if ('ADI' in processo or
'ADPF' in processo or
'ADO' in processo or
'ADC' in processo):
## Extrai e trata o campo cln_CC
pedido_de_liminar_CC = dsd.extrair(html_CC,
'<div id="divImpressao"><div><h3><strong>',
'</strong>').upper()
### Remove acentos
pedido_de_liminar_CC = dsd.remover_acentos(pedido_de_liminar_CC)
### Extrai a informação sobre pedido de liminar na petição inicial
if 'LIMINAR' in pedido_de_liminar_CC:
pedido_de_liminar_CC = 'SIM'
else:
pedido_de_liminar_CC = 'NA'
### Reduz o nome da ação para a sigla ADI
pedido_de_liminar_CC = pedido_de_liminar_CC.replace(
'ACAO DIRETA DE INCONSTITUCIONALIDADE',
'ADI')
# Extrai e trata o campo origem_CC
origem_CC = dsd.extrair(html_CC,
'Origem:</td><td><strong>',
'</strong>').upper()
### Remove acentos
origem_CC = dsd.remover_acentos(origem_CC)
## Extrai e trata o campo entrada_CC
entrada_CC = dsd.extrair(html_CC,
'Distribuído:</td><td><strong>',
'</strong>').upper()
### Remove acentos
entrada_CC = dsd.remover_acentos(entrada_CC)
entrada_CC = entrada_CC.replace('-','/')
entrada_CC = dsd.ajustar_mes(entrada_CC)
## Extrai e trata o campo relator_CC
relator_CC = dsd.extrair(html_CC,
'Relator:</td><td><strong>',
'</strong>').upper()
### Remove acentos
relator_CC = dsd.remover_acentos(relator_CC)
### Exclui o trecho MINISTRO/A e variações
relator_CC = relator_CC.replace('MINISTRO','')
relator_CC = relator_CC.replace('MINISTRA','')
relator_CC = relator_CC.replace('MIINISTRO','')
relator_CC = relator_CC.replace('MIMISTRO','')
relator_CC = relator_CC.replace('MININISTRO','')
## Extrai e trata o campo requerente_CC
requerente_CC = dsd.extrair(html_CC,
'Requerente: <strong>',
'</strong>').upper()
### Remove acentos
requerente_CC = dsd.remover_acentos(requerente_CC)
### Corrige dados fora do padrão
requerente_CC = requerente_CC.replace('103 ','103,')
requerente_CC = requerente_CC.replace('103 ','103.')
### Extrai o inciso com o tipo do requerente
if '103,' in requerente_CC:
requerente_CC = requerente_CC.split('103,')[1]
else:
requerente_CC = 'NA'
### limpa o tipo do requerente
requerente_CC = dsd.limpar(requerente_CC)
requerente_CC = requerente_CC.replace('0','')
requerente_CC = requerente_CC.replace(',','')
requerente_CC = requerente_CC.replace('2','')
requerente_CC = requerente_CC.replace('CF','')
requerente_CC = requerente_CC.replace('(','')
requerente_CC = requerente_CC.replace(')','')
requerente_CC = requerente_CC.strip('O')
requerente_CC = dsd.limpar(requerente_CC)
requerente_CC = requerente_CC.split(' ')[0]
# Converte o campo requerente em tipo de requerente
requerente_tipo_CC = requerente_CC
## Extrai e trata o campo dispositivo_CC
dispositivo_CC = dsd.extrair(html_CC,
'Legal Questionado</b></strong><br /><pre>',
'</pre>')
# Extrai e trata o campo fundamento_CC
fundamento_CC = dsd.extrair(html_CC,
'Constitucional</b></strong><br /><pre>',
'</pre>').upper()
### Remove acentos
fundamento_CC = dsd.remover_acentos(fundamento_CC)
# Limpa o campo
fundamento_CC = fundamento_CC.replace('- ART','ART')
fundamento_CC = fundamento_CC.strip('\n')
# Gera lista de fundamentos
fundamento_CC = fundamento_CC.split('\n')
## Extrai e trata o campo resultado_liminar_CC
resultado_liminar_CC = dsd.extrair(html_CC,
'Resultado da Liminar</b></strong><br /><br />',
'<br />').upper()
### Remove acentos
resultado_liminar_CC = dsd.remover_acentos(resultado_liminar_CC)
### Define campo para identificar decisões monocráticas
orgao_liminar_CC = 'NA'
### Corrige dados fora do padrão
resultado_liminar_CC = resultado_liminar_CC.replace('MONOACRATICA',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('MONICRATICA',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('MONOCRATICO',
'MONOCRATICA')
resultado_liminar_CC = resultado_liminar_CC.replace('LIMINAR ','')
### Gera campo órgão nos casos de decisão monocrática
if 'DECISAO MONOCRATICA - ' in resultado_liminar_CC:
resultado_liminar_CC = resultado_liminar_CC.replace(
'DECISAO MONOCRATICA -','')
resultado_liminar_CC = resultado_liminar_CC.replace(
'DECISAO MONOCRATICA ','')
orgao_liminar_CC = 'MONOCRATICA'
# Extrai e trata o campo resultado_final_CC
resultado_final_CC = dsd.extrair(html_CC,
'Resultado Final</b></strong><br /><br />',
'<br />').upper()
### Remove acentos
resultado_final_CC = dsd.remover_acentos(resultado_final_CC)
### Define o campo orgao
orgao_resultado_final_CC = 'NA'
### Corrige dados fora do padrão
resultado_final_CC = resultado_final_CC.replace('MONOCRATICO',
'MONOCRATICA')
### Gera campo orgao
if 'DECISAO MONOCRATICA - ' in resultado_final_CC:
resultado_final_CC = resultado_final_CC.replace(
'DECISAO MONOCRATICA -','')
orgao_resultado_final_CC = 'MONOCRATICA'
# Extrai e trata o campo monocratica_final_CC
monocratica_final_CC = dsd.extrair(html_CC,
'Decisão Monocrática Final</b></strong><br /><pre>',
'</pre>')
## Extrai e trata o campo indexacao_CC
indexacao_CC = dsd.extrair(html_CC,
'Indexação</b></strong><br /><pre>',
'</pre>').upper()
### Remove acentos
indexacao_CC = dsd.remover_acentos(indexacao_CC)
### Cria o campo prevenção
prevencao_CC = 'NA'
### Limpa o campo indexação de textos indevidos
indexacao_CC = indexacao_CC.replace('<BR />','')
### Gera o dado sobre prevenção e adapta o campo indexação
if 'PREVENCAO' in indexacao_CC:
prevencao_CC = dsd.extrair(indexacao_CC, 'PREVENCAO - ', '\n')
indexacao_CC = dsd.extrair(indexacao_CC, prevencao_CC,'')
indexacao_CC = dsd.limpar(indexacao_CC)
# Define os dados a serem gravados
if incidente != 'NA' and incidente != '':
dados_processo = [processo,
incidente,
apensado_a,
lista_processos_apensados,
protocolo_data,
eletronico_fisico,
sigilo,
numerounico,
relator_IP,
relator_CC,
redator_acordao,
relator_ultimo_incidente,
ultimoincidente,
len(lista_das_partes),
lista_das_partes,
intdos,
orgaodeorigem,
origem_sigla,
origem_CC,
origem_ato,
data_ultimo_andamento,
len(andamentos),
andamentos[:10],
numerodeorigem,
pedido_de_liminar_CC,
entrada_CC,
requerente_tipo_CC,
assuntos,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC]
# Grava csv
print (f'Processando {processo}')
dsd.write_csv_header(arquivo,
'''processo,
incidente,
apensado_a,
lista_processos_apensados,
protocolo_data,
eletronico_fisico,
sigilo,
numerounico,
relator_IP,
relator_CC,
redator_acordao,
relator_ultimo_incidente,
ultimoincidente,
len(lista_das_partes),
lista_das_partes,
intdos,
orgaodeorigem,
origem_sigla,
origem_CC,
origem_ato,
data_ultimo_andamento,
len(andamentos),
andamentos[:10],
numerodeorigem,
pedido_de_liminar_CC,
entrada_CC,
requerente_tipo_CC,
assuntos,
fundamento_CC,
resultado_liminar_CC,
orgao_liminar_CC,
resultado_final_CC,
orgao_resultado_final_CC,
monocratica_final_CC,
indexacao_CC,
prevencao_CC''')
dsd.write_csv_row(arquivo,dados_processo)
# Grava o arquivo com os dispositivos legais impugnados
dsd.write_csv_header('dispositivos_CC.txt','processo,dispositivo')
dsd.write_csv_row('dispositivos_CC.txt',[processo,dispositivo_CC])
# Grava o arquivo com os andamentos
dsd.write_csv_header('STF_andamentos.txt','processo,andamentos')
dsd.write_csv_row('STF_andamentos.txt',[processo,andamentos])
# Grava mensagem de finalização do progama com êxito
print (f'Gravado arquivo {arquivo}')






